
There are two modes for data removal from a Delta Lake table, the data and the metadata ones. The first needs to identify the records to remove by running the explicit select query on the table. On another hand, the metadata mode doesn't interact with the data. It's often faster but due to the metadata-only character, it's also more limited.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In this blog post I'll share with you things I learned for data removal in Delta Lake. And I'm going to start with an operation that you might not be aware of when you start a data engineering journey, the truncate.
TRUNCATE TABLE
If we had to translate the TRUNCATE TABLE to some real-world action, it might be erasing a whole drawing. Just imagine your kid asked you to draw a car but after you drew the wheels, he changed his mind and now he wants you to draw a house. I doubt you could adapt four wheels to a house, so the single way is to erase everything without thinking. On another hand, if he asked you to finally draw a tractor. In that case you can simply erase two wheels behind and replace them with bigger ones.
When you erased everything without thinking, you just made the TRUNCATE operation in the database world. On another hand, replacing two wheels is like running a DELETE FROM ... WHERE operation to delete a subset of dataset before eventually writing it again.
In more technical terms, the TRUNCATE is considered as a Data Definition Language (DDL) statement while the DELETE is a Data Manipulation Language (DML) one. Put differently, DML operations manipulates the data which can be slower than similar action made with an alternative DDL operation which stays at the metadata level.
A quick look at popular databases' documentations explains this data vs. metadata semantics pretty clearly:
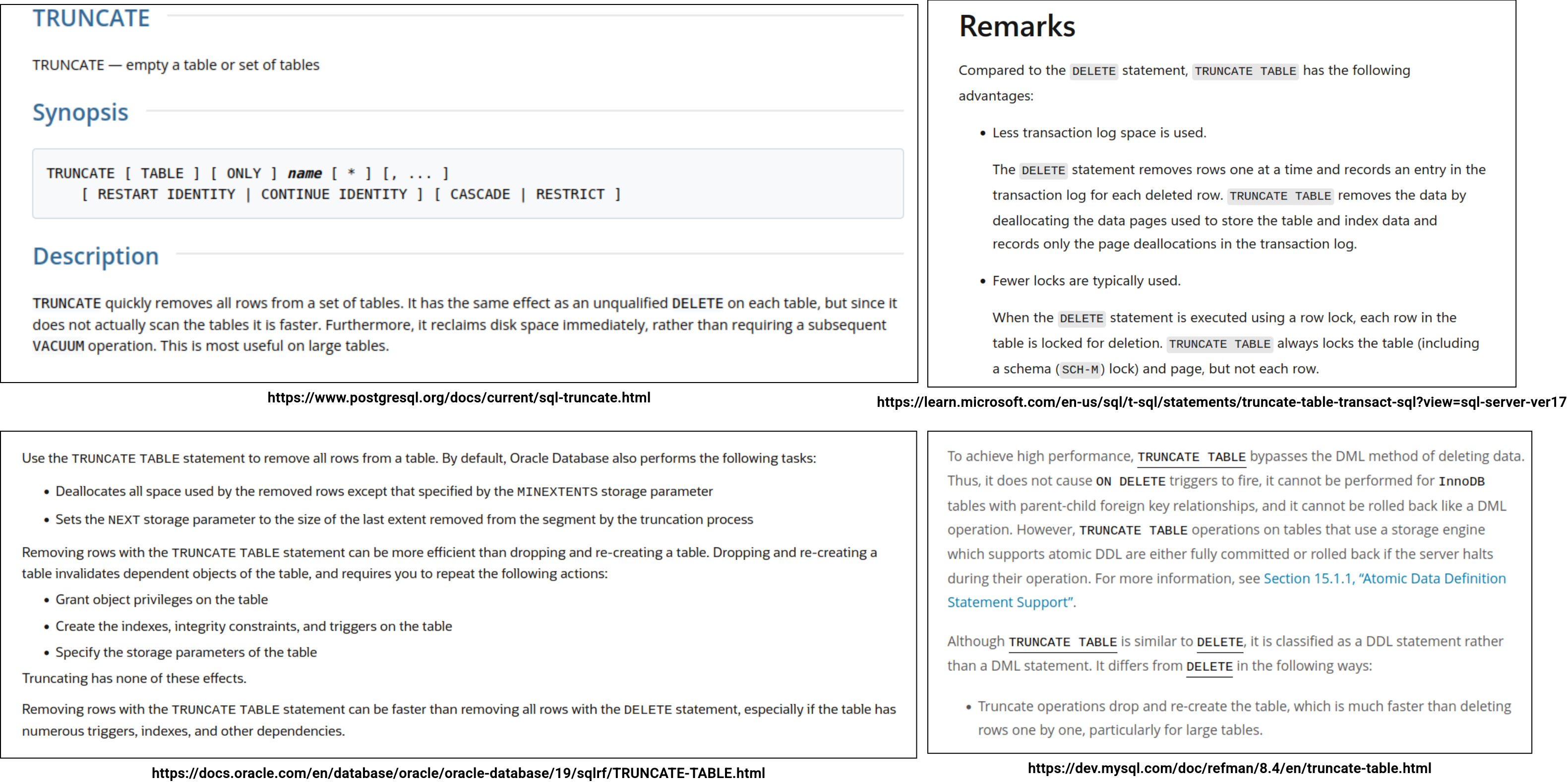
TRUNCATE TABLE in Delta Lake
When it comes to running TRUNCATE TABLE on top of Delta Lake, the first thing to know is the command availability. The operation doesn't exist on vanilla Delta Lake and you can use it only on Databricks. Below you can find an entry in the commit log representing a table truncation:
When you analyze the query, you'll also see it doesn't touch any data:
Simulating TRUNCATE TABLE
But good news is, you can simulate TRUNCATE TABLE by running DELETE FROM without specifying any condition. In that case, Delta Lake will behave the same as for TRUNCATE, i.e. it will take all files from the most recent snapshot. You can see it in the next snippet executed where you run the DELETE FROM without any condition:
