
Your data won't always tell you all the things. Often you will be missing some additional and important context. Whether the data come from a backfilling run? Whether the data was generated from the most recent job version you deployed? All those questions can be answered with the Delta Lake feature called user metadata.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
User metadata default
The first method to configure the user metadata is to use a SparkSession property called spark.databricks.delta.commitInfo.userMetadata. When you do this, all Delta Lake writers executed within this SparkSession will decorate their commits with the metadata you configured. Below you can see how this SparkSession's property gets retrieved while Delta Lake commits a transaction:

An important thing to notice here is the scope. SparkSession's user metadata applies to all operations that create a commit; to put it short, to everything you do with your Delta Lake table. That way you can even decorate technical tasks, such as VACUUM or OPTIMIZE:
sparkSession.conf.set("spark.databricks.delta.commitInfo.userMetadata",
"""
|{"source": "demo5", "job_version": "v1", "context": "regular_optimize"}
|""".stripMargin.trim())
DeltaTable.forName("demo5").optimize().executeCompaction()
User metadata and batch writer
The drawback of the SparkSession-based solution is the scope. So defined user metadata applies to all actions within the session. Thankfully, Delta Lake offers an isolated approach too. Whenever you want to use different user metadata per Delta writer, you can configure it via userMetadata property, like in the following example:
sparkSession.read.table("demo2_src").write.format("delta").option("userMetadata",
"""
|{"source": "demo1", "job_version": "v1", "context": "normal_writer"}
|""".stripMargin).mode(SaveMode.Append).saveAsTable("demo2_target")
sparkSession.read.table("demo2_src").write.format("delta").option("userMetadata",
"""
|{"source": "demo1", "job_version": "v2", "context": "normal_writer"}
|""".stripMargin).mode(SaveMode.Append).saveAsTable("demo2_target")
The execution follows the SparkSession-based approach except that the commit won't take the default configuration if you specify the writing option:
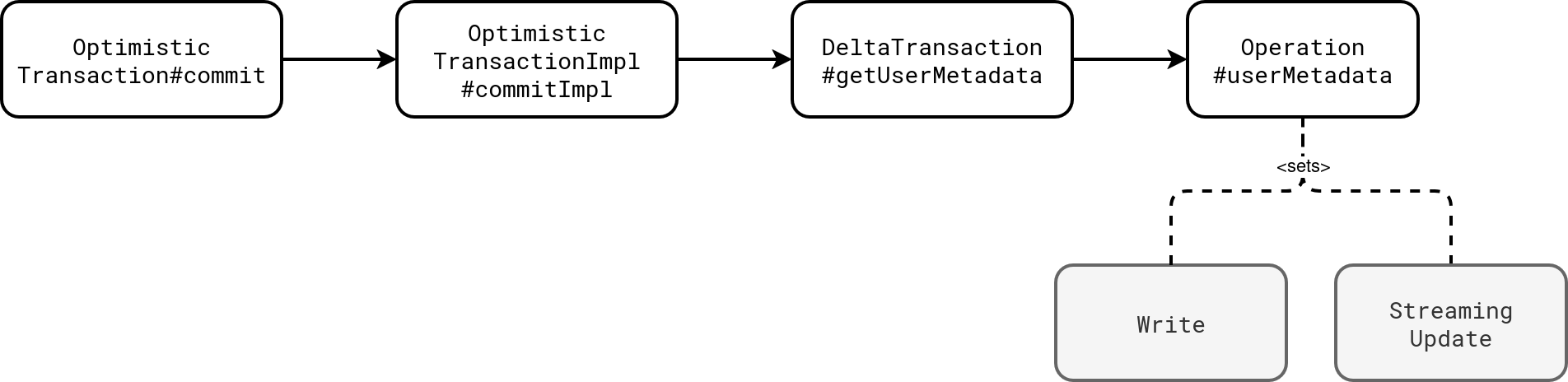
Unlike the SparkSession-based solution, the option-based approach only works for the explicit writing operations such as dataframe.write.format("delta")... or streamingDataframe.writeStream.format("delta")....
User metadata and streaming writer
BTW, there is a different limitation for streaming writers. The user metadata is static. Put differently, for the following code the value of the random field will always be set to the value generated after the first call of the getRandomNumber:
def getRandomNumber() = Random.nextInt(50)
val query = rateStreamInput.writeStream
.format("delta")
.option("userMetadata", s"writer=streaming,version=v1,random=${getRandomNumber()}")
.toTable("demo4")
User metadata and OPTIMIZE
Finally, the last point I wanted to share here is about the OPTIMIZE operation. From the first section you know the userMetadata is per commit and that you can even decorate housekeeping operations, including the OPTIMIZE!
When I first heard about the userMetadata feature, I thought it only applied to writers. As a result, I assumed that any OPTIMIZE operation would also merge the userMetadata created from the compacted commits. Now I know that's not the case.
Long story short, do not underestimate the power of the metadata. It helps brings additional context to your work with Delta Lake tables that can be useful to understand the data generation environment.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