
Streaming Delta tables is slightly different from streaming native streaming sources, such as Apache Kafka topics. One of the significant differences is schema enforcement. It leads to the job failure in case of schema changes of the streamed table.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
On the other hand, Apache Kafka can have retro-compatible schema changes that won't stop the job. The reason for blocking the changes in Delta Lake is preventing the risk of propagating unexpected data downstream. A failure is the way of saying "please stop and adapt to the evolved schema". While it's valid, sometimes you may need a more automated schema evolution management. It's where schema tracking should help.
Schema tracking 101
When you stream a Delta table you will face different schema-related scenarios:
- You read the most recent version, hence any prior schema evolution actions are already there.
- You read a past table version whose schema is different from the most recent one. It can happen when you start a new streaming job with startingVersion or startingTimestamp options. Another use case is when you restart the job from the checkpoint location.
- You're streaming the table while someone is making a schema change on it.
A different schema is not a big deal as it only requires job restart, if the evolution concerns a new column. It's a so-called additive change. When the change is for any other type, such as column renaming or dropping, we talk then about a non-additive change that breaks the stream and downstream consumers. To understand how, let's take two use cases identified in the design doc of the feature:
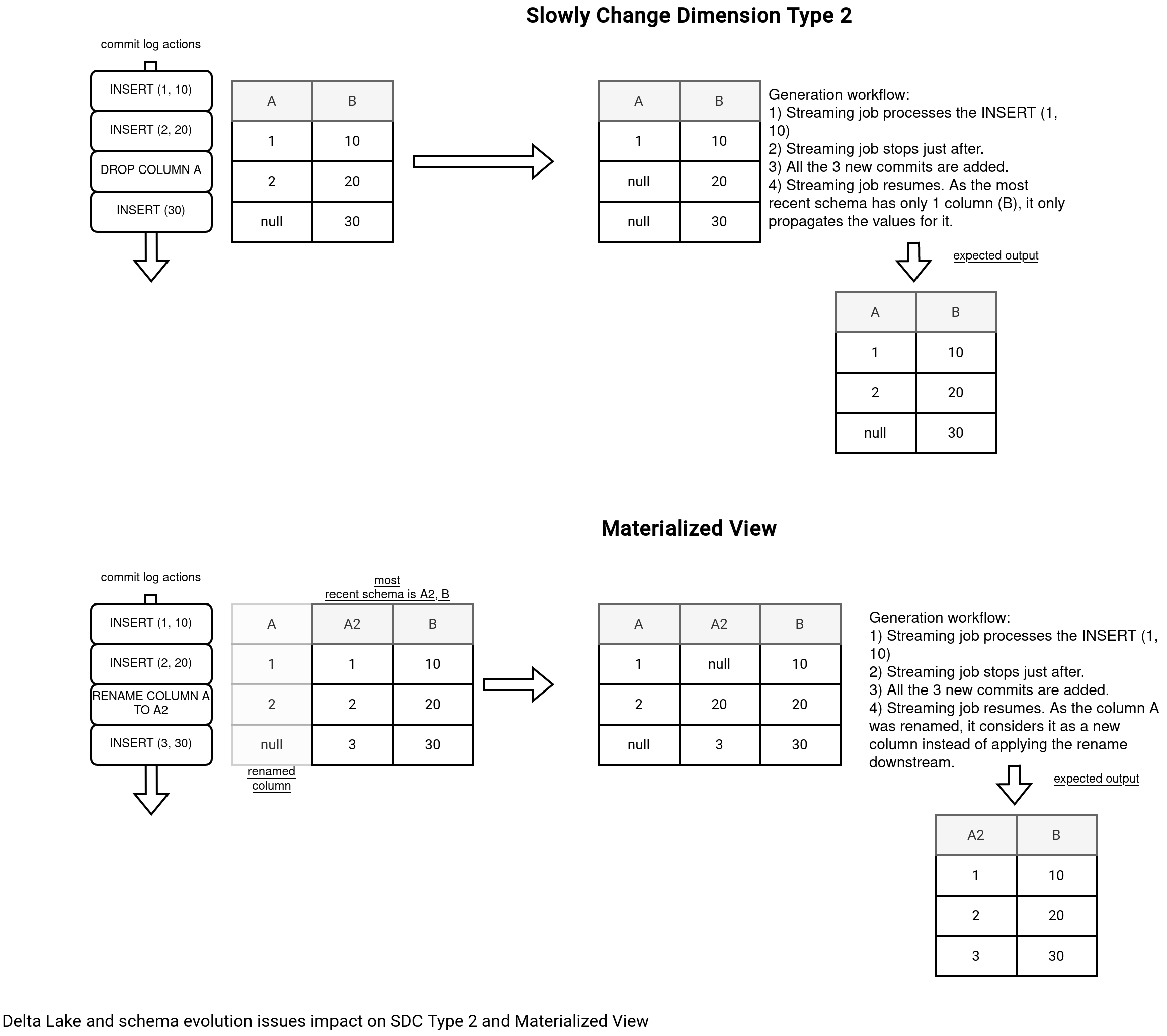
As you can see in the picture, both actions of dropping and renaming columns have a bad impact on the SDC and Materialized View use cases. Schema tracking gives an extra control over these evolution scenarios but it still fails the query whenever a change is detected!.
Before we delve into the code, an important thing. Schema tracking addresses the RENAME and DROP columns operations. Delta Lake supports them only when the column mapping is enabled on the table.
