
This next post about data engineering patterns implemented came to my mind when I saw a question about applying custom partitioning on a not pair RDD. If you don't know, it's not supported and IMO one of the reasons for that comes from the dataset decomposition pattern implementation in Apache Spark.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post has 3 sections. In the first one, it explains dataset decomposition pattern idea. In the second one, it explains the first decomposition method implemented in Apache Spark whereas the third one contains the second available method.
Pattern definition
Decomposition pattern makes distributed processing possible. Its idea is straightforward. One dataset is stored on some data store. However, before starting the processing, this dataset is split and the divided parts are distributed among available processing nodes.
The splits are most often called partitions but other names like shards or chunks are used interchangeably. Since this concept is not hard to understand, let's go directly to 2 possible implementations of it.
Not partitionable source
The first implementation uses a data source that physically is not partitioned. It means that at the storage level, the data is not physically separated. An example of that kind of source are files. Don't get me wrong, you can partition a dataset and store each part in different files. But file by itself is a data source that doesn't have partitions internally. It means that Apache Spark cannot simply describe a file and say "hey ! I see that there are 3 partitions for this file so my maximal parallelization level will be 3". The framework needs another mechanism to figure this out.
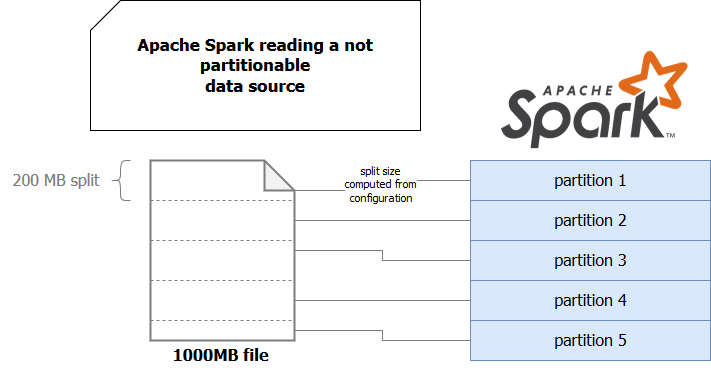
As you can see here, the source is stored on a single node as a whole. But even though, Apache Spark (or any other data processing framework) can work on its splits. How? Most of the time thanks to some configuration. Apache Spark SQL exposes an entry called spark.sql.files.maxPartitionBytes which defines the size of split in each partition.
But files are not a single not distributed data source that can be read in parallel by Apache Spark. A relational database is another one. Here once again some configuration is required before. The user must define a numeric column used as partitioning value, number of partitions, and lower and upper partition boundaries. With these properties Apache Spark SQL can divide not partitionable dataset into multiple partitions and process it parallel.
Partitionable source
The second category of sources are the ones I called here "partitionable". The main difference with not partitionable is that they are naturally partitioned. It means that the datastore is composed of one or multiple partitions and data processing framework can map them 1 to 1 to its internal partitioning logic. A great example of such data source is Apache Kafka. This streaming broker stores data in a structure called topic which is divided into multiple partitions. Thanks to that any data processing framework can, by simply analyzing the structure of the topic, deduce which partitions should be taken.
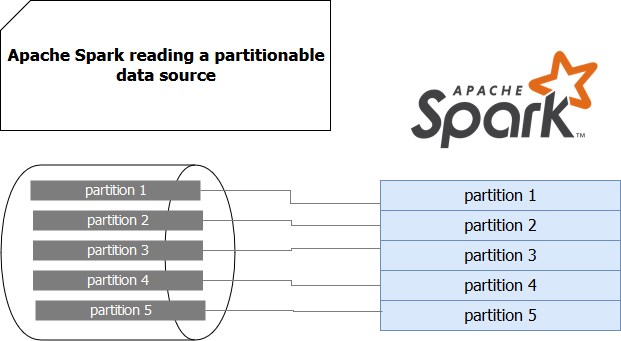
The image is quite simplistic, so let's deep delve into Apache Spark Structured Streaming source code to see how concretely the framework resolves Apache Kafka partitions. On the driver side, Apache Spark creates an Apache Kafka consumer, just to discover the topology of processed topics. And the partitions are retrieved directly through Apache Kafka's consumer API:
def fetchTopicPartitions(): Set[TopicPartition] = runUninterruptibly {
assert(Thread.currentThread().isInstanceOf[UninterruptibleThread])
// Poll to get the latest assigned partitions
consumer.poll(0)
val partitions = consumer.assignment()
consumer.pause(partitions)
partitions.asScala.toSet
}
Which is called when Structured Streaming resolves offsets:
private def getPartitionOffsets(
kafkaReader: KafkaOffsetReader,
kafkaOffsets: KafkaOffsetRangeLimit): Map[TopicPartition, Long] = {
val partitions = kafkaReader.fetchTopicPartitions()
// Obtain TopicPartition offsets with late binding support
kafkaOffsets match {
case EarliestOffsetRangeLimit => partitions.map {
case tp => tp -> KafkaOffsetRangeLimit.EARLIEST
}.toMap
case LatestOffsetRangeLimit => partitions.map {
case tp => tp -> KafkaOffsetRangeLimit.LATEST
}.toMap
case SpecificOffsetRangeLimit(partitionOffsets) =>
validateTopicPartitions(partitions, partitionOffsets)
}
}
Dataset decomposition pattern is one of the basics of modern distributed data processing. The idea is simple - split one big dataset into multiple parts most of the time called partitions to enable parallel and distributed computing. In the post, I presented 2 strategies to deal with this pattern. In the former one, the dataset is not naturally partitionable but as you saw, modern data processing frameworks can deal with this situation with some hints of the user. The latter strategy concerns partitionable data sources and here the user's implication is weaker since the framework can decompose dataset by itself.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Data Engineering Design Patterns: Hybrid continuous consumer
- Get it once, few words on data deduplication patterns in data engineering
- Good to know if you merge - reprocessing challenges
That has been a long time since I didn't write about #data engineering patterns. Today I published a post in this category about dataset decomposition which is the backbone of data processing frameworks https://t.co/X6yGZlOcsp
— Bartosz Konieczny (@waitingforcode) August 18, 2019