
Dual writes - backend engineers have been facing this challenge for many years. If you are a data engineer with some projects running on production, you certainly faced it too. If not, I hope the blog post will shed some light on that issue and provide you a few solutions!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
🚀 Commit coordinator and Catalog-managed tables in Delta Lake 4!
The solutions from my blog post may become out-of-date as soon as Catalog-managed tables will be part of the Delta Lake 4. This new feature shifts from the filesystem-based writes to the catalog-based writes, enabling among others the multi-tables atomic writes.
Catalog-managed tables replace another feature added in Delta Lake 4 to address the multi-tables transactions, the Commit coordinator.
You can learn more on the work in progress here:
- Proposal introducing the Catalog-managed tables alongside the protocol changes PR.
- Last year's DAIS video by Prakhar Jain about commit coordnator and Delta Lake 4 preview announcements.
- Multi-statement transactions were explained at this year's DAIS Multi-Statement Transactions: How to Improve Data Consistency and Performance
To better understand what this dual writes problem is, let's suppose we have a batch job that implements a Fanout design pattern (cf. Chapter 6 of my Data Engineering Design Patterns book). Consequently, this job takes an input dataset and writes it to many different places. For the sake of simplicity, let's assume the job reads a Delta Lake table, applies two different transformation logics, and writes the transformed datasets to two other Delta Lake tables. Take a look at the next schema that illustrates the dual writes problem within a single job:
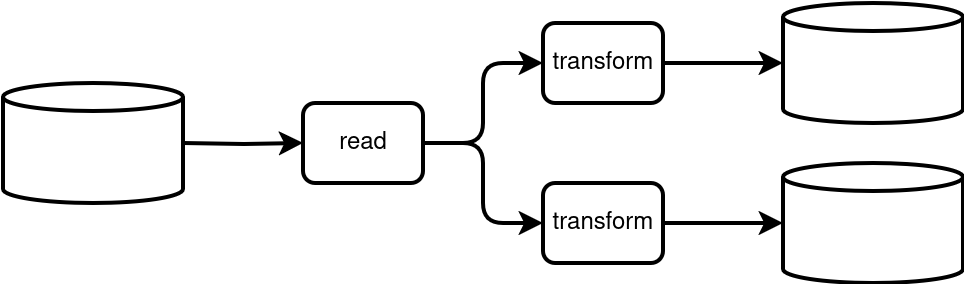
Well, technically speaking writing a transformed dataset to two different places is not a problem. It's perfectly a fine approach when you need to make data available from different places in a consistent way. However, this consistency is not guaranteed per se. In our simplistic example with only two different writes, the following may happen:
- The operation fully succeeds. The transformation results are written to both tables.
- The operation partially succeeds. The first transformation is only saved to the table. The second transformation fails. Consequently, the outcome won't be consistent as the users will see new data in the first table only.
- The operation fully fails. The first transformation fails. As a consequence, the second transformation doesn't even start. Here the outcome will be consistent as the tables won't change.
The dual write problem happens for the second scenario where, due to the per-table transaction isolation, the readers will see the partial dataset.
Microservices patterns
The patterns presented in this article are inspired from microservices patterns. If you want to learn more about them, there are plenty of online resources. A great starter for me was the Microservices blog by Chris Richardson.
Transaction compensation
The first pattern you can apply to recover from a failure is Transaction compensation, more commonly known by engineers working with microservices as Saga. In the microservices world, the idea is to run a dedicated transaction for each database and in case of any failure, launch a compensation transaction that restores the state before this sequence of local transactions started.