Step 1: initialization
Let's do exception-based learning this time. First, when the streamed table changes while the job is running, you'll get the following error:
Updated table configurations: delta.enableChangeDataFeed:true, delta.columnMapping.mode:name, delta.columnMapping.maxColumnId:2.
Updated table protocol: 2,5
at org.apache.spark.sql.delta.DeltaErrorsBase.streamingMetadataEvolutionException(DeltaErrors.scala:2798)
at org.apache.spark.sql.delta.DeltaErrorsBase.streamingMetadataEvolutionException$(DeltaErrors.scala:2787)
at org.apache.spark.sql.delta.DeltaErrors$.streamingMetadataEvolutionException(DeltaErrors.scala:3203)
at org.apache.spark.sql.delta.sources.DeltaSourceMetadataEvolutionSupport.updateMetadataTrackingLogAndFailTheStreamIfNeeded(DeltaSourceMetadataEvolutionSupport.scala:423)
at org.apache.spark.sql.delta.sources.DeltaSourceMetadataEvolutionSupport.updateMetadataTrackingLogAndFailTheStreamIfNeeded$(DeltaSourceMetadataEvolutionSupport.scala:398)
at org.apache.spark.sql.delta.sources.DeltaSource.updateMetadataTrackingLogAndFailTheStreamIfNeeded(DeltaSource.scala:679)
at org.apache.spark.sql.delta.sources.DeltaSourceMetadataEvolutionSupport.updateMetadataTrackingLogAndFailTheStreamIfNeeded(DeltaSourceMetadataEvolutionSupport.scala:386)
at org.apache.spark.sql.delta.sources.DeltaSourceMetadataEvolutionSupport.updateMetadataTrackingLogAndFailTheStreamIfNeeded$(DeltaSourceMetadataEvolutionSupport.scala:369)
at org.apache.spark.sql.delta.sources.DeltaSource.updateMetadataTrackingLogAndFailTheStreamIfNeeded(DeltaSource.scala:679)
at org.apache.spark.sql.delta.sources.DeltaSource.commit(DeltaSource.scala:1175)
What happens here? First, when the micro-batch commits the table reading, from the commit function. The commit function that besides committing the work also updates the schema tracking location and, in the end, fails the micro-batch. Why so? The schema tracking is made after the commit to avoid a premature schema evolution that would lead to inconsistent processing. In case of a commit failure, the restarted job would operate on the new schema but on top of the dataset written with the previous schema version.
