
Time travel is a quite popular Delta Lake feature. But do you know it's not the single one you can use to interact with the past versions? An alternative is the RESTORE command, and it'll be the topic of this blog post.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Another option you have to rollback a Delta table to a past version is the RESTORE command. Although it looks similar, it implies a different semantic. Let's understand it better with a table created for the code below:
Seq((1, "a"), (2, "b"), (3, "c")).toDF("number", "letter").write.format("delta").
mode(SaveMode.Overwrite).saveAsTable(NumbersWithLettersTable)
Seq((4, "d"), (5, "e"), (6, "f"), (7, "g")).toDF("number", "letter").write.insertInto(NumbersWithLettersTable)
Seq((8, "h"), (9, "i")).toDF("number", "letter").write.insertInto(NumbersWithLettersTable)
The code should create 3 commit logs that you can retrieve from DESCRIBE HISTORY command:
+-------+-----------------------+------+--------+---------------------------------+----------------------------------------------------------------------------------------------+----+--------+---------+-----------+--------------+-------------+-----------------------------------------------------------+------------+-----------------------------------+
|version|timestamp |userId|userName|operation |operationParameters |job |notebook|clusterId|readVersion|isolationLevel|isBlindAppend|operationMetrics |userMetadata|engineInfo |
+-------+-----------------------+------+--------+---------------------------------+----------------------------------------------------------------------------------------------+----+--------+---------+-----------+--------------+-------------+-----------------------------------------------------------+------------+-----------------------------------+
|2 |2024-10-08 05:42:52.015|NULL |NULL |WRITE |{mode -> Append, partitionBy -> []} |NULL|NULL |NULL |1 |Serializable |true |{numFiles -> 2, numOutputRows -> 2, numOutputBytes -> 1368}|NULL |Apache-Spark/3.5.1 Delta-Lake/3.2.0|
|1 |2024-10-08 05:42:50.837|NULL |NULL |WRITE |{mode -> Append, partitionBy -> []} |NULL|NULL |NULL |0 |Serializable |true |{numFiles -> 4, numOutputRows -> 4, numOutputBytes -> 2736}|NULL |Apache-Spark/3.5.1 Delta-Lake/3.2.0|
|0 |2024-10-08 05:42:46.48 |NULL |NULL |CREATE OR REPLACE TABLE AS SELECT|{partitionBy -> [], clusterBy -> [], description -> NULL, isManaged -> true, properties -> {}}|NULL|NULL |NULL |NULL |Serializable |false |{numFiles -> 3, numOutputRows -> 3, numOutputBytes -> 2052}|NULL |Apache-Spark/3.5.1 Delta-Lake/3.2.0|
+-------+-----------------------+------+--------+---------------------------------+----------------------------------------------------------------------------------------------+----+--------+---------+-----------+--------------+-------------+-----------------------------------------------------------+------------+-----------------------------------+
Now, when you want to read a past version, let's say the version 1, you can issue a query like SELECT * FROM ${NumbersWithLettersTable} VERSION AS OF 1 ORDER BY letter. It'll correctly print all rows added up to the version 1, as shown in the next snippet:
+------+------+ |number|letter| +------+------+ |1 |a | |2 |b | |3 |c | |4 |d | |5 |e | |6 |f | |7 |g | +------+------+
However, if you don't write this dataset, the time-travel will remain local to your connection. Put differently, any further reads will continue with the most recent snapshot of the Delta table. That's where RESTORE behaves differently. If you issue a restore query, for example RESTORE TABLE ${NumbersWithLettersTable} TO VERSION AS OF 1, the most recent snapshot will change to the restored version and a new commit will be recorded, as you can see in the DESCRIBE HISTORY's output executed after the restore:
+-------+-----------------------+------+--------+---------------------------------+----------------------------------------------------------------------------------------------+----+--------+---------+-----------+--------------+-------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------+------------+-----------------------------------+
