
When I was writing the Data Engineering Design Patterns book I had to leave some great suggestions aside. One of them was a code snippet for the Passthrough replicator pattern with Delta Lake's clone feature. But all is not lost as my new Delta Lake blog post will focus on table cloning which is the backbone for implementing the Passthrough replicator pattern!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Before I delve into details, I owe you a few words of introduction for this Passthrough replicator pattern. The problem it tries to solve is data copy. In a data engineering life those data copies can be useful to perform isolated tests, to do some experimentations, or yet to stage your data before a writing operation on the copied table.
Depending on your storage technology there are many ways to implement the Passthrough replicator pattern. Sometimes they require physical data copy, while other times they are simple reference changes. Delta Lake supports both of these solutions via the features called deep clones and shallow clones.
Clone types
So, what's the difference between these two clone types? The data. The shallow clone doesn't touch the data files composing your Delta Lake table while the deep clone does. This difference already gives you a hint when to use each of these types:
- Since the shallow clone doesn't copy the data files, it's more vulnerable to any changes made on the underlying table, such as vacuuming. Therefore, if you need the clone to be always readable, it'll be safer to opt for the deep clone solution.
- On another hand, if you can allow some vacuum-based errors, a shallow clone is better because it doesn't have the files copy overhead.
The schema below explains these differences visually:
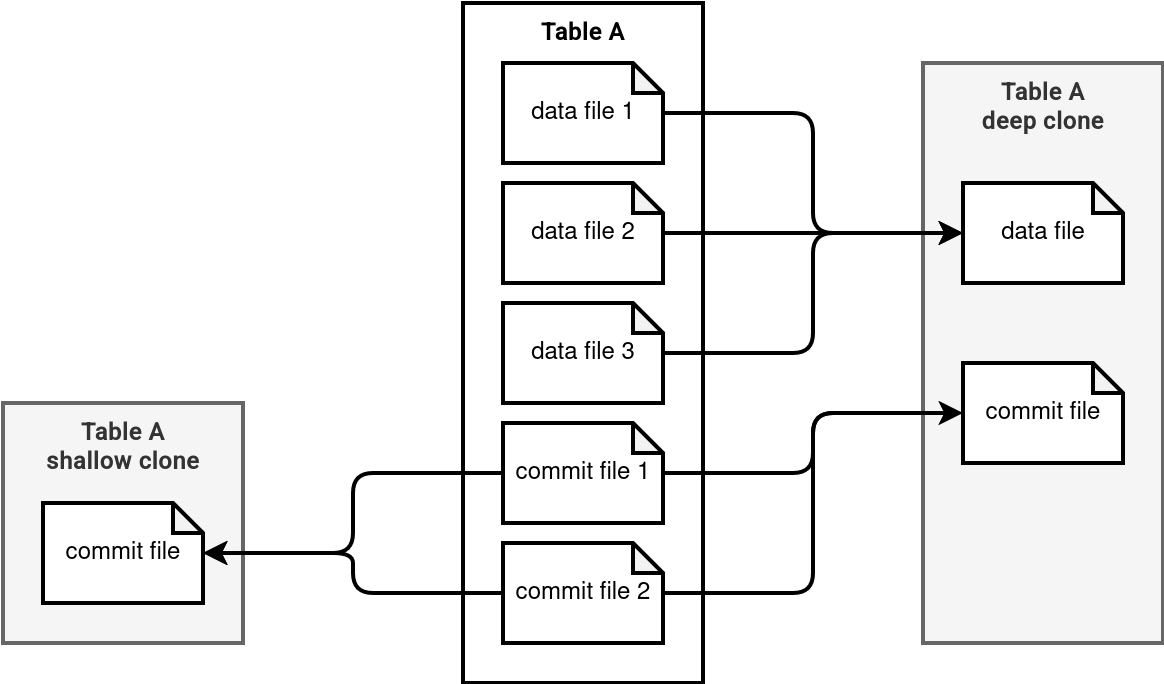
Another criteria for preferring the shallow clone over the deep clone is time. If the clone involves a reduced in time scenario, such as testing your data transformation on the production dataset, the shallow clone is better suited for that. In this scenario, you simply need to read the existing data and transform it without persisting the transformed dataset beyond the test execution's lifetime. There is also less risk the data files from the shallowly cloned become unavailable due to the compaction and vacuuming.
Shallow clone
From the schema presented above you can also see one important thing. The metadata clone doesn't involve the copy of all commit files. Instead of that, Delta Lake copies the metadata belonging to the most recent snapshot of the table. Put differently, the clone only takes the commit logs with still data active files. You can see this in another schema...