In the end of this step, you'll get then a schema tracking file as the one in the following snippet:
$ cat checkpoint3/schema_tracking/_schema_log_8288003a-6e4a-441f-a130-4ffc1e340c66/0
v1
{"tableId":"8288003a-6e4a-441f-a130-4ffc1e340c66","deltaCommitVersion":1,"dataSchemaJson":"{\"type\":\"struct\",\"fields\":[{\"name\":\"number\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{\"delta.columnMapping.id\":1,\"delta.columnMapping.physicalName\":\"number\"}},{\"name\":\"letter\",\"type\":\"string\",\"nullable\":true,\"metadata\":{\"delta.columnMapping.id\":2,\"delta.columnMapping.physicalName\":\"letter\"}}]}","partitionSchemaJson":"{\"type\":\"struct\",\"fields\":[]}","sourceMetadataPath":"file:/tmp/table-file-formats/012_streaming_reader/delta_lake/checkpoint3/sources/0","tableConfigurations":{"delta.enableChangeDataFeed":"true","delta.columnMapping.mode":"name","delta.columnMapping.maxColumnId":"2"},"protocolJson":"{\"protocol\":{\"minReaderVersion\":2,\"minWriterVersion\":5}}"}
$ cat checkpoint3/schema_tracking/_schema_log_8288003a-6e4a-441f-a130-4ffc1e340c66/1
v1
{"tableId":"8288003a-6e4a-441f-a130-4ffc1e340c66","deltaCommitVersion":3,"dataSchemaJson":"{\"type\":\"struct\",\"fields\":[{\"name\":\"letter\",\"type\":\"string\",\"nullable\":true,\"metadata\":{\"delta.columnMapping.id\":2,\"delta.columnMapping.physicalName\":\"letter\"}}]}","partitionSchemaJson":"{\"type\":\"struct\",\"fields\":[]}","sourceMetadataPath":"file:/tmp/table-file-formats/012_streaming_reader/delta_lake/checkpoint3/sources/0","tableConfigurations":{"delta.enableChangeDataFeed":"true","delta.columnMapping.mode":"name","delta.columnMapping.maxColumnId":"2"},"protocolJson":"{\"protocol\":{\"minReaderVersion\":2,\"minWriterVersion\":5}}"}
The _schema_log_8288003a-6e4a-441f-a130-4ffc1e340c66/1 file corresponds to the DROP COLUMN number operation. What you can also see here is the output format that relies on the column mapping (delta.columnMapping.[physicalName|id]) to handle the evolution and apply the most recent schema.
The schema tracking files are created before processing the data written with the new schema. That way, once you restart the job, Apache Spark will know the schema to apply directly from this part building the Source object:
override def createSource( // ...
val schemaTrackingLogOpt = DeltaDataSource.getMetadataTrackingLogForDeltaSource(
sqlContext.sparkSession, snapshot, parameters,
// Pass in the metadata path opt so we can use it for validation
sourceMetadataPathOpt = Some(metadataPath))
val readSchema = schemaTrackingLogOpt
.flatMap(_.getCurrentTrackedMetadata.map(_.dataSchema))
.getOrElse(snapshot.schema)
Well, technically Apache Spark knows the schema but there is yet another protection to avoid propagating eventually inconsistent data for the downstream consumers. Check the stack trace right below:
Caused by: org.apache.spark.sql.delta.DeltaRuntimeException: [DELTA_STREAMING_CANNOT_CONTINUE_PROCESSING_POST_SCHEMA_EVOLUTION] We've detected one or more non-additive schema change(s) (RENAME COLUMN) between Delta version 1 and 2 in the Delta streaming source.
Please check if you want to manually propagate the schema change(s) to the sink table before we proceed with stream processing using the finalized schema at 2.