|version|timestamp |userId|userName|operation |operationParameters |job |notebook|clusterId|readVersion|isolationLevel|isBlindAppend|operationMetrics |userMetadata|engineInfo |
+-------+-----------------------+------+--------+---------------------------------+----------------------------------------------------------------------------------------------+----+--------+---------+-----------+--------------+-------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------+------------+-----------------------------------+
|3 |2024-10-08 05:51:55.062|NULL |NULL |RESTORE |{version -> 1, timestamp -> NULL} |NULL|NULL |NULL |2 |Serializable |false |{numRestoredFiles -> 0, removedFilesSize -> 1368, numRemovedFiles -> 2, restoredFilesSize -> 0, numOfFilesAfterRestore -> 7, tableSizeAfterRestore -> 4788}|NULL |Apache-Spark/3.5.1 Delta-Lake/3.2.0|
|2 |2024-10-08 05:42:52.015|NULL |NULL |WRITE |{mode -> Append, partitionBy -> []} |NULL|NULL |NULL |1 |Serializable |true |{numFiles -> 2, numOutputRows -> 2, numOutputBytes -> 1368} |NULL |Apache-Spark/3.5.1 Delta-Lake/3.2.0|
|1 |2024-10-08 05:42:50.837|NULL |NULL |WRITE |{mode -> Append, partitionBy -> []} |NULL|NULL |NULL |0 |Serializable |true |{numFiles -> 4, numOutputRows -> 4, numOutputBytes -> 2736} |NULL |Apache-Spark/3.5.1 Delta-Lake/3.2.0|
|0 |2024-10-08 05:42:46.48 |NULL |NULL |CREATE OR REPLACE TABLE AS SELECT|{partitionBy -> [], clusterBy -> [], description -> NULL, isManaged -> true, properties -> {}}|NULL|NULL |NULL |NULL |Serializable |false |{numFiles -> 3, numOutputRows -> 3, numOutputBytes -> 2052} |NULL |Apache-Spark/3.5.1 Delta-Lake/3.2.0|
+-------+-----------------------+------+--------+---------------------------------+----------------------------------------------------------------------------------------------+----+--------+---------+-----------+--------------+-------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------+------------+-----------------------------------+
⚠️ Data consistency
The RESTORE command replaces the dataset physically. If your restored table depends on another tables at the logical level, e.g. via foreign key relationships, restoring your table to one of the past versions can break the relationships consistency. For example, your restored version may reference a row in a dimension table that has been removed meantime, leading to empty joins. Thank you, Adrian, for this additional insight!
RestoreTableCommand
The command - you can learn more about them in one of my previous blog posts Apache Spark can be eagerly evaluated too - Commands - responsible for restoring the table is RestoreTableCommand. It starts by getting the snapshot of the table at the restored version and the of all files associated with that version:
// RestoreTableCommand#run val snapshotToRestore = deltaLog.getSnapshotAt(versionToRestore) val latestSnapshotFiles = latestSnapshot.allFiles val snapshotToRestoreFiles = snapshotToRestore.allFiles
Let's say, we have the following files on both sides:
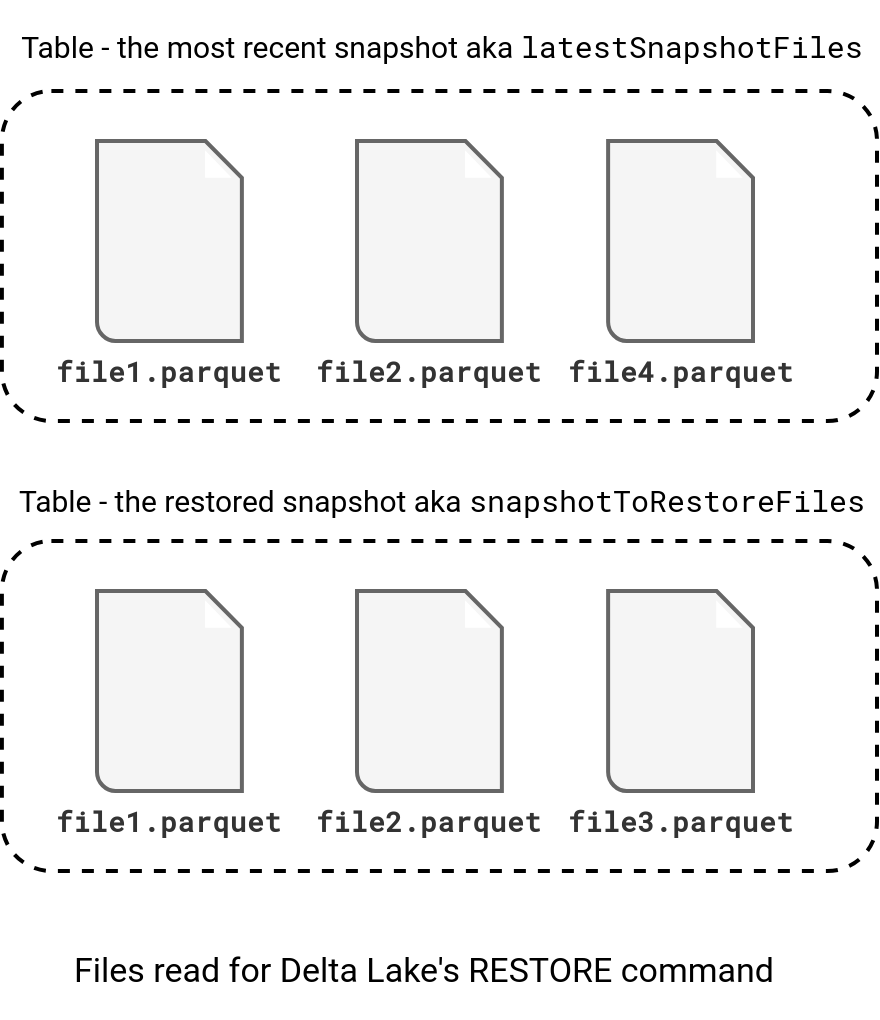
There is an intermediary step for handling deletion vectors but I'm omitting it here to focus on the simplest case. The next operation consists of mapping the list of files to two DataFrames, one referring to the files as source (snapshot to restore), and another referring to them as target (last snapshot):
val normalizedSourceWithoutDVs = snapshotToRestoreFiles.mapPartitions { files =>
files.map(file => (file, file.path))
}.toDF("srcAddFile", "srcPath")
val normalizedTargetWithoutDVs = latestSnapshotFiles.mapPartitions { files =>
files.map(file => (file, file.path))
}.toDF("tgtAddFile", "tgtPath")
After this mapping, the RestoreTableCommand leverages the left anti join semantics to generate the list of added and removed files to the commit that is going to be created by the command. To recall, a left anti join takes all rows from the left table without the matching rows in the right dataset. In our case, the outcome will contain:
- All files that are present in the snapshot version and missing in the last snapshot version. Put differently, it will be all files that potentially have been removed between the versions. They will be marked as add files action in the commit log.
