
Some time ago I wrote a blog post about output invalidation pattern using immutable time-based tables. Today, even though I planned to start to explore new ACID-compliant file formats only by the end of this year, I decided to cheat a little (curiosity beat me) and try to adapt the pattern to one of these formats and use time travel feature to guarantee data consistency.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
I will start this post by introducing the idea of time travel. In the next parts, I will explain why I was wrong about the way of working of versions in Delta Lake. In the last part, I will show the code that, despite my initial wrong assumptions, handles output invalidation pattern with the help of versions.
Time travel to guarantee consistency
In simple terms, time travel feature works like a seek in a file - you can move to any written position. Time travel in modern ACID-compliant (BTW, I'm looking for a better category name for them, please leave the comment) file formats like Delta Lake means the same thing. Every time you write something, a new version of your system is created. In case of any problem, you can move back to the last good version simply like that:
override def beforeAll(): Unit = {
FileUtils.deleteDirectory(new File(outputPath))
(0 to 10).foreach(nr => {
val dataset = Seq((nr)).toDF("nr")
dataset.write.format("delta").mode(SaveMode.Append).save(outputPath)
})
}
"version attribute" should "be used to retrieve past view of the data" in {
// Let's get the dataset at its 3rd version
val datasetVersion3 = testedSparkSession.read.format("delta")
.option("versionAsOf", "3").load(outputPath)
.map(row => row.getAs[Int]("nr")).collect()
datasetVersion3 should have size 4
datasetVersion3 should contain allOf(1, 2, 3, 4)
}
In addition to that, you can also move back with timestamps. Every version has a timestamp associated, as you can see in the following snippet:
"timestamp" should "be associated to the version as processing time" in {
val deltaTable = DeltaTable.forPath(testedSparkSession, outputPath)
val fullHistoryDF = deltaTable.history()
val deltaVersions = fullHistoryDF.map(row => row.getAs[Timestamp]("timestamp").toString).collect()
deltaVersions.foreach(timestamp => timestamp should not be empty)
// assert only on date to avoid hour issues (eg. versions written between xx:59 and yy:01)
val expectedVersionDate = LocalDate.now.toString
deltaVersions.foreach(timestamp => timestamp should startWith(expectedVersionDate))
}
Unfortunately, the timestamp is not always easy to retrieve. Let's take an example of an hourly-based batch running Apache Spark SQL. In normal circumstances, every execution takes 10 minutes and since it's hourly-based, using a timestamp to figure out the corresponding version simply works.
On the other hand, what happens if you reprocess your data? First, you will not wait one hour before launching the reprocessing job. Instead of that, you will want to process data as soon as possible, so every 10 minutes - if we suppose that the Spark job is the single one in our pipeline. In that case, figuring out the version from the processing time (timestamp is the processing time) is a little bit tricky. But no worries, in the next sections I will show you how to enhance Apache Airflow's DAG to compute a correct version and manage data rollbacks with Delta Lake versions.
How I thought it works
But before that, I had to add this and the following parts, just to highlight the fact that it wasn't as easy as I expected. When I saw the versions my first reflex was to think about them like about partitions.
In other words, I thought that loading data from one version (v) and changing it was equal to writing a completely new dataset identified by the next version (v+1). However, it's not how it works.
How it really works
In reality, the versions in Delta Lake work differently - and it's logical if you consider your dataset as an immutable component. When you load a version (v where v != the last v in the table) and you make some changes, Delta Lake will not write the version number v+1 but rather the last version + 1.