Once you have fixed the schema of the sink table or have decided there is no need to fix, you can set (one of) the following SQL configurations to unblock the non-additive schema change(s) and continue stream processing.
To unblock for this particular stream just for this series of schema change(s): set `spark.databricks.delta.streaming.allowSourceColumnRenameAndDrop.ckpt_-2054049119 = 2`.
To unblock for this particular stream: set `spark.databricks.delta.streaming.allowSourceColumnRenameAndDrop.ckpt_-2054049119 = always`
To unblock for all streams: set `spark.databricks.delta.streaming.allowSourceColumnRenameAndDrop = always`.
Alternatively if applicable, you may replace the `allowSourceColumnRenameAndDrop` with `allowSourceColumnRename` in the SQL conf to unblock stream for just this schema change type.
at org.apache.spark.sql.delta.DeltaErrorsBase.cannotContinueStreamingPostSchemaEvolution(DeltaErrors.scala:2879)
at org.apache.spark.sql.delta.DeltaErrorsBase.cannotContinueStreamingPostSchemaEvolution$(DeltaErrors.scala:2854)
at org.apache.spark.sql.delta.DeltaErrors$.cannotContinueStreamingPostSchemaEvolution(DeltaErrors.scala:3203)
at org.apache.spark.sql.delta.sources.DeltaSourceMetadataEvolutionSupport$.$anonfun$validateIfSchemaChangeCanBeUnblockedWithSQLConf$2(DeltaSourceMetadataEvolutionSupport.scala:543)
at org.apache.spark.sql.delta.sources.DeltaSourceMetadataEvolutionSupport$.$anonfun$validateIfSchemaChangeCanBeUnblockedWithSQLConf$2$adapted(DeltaSourceMetadataEvolutionSupport.scala:516)
at scala.Option.foreach(Option.scala:437)
at org.apache.spark.sql.delta.sources.DeltaSourceMetadataEvolutionSupport$.validateIfSchemaChangeCanBeUnblockedWithSQLConf(DeltaSourceMetadataEvolutionSupport.scala:516)
at org.apache.spark.sql.delta.sources.DeltaSourceMetadataTrackingLog$.create(DeltaSourceMetadataTrackingLog.scala:299)
at org.apache.spark.sql.delta.sources.DeltaDataSource$.$anonfun$getMetadataTrackingLogForDeltaSource$1(DeltaDataSource.scala:465)
at scala.Option.map(Option.scala:242)
at org.apache.spark.sql.delta.sources.DeltaDataSource$.getMetadataTrackingLogForDeltaSource(DeltaDataSource.scala:458)
at org.apache.spark.sql.delta.sources.DeltaDataSource.createSource(DeltaDataSource.scala:138)
at org.apache.spark.sql.execution.datasources.DataSource.createSource(DataSource.scala:289)
From the stack trace you can learn that indeed, DeltaDataSource relies on the schema tracking log but it also requires a configuration on your side to enable non-additive schema changes. You can decide to:
- Support them all; for that, set spark.databricks.delta.streaming.allowSourceColumnRenameAndDrop
- Support only the RENAMEs; set spark.databricks.delta.streaming.allowSourceColumnRename
- Support only the DROPs; set spark.databricks.delta.streaming.allowSourceColumnDrop
You can configure them globally with the always value or just for the given micro-batch (ckpt_-2054049119 = 2; but the number will be different each time as it signifies the micro-batch).
Step 2: schema evolution
Likely, the schemas won't evolve only once and you'll need to handle the evolutions many times in your streaming job. What happens when a streaming query encounters another set of changes? Let's analyze this sequence of events:
- Stop the streaming query.
- Insert rows to the schema version 2.
- Rename one column.
- Insert rows to the schema version 3.
Now, even though you have kept the schemaTrackingLocation and allow* entry set, the query will fail again. The problem is more related to the scope this time. The micro-batch sees data with two different schemas. The first inserted rows have the version 2 while the second ones have the version 3. Therefore again, you need to restart the job after seeing the stack trace referring to the commit stage. Good news is that after the restart, your job will generate the data according to the new columns.