// org.apache.spark.sql.delta.commands.DeleteCommand#performDelete
val deleteActions: Seq[Action] = condition match {
case None =>
// ...
val allFiles: Seq[AddFile] = txn.filterFiles(Nil, keepNumRecords = reportRowLevelMetrics)
// ...
val operationTimestamp = System.currentTimeMillis()
// BK: the next map transforms all files AddFile to RemoveFile,
// i.e. it creates "remove" entries in the commit log
allFiles.map(_.removeWithTimestamp(operationTimestamp))
Metadata predicates only
Now, when you know that DELETE FROM without conditions behaves like the TRUNCATE TABLE, you may be wondering if the DELETE FROM with conditions always behaves the same, i.e. whether it always selects files to remove by executing a query on top of the data. The answer is no.
The behavior boils down to the type of the conditions. If you target a particular partition, Delta Lake will consider it as a metadata-based removal, i.e. yet again it'll list the files associated with the deleted partition, and transform them into "remove" action in the commit log. The whole magic happens in the DeltaTableUtils#isPredicatePartitionColumnsOnly where Delta Lake verifies whether each of the delete condition fully targets a partition:

On another hand, when you target a partition but within the partition you have an additional filter on a column, Delta Lake will only use the partition information to reduce the number of the files to look for data to delete:
// org.apache.spark.sql.delta.commands.DeleteCommand#performDelete val candidateFiles = txn.filterFiles(metadataPredicates ++ otherPredicates, keepNumRecords = shouldWriteDVs)
After that, Delta Lake creates an index with all file that might contain rows matching the removal predicate, and runs an Apache Spark job to fetch those records:
val fileIndex = new TahoeBatchFileIndex( sparkSession, "delete", candidateFiles, deltaLog, deltaLog.dataPath, txn.snapshot) // ... // BK: This is the DataFrame created where Delta Lake applies the filtering logic DataFrameUtils.ofRows(spark, replaceFileIndex(spark, target, fileIndex)) // ... // BK: And finally, this is the job executing the filtering and gathering the names of files to rewrite data.filter(Column(cond)) .select(input_file_name()) .filter(Column(incrDeletedCountExpr)) .distinct().as[String].collect()
Even though the vanilla Delta Lake doesn't support the TRUNCATE TABLE syntax, it's perfectly possible to run a metadata-only data removal with DELETE FROM without conditions, or DELETE FROM targeting partitions only.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