
This blog post completes the data duplication problem I covered in my recent Data Engineering Design Patterns book by approaching the issue from a different angle.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
But before we see the technical side of the problem, let's try to answer the Why. Why do we get duplicates? Why should we bother? The main reason for getting duplicated records are data producer problems, such as:
- Retries at the job, task retries, or the data writer instance level. Here depending on the retry level you can get very little or a lot of duplicates. The worst case is when your whole job restarts just because it didn't notify the data orchestration layer about the successful execution. In that case, the job will write the processed dataset again.
- User actions. Raise your hand if you have never clicked a button on a website or mobile app more than once. You did it probably because the user interface didn't respond fast enough so you thought there is an issue between your action and the provided technical interface.
- Backfillings. If you haven't designed your workflows correctly, even a simple backfilling demand can introduce duplicates.
- Data processing errors. The duplicates can also be your own fault. If your data processing logic does some risky operations on non duplicates records, such as LEFT JOIN, you can also end up with duplicates. Why LEFT JOIN specifically? Imagine that your main (left) dataset doesn't have duplicates but your joined (right) dataset does. In that case, the output will contain the records from your main dataset duplicates, as shows the next schema:
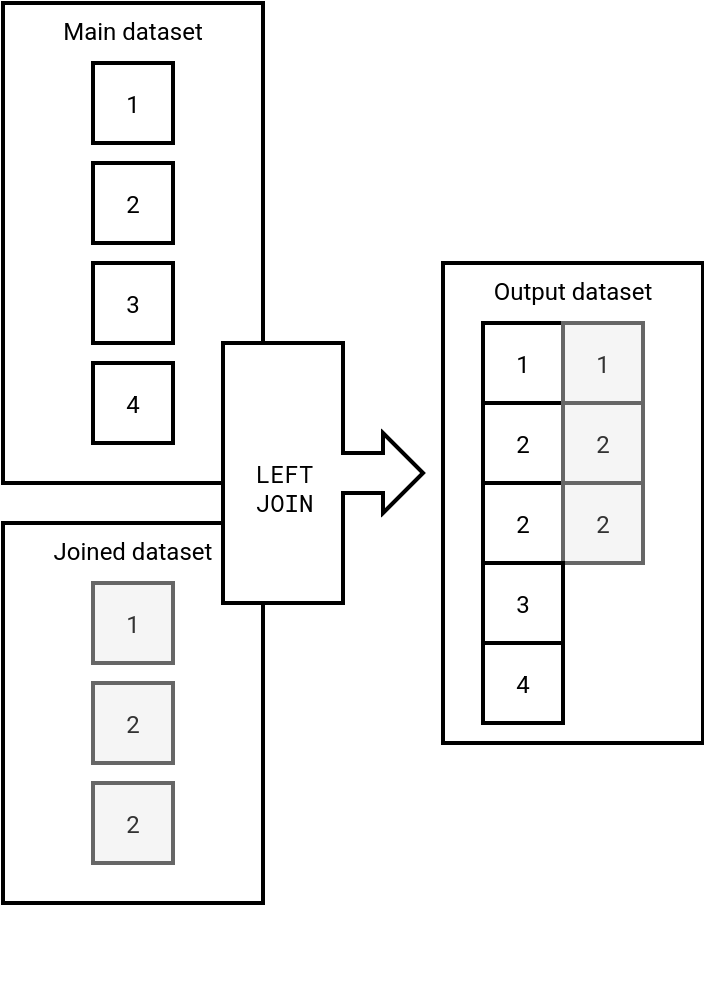
As you can notice here, row number 2, despite being present only once on the main dataset, was duplicated because of the LEFT JOIN semantics and duplicates in the joined datasets.
Before we go to the solutions, two questions remain to answer. The first is, how to define the duplicate? A pretty easy definition would be "every record that is present many times in the dataset". But it doesn't apply to the User actions reason. After all, when a user clicks twice on a button, there is a slight difference in the event time and technically, the records won't be identical. However, they will represent the same action that you may consider identical or just similar.
Finally, the last question is about time. Do you look for duplicates only within a predefined space, such as one partition, or globally, for example in the whole table independently on the partition?
Having all this context set, it's time to see the patterns addressing duplicated data.
Idempotency
The first technical answer to the duplicates problem comes with one of my favorite data engineering principles, the idempotency. As a reminder, idempotency guarantees the results written exactly once, no matter how many times you execute a pipeline or job. Naturally, the outcome will be your processed results written without duplicates.
How to implement idempotent pipelines is a whole new story I dedicated a full chapter in Data Engineering Design Patterns. You should find some answers there by using Fast metadata cleaner, Data overwrite, or both kinds of Merger patterns!