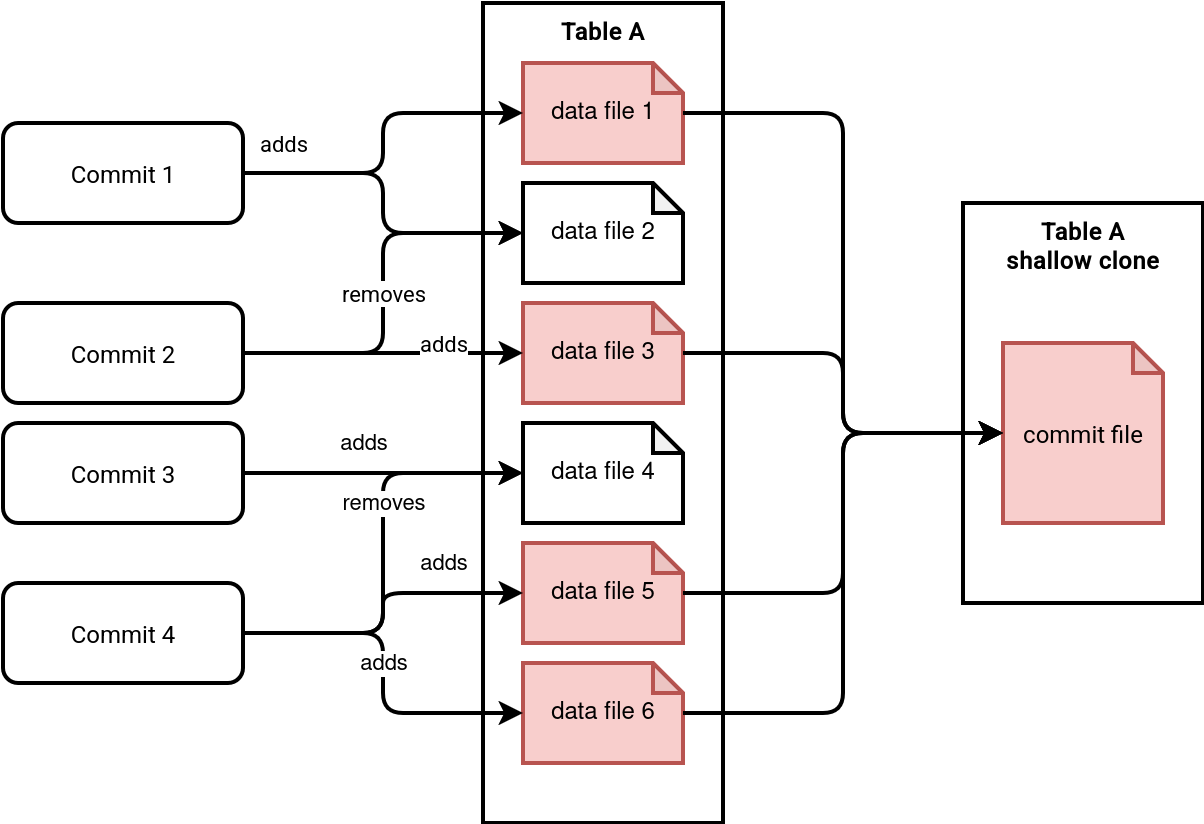
...or in the code responsible for selecting the files to clone:
class CloneDeltaSource(
sourceTable: DeltaTableV2) extends CloneSource {
// ...
private val deltaLog = sourceTable.deltaLog
private val sourceSnapshot = sourceTable.initialSnapshot
def allFiles: Dataset[AddFile] = sourceSnapshot.allFiles
// ...
abstract class CloneTableBase(sourceTable: CloneSource, tablePropertyOverrides: Map[String, String],targetPath: Path)
extends LeafCommand with CloneTableBaseUtils with SQLConfHelper {
// ...
protected def handleClone(spark: SparkSession, txn: OptimisticTransaction,
destinationTable: DeltaLog, hdpConf: Configuration,
deltaOperation: DeltaOperations.Operation, commandMetrics: Option[Map[String, SQLMetric]]): Seq[Row] = {
val addedFileList = {
val toAdd = sourceTable.allFiles
// absolutize file paths
handleNewDataFiles(deltaOperation.name, toAdd,
qualifiedSource, destinationTable).collectAsList()
}
val addFileIter = addedFileList.iterator.asScala
var actions: Iterator[Action] =
addFileIter.map { fileToCopy =>
val copiedFile = fileToCopy.copy(dataChange = dataChangeInFileAction)
// CLONE does not preserve Row IDs and Commit Versions
copiedFile.copy(baseRowId = None, defaultRowCommitVersion = None)
}
recordDeltaOperation(
destinationTable, s"delta.${deltaOperation.name.toLowerCase()}.commit") {
txn.commitLarge(
spark,
actions,
Some(newProtocol),
deltaOperation,
context,
commitOpMetrics.mapValues(_.toString()).toMap)
}
Deep clone
Deep clone is a feature fully available only on Databricks. The vanilla Delta Lake doesn't support it and the Feature Request created in 2022 is still open.
But if you are a lucky Delta Lake user on Databricks, you can create a table from the deep clone with this simple command:
CREATE TABLE wfc.delta_clones.letters_cloned DEEP CLONE wfc.delta_clones.letters
The operation will return the cloning metrics, as shows the screenshot below:

You will be also able to get the table creation context when you look at the table's history in Unity Catalog:

Good news is, you can simulate the deep clone in vanilla Delta Lake. The operation will require two different steps, though. First, you have to create the table with the same schema and partitioning logic as the former table. For that you should use CREATE TABLE cloned_table LIKE former_table. Unlike CREATE TABLE ... AS SELECT, it preserves partitioning logic. Once you create the table in your catalog, you can copy the data from the source to the cloned table. The next snippet shows these two steps:
sparkSession.sql("CREATE TABLE demo3_target LIKE demo3_src")
sparkSession.read.table("demo3_src").writeTo("demo3_target").append()
Remember, the goal of the deep clone is to isolate data files. Therefore, any reference-based approach such as CONVERT TO DELTA that references existing files in the commit log without moving them to the cloned table's location, won't work for the deep clone.
As you can see, cloning is an easy way to copy a table with or without the data, depending on your use case. Furthermore, it's also a fast way to prototype or validate your processing logic if you use use the shallow clone.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