Below you can find a table that was initially created and after modified twice starting from version 2. I thought to be able to use readVersion column to retrieve the last changes for given version but it won't work neither because it's incremented at every change:
+-------+-------------------+------+--------+---------+-----------------------------------+----+--------+---------+-----------+--------------+-------------+ |version|timestamp |userId|userName|operation|operationParameters |job |notebook|clusterId|readVersion|isolationLevel|isBlindAppend| +-------+-------------------+------+--------+---------+-----------------------------------+----+--------+---------+-----------+--------------+-------------+ |11 |2020-02-29 16:56:51|null |null |WRITE |[mode -> Append, partitionBy -> []]|null|null |null |10 |null |true | |10 |2020-02-29 16:45:33|null |null |WRITE |[mode -> Append, partitionBy -> []]|null|null |null |9 |null |true | |9 |2020-02-29 16:45:03|null |null |WRITE |[mode -> Append, partitionBy -> []]|null|null |null |8 |null |true | |8 |2020-02-29 16:44:51|null |null |WRITE |[mode -> Append, partitionBy -> []]|null|null |null |7 |null |true | |7 |2020-02-29 16:44:40|null |null |WRITE |[mode -> Append, partitionBy -> []]|null|null |null |6 |null |true | |6 |2020-02-29 16:44:29|null |null |WRITE |[mode -> Append, partitionBy -> []]|null|null |null |5 |null |true | |5 |2020-02-29 16:44:19|null |null |WRITE |[mode -> Append, partitionBy -> []]|null|null |null |4 |null |true | |4 |2020-02-29 16:44:07|null |null |WRITE |[mode -> Append, partitionBy -> []]|null|null |null |3 |null |true | |3 |2020-02-29 16:43:54|null |null |WRITE |[mode -> Append, partitionBy -> []]|null|null |null |2 |null |true | |2 |2020-02-29 16:43:45|null |null |WRITE |[mode -> Append, partitionBy -> []]|null|null |null |1 |null |true | |1 |2020-02-29 16:43:36|null |null |WRITE |[mode -> Append, partitionBy -> []]|null|null |null |0 |null |true | |0 |2020-02-29 16:43:19|null |null |WRITE |[mode -> Append, partitionBy -> []]|null|null |null |null |null |true | +-------+-------------------+------+--------+---------+-----------------------------------+----+--------+---------+-----------+--------------+-------------+
That's the reason why my initial conception about this pattern won't work - or at least, it won't work without some extra cleaning effort. Hopefully, I found this question on StackOverflow that proven me that I was not alone in my thinking and that maybe there is a "hacky" solution.
Airflow DAG and Spark application - hacky version
Since I didn't want to break Delta Lake, so not manually clean the log files as stated in the quoted question, I opted for another solution. I will map the version expected by my Apache Airflow DAG to the version written by Delta Lake. The application logic looks like that:
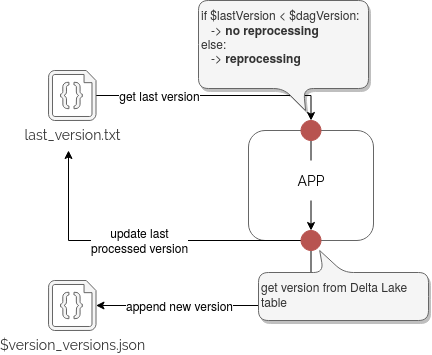
The code responsible for that looks like :
val logsDir = "/tmp/output_invalidation_patterns/time_travel/delta_lake"
val airflowVersionToWrite = args(0).toLong
val lastWrittenAirflowVersion = AirflowVersion.lastVersion.getOrElse(-1L)
val TestedSparkSession: SparkSession = SparkSession.builder()
.appName("Delta Lake time travel with Airflow").master("local[*]").getOrCreate()
import TestedSparkSession.implicits._
val (previousDataset, saveMode) = if (lastWrittenAirflowVersion < airflowVersionToWrite) {
(None, SaveMode.Append)
} else {
// We're backfilling, so get the last written Delta Lake version for
// given Airflow version
val versionToRestore = airflowVersionToWrite - 1
val deltaVersionForAirflow = AirflowVersion.deltaVersionForAirflowVersion(versionToRestore)
println(s"Backfilling from Airflow version=${versionToRestore} which uses ${deltaVersionForAirflow} Delta Lake version")
(
Some(
TestedSparkSession.read.format("delta").option("versionAsOf", deltaVersionForAirflow).load(logsDir)
), SaveMode.Overwrite
)
}
val newDataset = Seq(
(s"v${airflowVersionToWrite}-${userValue}")
).toDF("user_id")
val datasetToWrite = previousDataset.map(previousData => previousData.union(newDataset))
.getOrElse(newDataset)
println("Writing dataset")
datasetToWrite.show(false)
datasetToWrite.write.format("delta").mode(saveMode).save(logsDir)
def getLastWrittenDeltaLakeVersion = {
val deltaTable = DeltaTable.forPath(TestedSparkSession, logsDir)
val maxVersionNumber = deltaTable.history().select("version")
.agg(Map("version" -> "max")).first().getAs[Long](0)