In addition to them, there are other - simpler - solutions, you could use, this time detailed in the blog post ;)
Simple deduplicator
Unfortunately, idempotency is only the pillar of getting data only once. If your processed dataset has already duplicates, you will have to complete the idempotent part with the patterns acting on the input data. The first of them is the Deduplicator which groups identical rows and keeps only one record from each group. An implementation example is the following SQL query:
SELECT DISTINCT lower_letter, upper_letter FROM letters
Once executed, it will return all unique pairs of lower_letter and upper_letter columns, as shown in the next demo:
letters = spark.createDataFrame([{'lower_letter': 'a', 'upper_letter': 'A'},
{'lower_letter': 'b', 'upper_letter': 'B'}, {'lower_letter': 'a', 'upper_letter': 'A'},
{'lower_letter': 'c', 'upper_letter': 'C'}], 'lower_letter STRING, upper_letter STRING')
letters.createOrReplaceTempView('letters')
spark.sql('''
SELECT DISTINCT lower_letter, upper_letter FROM letters
''').show(truncate=False)
+------------+------------+
|lower_letter|upper_letter|
+------------+------------+
|a |A |
|b |B |
|c |C |
+------------+------------+
But with this approach one problem remains, how to apply some deduplication logic? The deduplication logic is useful when you need to decide what occurrence of the duplicated record should be promoted to your system.
Custom deduplication
To understand the purpose of the second pattern addressing duplicates problem, let's use the already quoted example of a user who clicked on a button twice. To get this action only once we could use the Deduplicator pattern but what if we needed to add some logic and, for example, return the occurrence that happened last? In that situation a better alternative is the custom deduplication that can support additional deduplication logic. Let's take a look at the query that takes all last occurrences of the duplicated records:
SELECT lower_letter, upper_letter, event_time FROM (
SELECT
lower_letter, upper_letter, event_time,
ROW_NUMBER() OVER (PARTITION BY upper_letter, lower_letter ORDER BY event_time ASC) as row_number
FROM letters
) WHERE row_number = 1
When applied to some data, the custom deduplication could look like in the following code that gets the oldest record from the duplicates group:
letters = spark.createDataFrame([
{'lower_letter': 'a', 'upper_letter': 'A', 'event_time': datetime.datetime(2025, 12, 29)},
{'lower_letter': 'b', 'upper_letter': 'B', 'event_time': datetime.datetime(2025, 12, 30)},
{'lower_letter': 'a', 'upper_letter': 'A', 'event_time': datetime.datetime(2025, 12, 30)},
{'lower_letter': 'c', 'upper_letter': 'C', 'event_time': datetime.datetime(2025, 12, 30)}
], 'lower_letter STRING, upper_letter STRING, event_time TIMESTAMP')
letters.createOrReplaceTempView('letters')
spark.sql('''
SELECT lower_letter, upper_letter, event_time
FROM (
SELECT
lower_letter,
upper_letter,
event_time,
ROW_NUMBER() OVER (PARTITION BY upper_letter, lower_letter ORDER BY event_time ASC) as row_number
FROM
letters
)
WHERE row_number = 1
''').show(truncate=False)
+------------+------------+-------------------+
|lower_letter|upper_letter|event_time |
+------------+------------+-------------------+
|a |A |2025-12-29 00:00:00|
|b |B |2025-12-30 00:00:00|
|c |C |2025-12-30 00:00:00|
+------------+------------+-------------------+
Scoped deduplication
Finally, you can also face the duplicates problem with some scope limitations. A great example here are streaming jobs that represent an iterative view of the dataset. In that case, interacting with the whole dataset to identify duplicates can be inefficient from the compute standpoint. For that reason, the deduplication is limited in time and works in time-based windows that rely on the watermark:
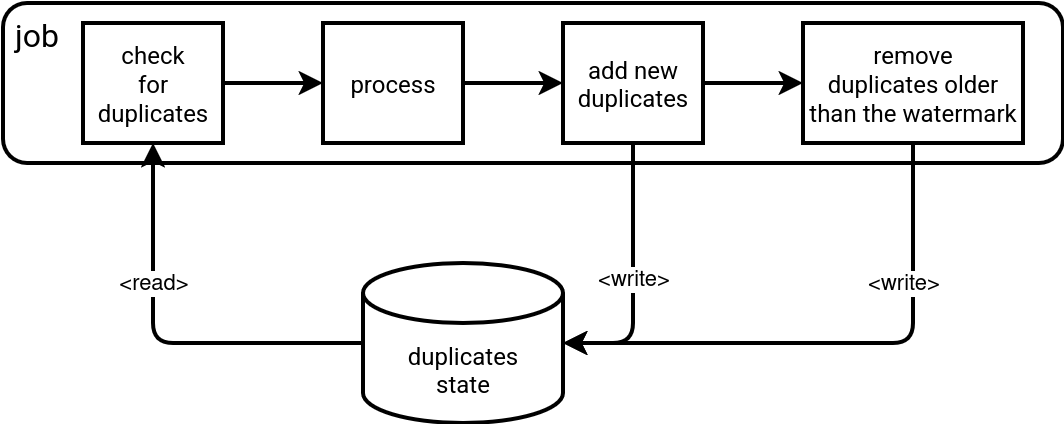
As you can see in the schema, the job starts by removing duplicated records within the watermark from the processing scope. Next, it adds all processed pairs to prevent them from being reprocessed in the future. Finally, the job cleans all stored pairs that fall behind the watermark. The last action highlights the scoped character of this deduplication.