The same compensation principle can apply to Delta Lake tables. In case of multiple writes and a failure of one of the writers, your data processing job can compensate for the failure by restoring the previous version of the tables. Here is a quick example how it could look like in the code:
successfully_written_tables = []
def write_data(table: str):
try:
if table == 'table_2':
raise RuntimeError('Some random error')
data_to_write.write.format('delta').mode('overwrite').insertInto(table)
successfully_written_tables.append(table)
except:
for table_to_restore in successfully_written_tables:
restore_table_to_previous_version(table_to_restore)
write_data('table_1')
write_data('table_2')
To restore the table, you need to load the history and use the version before last in the RESTORE operation, for example:
def restore_table_to_previous_version(table_to_restore: str):
spark_session.sql(f'DESCRIBE HISTORY {table_to_restore}').createOrReplaceTempView('history')
version_to_restore_df = spark_session.sql(f'''
SELECT MIN(version) AS restored_version FROM (
SELECT * FROM history v ORDER BY version DESC LIMIT 2
) vv
''').collect()
version_to_restore = version_to_restore_df[0].restored_version
print(f'{table_to_restore} will be restored to {version_to_restore}')
spark_session.sql(f'RESTORE {table_to_restore} TO VERSION AS OF {version_to_restore}')
Unfortunately, this approach doesn't guarantee a 100% resilience. After all, any of the restore operations can also fail, leaving the tables in an inconsistent state.
Transactional outbox with Change Data Feed
Another pattern from microservices that we could adapt in Delta Lake to address the dual writes problem is Transactional outbox. The idea is to save a record into two tables inside the same database - therefore, by using one transaction. One of the tables is the final destination while another one is the outbox table from the pattern's title. The role of this table is to provide the record to other data stores. The next schema illustrates this idea where a consumer streams changes from the outbox table into a streaming broker:
In Delta Lake - but also in any other data store supporting Change Data Capture - the transactional outbox can be implemented with Change Data Feed (CDF). To make it work we need to start by creating a table with the CDF enabled:
spark_session.sql(f'''
CREATE TABLE `default`.`{table}` (
number INT NOT NULL,
letter STRING NOT NULL
)
USING DELTA
TBLPROPERTIES (delta.enableChangeDataFeed = true)
''')
Next, you can stream the changes by simply configuring your reader like this:
spark_session.readStream.format('delta')
.option('readChangeFeed', 'true')
.option('startingVersion', 0)
.table(table)
As a result, the implementation with two arrows from the previous picture simplifies into:
This solution applies only when there is a need to consume the same record from a data at-rest and data in-motion. It won't work if there are additional tables involved in the writing part.
Proxy
The last pattern that we could borrow from software engineering is the proxy. The idea is to put an intermediary layer between the consumers and services. In Delta Lake, we could leverage this concept to create views exposing data from correctly committed table-based transactions. How? With the help of a final transaction table that would store the most recent commit number per table involved in the dual writer. If it sounds confusing, let's see some code. First, the dual writer logic with the proxy calls:
tables_with_versions = {}
def write_data(table: str) -> bool:
try:
if should_fail and table == 'table_4':
print('Error!')
raise RuntimeError('Some random error')
data_to_write.write.format('delta').mode('overwrite').insertInto(table)
tables_with_versions[table] = get_last_version(table)
return True
except Exception as error:
print(error)
return False
result_1 = write_data('table_3')
result_2 = write_data('table_4')
if result_1 and result_2:
print(tables_with_versions)
update_last_versions_in_outbox_table(tables_with_versions)
all_versions = tables_with_versions
else:
all_versions = get_all_versions_from_the_outbox()
create_view('table_3', all_versions)
create_view('table_4', all_versions)
As you can see, the each successful write updates the committed transaction in a local dictionary and returns true from the writer function. If all writers return true, it means the job can update the most recent versions associated with those tables in the mapping table. Otherwise, the update doesn't happen.
Next, another function creates a view for each table by using the most recent version saved in the mapping table. Consequently, it will use the new versions only when all writers succeed. The following picture summarizes this workflow:
But yet again, the solution has its own limits. Even though there is this additional exposition layer, the physical tables still store partially valid data. This approach also requires more effort than the transaction compensation where you simply need to get the version before last for rollbacked transactions to restore the tables.
With all that said, I'm even more excited to see the Catalog-managed tables going GA! As you saw, the solutions from the blog post require some code whereas we all know the best commit is the one that removes the code. Native catalog-managed tables would make this best practice come true :)
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