maxVersionNumber
}
val lastWrittenDeltaVersion = getLastWrittenDeltaLakeVersion
AirflowVersion.writeDeltaVersion(airflowVersionToWrite, lastWrittenDeltaVersion)
object AirflowVersion {
private val DirPrefix = "/tmp/time_travel6"
private val LastVersionFile = new File(s"${DirPrefix}/last_version.txt")
def lastVersion = {
if (LastVersionFile.exists()) {
Some(FileUtils.readFileToString(LastVersionFile).toLong)
} else {
None
}
}
def deltaVersionForAirflowVersion(airflowVersion: Long): Long = {
// No need to check the file's existence. We suppose to call this
// method only for the backfilling scenario. Not having the check helps to
// enforce this constraint
FileUtils.readFileToString(versionFile(airflowVersion)).toLong
}
def writeDeltaVersion(airflowVersion: Long, deltaVersion: Long) = {
FileUtils.writeStringToFile(LastVersionFile, airflowVersion.toString)
// We make simple and store only the last DL version
FileUtils.writeStringToFile(versionFile(airflowVersion), deltaVersion.toString)
}
private def versionFile(airflowVersion: Long) = new File(s"${DirPrefix}/${airflowVersion}.txt")
}
Of course, the fact of using union can be problematic because unlike "normal" run, it will require the hardware able to process much more data than usual (any better idea is welcome). Nonetheless, that's the idea of this "hacky" solution. Regarding the Apache Airflow DAG, there are fewer "hacks". A DAG will be, most of the time, triggered at a regular schedule, like every hour. It also has to start on a specific date. Every time the execution is triggered, we talk about a DAG run instance and every instance has associated properties, like the execution date and processing time. Thanks to all these elements we can easily figure out the version needed by our Apache Spark code dealing with Delta Lake tables. This method, executed as a PythonOperator, show it pretty clearly:
dag = DAG(
dag_id='output_invalidation_pattern_time_travel',
schedule_interval=timedelta(hours=1),
start_date=pendulum.datetime(2020, 1, 1, 0, 0, 0),
catchup=True,
max_active_runs=1
)
with dag:
def generate_version_name(**context):
execution_date = context['execution_date']
delta_lake_version_to_restore = (execution_date - dag.start_date).total_seconds() / dag.schedule_interval.total_seconds()
return delta_lake_version_to_restore
delta_lake_version_to_restore = hours_difference
return delta_lake_version_to_restore
version_getter = PythonOperator(
task_id='version_getter',
python_callable=generate_version_name,
provide_context=True
)
def submit_spark_job(**context):
# It's only a dummy implementation to show how to retrieve
# the version.
version_to_pass = context['ti'].xcom_pull(key=None, task_ids='version_getter')
print('Got version {}'.format(version_to_pass))
return 'spark-submit .... {}'.format(version_to_pass)
spark_job_submitter = PythonOperator(
task_id='spark_job_submitter',
python_callable=submit_spark_job,
provide_context=True
)
version_getter >> spark_job_submitter
Naturally, the above maths are very basic since our DAG is hourly-based and starts at midnight, so we can simply divide its execution time by the schedule interval. Maybe for your prod use case, you will need a more complicated rule but that's the idea. The goal is later to pass this version number to our Apache Spark SQL application and override the version if it exists.
I will now demonstrate how this code is performing, separately from Apache Airflow to keep things simple:
Despite the fact of working correctly, I have a feeling that it's still overcomplicated for what it has to do. Maybe simply the versions are not a good fit, especially with my union in the processing? I will certainly go back to this topic by the end of the year. Meantime, if you have already used time travel to do similar things, please leave a comment. I, and hope that other readers, will be happy to learn from you!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Output invalidation pattern with time travel here:
Related blog posts:
- Data Engineering Design Patterns: Hybrid continuous consumer
- Get it once, few words on data deduplication patterns in data engineering
- Good to know if you merge - reprocessing challenges
I didn't plan it but couldn't resist to play a little with #ApacheSpark #ApacheAirflow and #DeltaLake and try to adapt output invalidation patterns to the time-travel https://t.co/tCVXhphkg2
— Bartosz Konieczny (@waitingforcode) April 4, 2020