An important thing to know is that the watermark prevents all too old records from being processed, even though they had never been part of the duplicates state. It can be understood like: the watermark defines the deduplication scope, consequently, it also specifies how long it can check for duplicates. If a record falls behind the watermark, it's beyond the deduplication scope.
Yet again, a proof in the code where the Row(visit_id=100, event_time=event_time(10)) record is ignored because of the watermark scope, even though it wasn't processed:
spark.dataSource.register(InMemoryDataSource)
input_data_stream = spark.readStream.format('in_memory').load()
deduplicated_visits = (input_data_stream
.withWatermark('event_time', '10 minutes')
.dropDuplicates(['visit_id', 'event_time']))
write_data_stream = (deduplicated_visits.writeStream#.trigger(availableNow=True)
.outputMode('update').format('console'))
write_data_query = write_data_stream.start()
def event_time(minutes: int):
return f'2025-10-20T09:{minutes}:00.000Z'
InMemoryDataSourceStreamHolder.write_records([Row(visit_id=1, event_time=event_time(10)).asDict(),
Row(visit_id=2, event_time=event_time(10)).asDict()])
write_data_query.processAllAvailable()
print(f'Watermark is: {write_data_query.lastProgress["eventTime"]["watermark"]}')
InMemoryDataSourceStreamHolder.write_records([Row(visit_id=1, event_time=event_time(10)).asDict(),
Row(visit_id=2, event_time=event_time(25)).asDict()])
write_data_query.processAllAvailable()
print(f'Watermark is: {write_data_query.lastProgress["eventTime"]["watermark"]}')
InMemoryDataSourceStreamHolder.write_records([Row(visit_id=1, event_time=event_time(10)).asDict(),
Row(visit_id=100, event_time=event_time(10)).asDict(),
Row(visit_id=3, event_time=event_time(26)).asDict()])
write_data_query.processAllAvailable()
print(f'Watermark: {write_data_query.lastProgress["eventTime"]["watermark"]}')
-------------------------------------------
Batch: 0
-------------------------------------------
+--------+-------------------+
|visit_id| event_time|
+--------+-------------------+
| 1|2025-10-20 09:10:00|
| 2|2025-10-20 09:10:00|
+--------+-------------------+
-------------------------------------------
Batch: 1
-------------------------------------------
+--------+----------+
|visit_id|event_time|
+--------+----------+
+--------+----------+
Watermark is: 2025-10-20T09:00:00.000Z
Saving [{'visit_id': 1, 'event_time': '2025-10-20T09:10:00.000Z'}, {'visit_id': 2, 'event_time': '2025-10-20T09:25:00.000Z'}]
-------------------------------------------
Batch: 2
-------------------------------------------
+--------+-------------------+
|visit_id| event_time|
+--------+-------------------+
| 2|2025-10-20 09:25:00|
+--------+-------------------+
-------------------------------------------
Batch: 3
-------------------------------------------
+--------+----------+
|visit_id|event_time|
+--------+----------+
+--------+----------+
Watermark is: 2025-10-20T09:15:00.000Z
Saving [{'visit_id': 1, 'event_time': '2025-10-20T09:10:00.000Z'}, {'visit_id': 100, 'event_time': '2025-10-20T09:10:00.000Z'}, {'visit_id': 3, 'event_time': '2025-10-20T09:26:00.000Z'}]
-------------------------------------------
Batch: 4
-------------------------------------------
+--------+-------------------+
|visit_id| event_time|
+--------+-------------------+
| 3|2025-10-20 09:26:00|
+--------+-------------------+
-------------------------------------------
Batch: 5
-------------------------------------------
+--------+----------+
|visit_id|event_time|
+--------+----------+
+--------+----------+
As you can see, deduplication may have many flavors, depending on the duplicates you deal with and the data processing semantics your logic must implement. If you can deal with simple duplicates, a native DISTINCT operator should be enough. Otherwise, a more complex query, possibly with the WINDOW function or a grouping logic followed by a custom mapping, should be considered. And if you work in streaming, you should also keep in mind the deduplication scope to avoid running out of resources. Finally, if you can deal with approximates, there are probabilistic data structures such as Bloom filters. I blogged about Bloom filters in 2018.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