Offsets
The feature brings a special consideration to the offsets resolution. As you saw before, the stream is kind of broken into two when the micro-batch takes rows written with two different schemas. Let's see how it works.
The picture below illustrates the idea of this schema boundary (aka schema barrier):
The idea is to stop the micro-batch eagerly, i.e. before it processes all planned offsets, when there are multiple schema changes in the initially read offsets. This protection comes from the latestOffset that returns the last offset to process in the micro-batch. Under-the-hood it calls a DeltaSource#getFileChangesWithRateLimit that reads the commit log from a specific version and returns all the files to process. The magic happens here:
// DeltaSource
private def filterAndGetIndexedFiles(iterator: Iterator[Action], version: Long, shouldSkipCommit: Boolean,
metadataOpt: Option[Metadata], protocolOpt: Option[Protocol]): Iterator[IndexedFile] = {
// (1)
val filteredIterator =
if (shouldSkipCommit) {
Iterator.empty
} else {
iterator.collect { case a: AddFile if a.dataChange => a }
}
// ...
addBeginAndEndIndexOffsetsForVersion(version,
// (2)
getMetadataOrProtocolChangeIndexedFileIterator(metadataOpt, protocolOpt, version) ++
indexedFiles)
}
The method returns an iterator composed of an optional metadata part and a data part created by applying the (1) filter logic on top of all the commit log actions. Even though both iterators return an IndexedFile, the metadata representations have special indexes that correspond to the metadata changes:
object DeltaSourceOffset extends Logging {
// The index for an IndexedFile that also contains a metadata change. (from VERSION_3)
val METADATA_CHANGE_INDEX: Long = -20
// The index for an IndexedFile that is right after a metadata change. (from VERSION_3)
val POST_METADATA_CHANGE_INDEX: Long = -19
protected def getMetadataOrProtocolChangeIndexedFileIterator(metadataChangeOpt: Option[Metadata], protocolChangeOpt: Option[Protocol], version: Long): ClosableIterator[IndexedFile] = {
if (trackingMetadataChange && hasMetadataOrProtocolChangeComparedToStreamMetadata(metadataChangeOpt, protocolChangeOpt, version)) {
// Create an IndexedFile with metadata change
Iterator.single(IndexedFile(version, DeltaSourceOffset.METADATA_CHANGE_INDEX, null)).toClosable
} else {
Iterator.empty.toClosable
}
}
That's the first part that generates the iterator with all changes to process in a micro-batch. There is also another part that introduces the schema barrier:
protected def getFileChangesWithRateLimit( // ...
// Stop before any schema change barrier if detected.
stopIndexedFileIteratorAtSchemaChangeBarrier(iter)
}
protected def stopIndexedFileIteratorAtSchemaChangeBarrier(fileActionScanIter: ClosableIterator[IndexedFile]): ClosableIterator[IndexedFile] = {
fileActionScanIter.withClose { iter =>
val (untilSchemaChange, fromSchemaChange) = iter.span { i =>
i.index != DeltaSourceOffset.METADATA_CHANGE_INDEX
}
// This will end at the schema change indexed file (inclusively)
// If there are no schema changes, this is an no-op.
untilSchemaChange ++ fromSchemaChange.take(1)
}
}
That way, the latestOffset retrieves the last action which is the schema change in our use case. The whole process is summarized in the next schema:
From this and my two previous streaming in Delta Lake blog posts you can clearly see that the schema consideration is different than for Apache Kafka data source. Here, the input DataFrame cannot be an arbitrary set of bytes. Instead, it has a specific structure that makes operating streaming jobs more challenging but at the same time, more safe, in case of any schema evolutions.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Schema tracking in Delta Lake here:
Related blog posts:
- Commit log decorator with userMetadata property
- Truncating a Delta Lake table, aka metadata-only operations
- Idempotent writer