- All files that are present in the most recent snapshot but are missing in the restored snapshot version. Put differently, it's a list of the files added since the restored commit. They will then be marked as remove files action in the commit log.
The joins for both conditions are present below:
val joinExprs =
column("srcPath") === column("tgtPath") and
// Use comparison operator where NULL == NULL
column("srcDeletionVectorId") <=> column("tgtDeletionVectorId")
val filesToAdd = normalizedSource
.join(normalizedTarget, joinExprs, "left_anti")
.select(column("srcAddFile").as[AddFile])
.map(_.copy(dataChange = true))
val filesToRemove = normalizedTarget
.join(normalizedSource, joinExprs, "left_anti")
.select(column("tgtAddFile").as[AddFile])
.map(_.removeWithTimestamp())
val addActions = withDescription("add actions") {
filesToAdd.toLocalIterator().asScala
}
val removeActions = withDescription("remove actions") {
filesToRemove.toLocalIterator().asScala
}
Pretty simple, isn't it? So far yes but there are some specific scenarios to manage by the command.
Special scenarios
The first use case here are missing files. The restored version might not have all the files due to the vacuum or manual removal. If the spark.sql.files.ignoreMissingFiles flag is disabled, which is by default, and the RestoreTableCommand detects any not existing files, it will throw this error:
def restoreMissedDataFilesError(missedFiles: Array[String], version: Long): Throwable =
new IllegalArgumentException(
s"""Not all files from version $version are available in file system.
| Missed files (top 100 files): ${missedFiles.mkString(",")}.
| Please use more recent version or timestamp for restoring.
| To disable check update option ${SQLConf.IGNORE_MISSING_FILES.key}"""
.stripMargin
)
You can also enable this ignoreMissingFiles but in that case, the restore will return a partial table.
Another challenge for the RESTORE command is related to the protocol change. The spark.databricks.delta.restore.protocolDowngradeAllowed is turned off by default, but you can enable it if you want your restored table to always use the protocol associated to the restored snapshot. But it's a risky operation from the time travel perspective; as per the commit introducing the control:

For that reason, by default, the RESTORE command always uses the most recent readers and writers:
// Only upgrade the protocol, never downgrade (unless allowed by flag), since that may break
// time travel.
val protocolDowngradeAllowed =
conf.getConf(DeltaSQLConf.RESTORE_TABLE_PROTOCOL_DOWNGRADE_ALLOWED)
val newProtocol = if (protocolDowngradeAllowed) {
sourceProtocol
} else {
sourceProtocol.merge(targetProtocol)
}
Table features
It's worth adding, Delta Lake 2.3.0 has introduced Table features to configure features available on each table. They succeed less flexible protocol versions.
Restore or time-travel?
Now, one question arises, when to time-travel, and when to restore? As you saw, the RESTORE command creates a new version of the table, while time travel can be thought more as an exploratory action you take to analyze past data.
Besides, the RESTORE command takes the data as is. The time travel is more flexible and lets you apply some additional transformations on top of the restored dataset before writing. Remember, it's based on a SELECT statement.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Delta Lake and restore - traveling in time differently here:
- Prevent Protocol Downgrades during RESTORE in Delta How to Rollback a Delta Lake Table to a Previous Version with Restore
Related blog posts:
- Commit log decorator with userMetadata property
- Truncating a Delta Lake table, aka metadata-only operations
- Idempotent writer