
One of the big challenges in streaming Delta Lake is the inability to handle in-place changes, like updates, deletes, or merges. There is good news, though. With a little bit of effort on your data provider's side, you can process a Delta Lake table as you would process Apache Kafka topics, hence without in-place changes.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
For the bad news, you can't do it alone and the success fully depends on the capabilities of your data provider with other consumers. If you're alone able to handle changelog events and build the data exposition layer from them, forcing the provider to consider all operations as inserts may not be an option. But if you don't have these constraints, keep reading to learn a bit more on these changelog-like tables.
Changelog? Append-only!
To turn a regular table into a changelog one you need to enable the appendOnly property, either globally at the SparkSession level, or locally for each table. When you do, Delta Lake will create the table with the following metadata:
$ cat 00000000000000000000.json
{"commitInfo":{...,"operationParameters":{"isManaged":"true","description":null,"partitionBy":"[]","properties":"{\"delta.appendOnly\":\"true\"}"},"isolationLevel":"Serializable","isBlindAppend":false,"operationMetrics":{...}}
{"metaData":{"id":"b9bdcc41-887f-47d2-ac08-8b40295aad08","format":{"provider":"parquet","options":{}},"schemaString":"...
"configuration":{"delta.appendOnly":"true"}, ...}
{"protocol":{"minReaderVersion":1,"minWriterVersion":2}}
{"add":{"path":"part-00000-45432504-3920-498b-a4a4-8a5aafcaa1e3-c000.snappy.parquet","partitionValues":{}...}}
As you can see from the snippet, there is a specific configuration in our table saying that it's append-only. Therefore, it can only accept insert operations for data manipulation.
Append enforcement
How does Delta Lake enforce this configuration? DeltaLog exposes this validation method that gets called in different places:
def assertRemovable(snapshot: Snapshot): Unit = {
val metadata = snapshot.metadata
if (DeltaConfigs.IS_APPEND_ONLY.fromMetaData(metadata)) {
throw DeltaErrors.modifyAppendOnlyTableException(metadata.name)
}
}
Let's take a quick look at who calls this assertion:
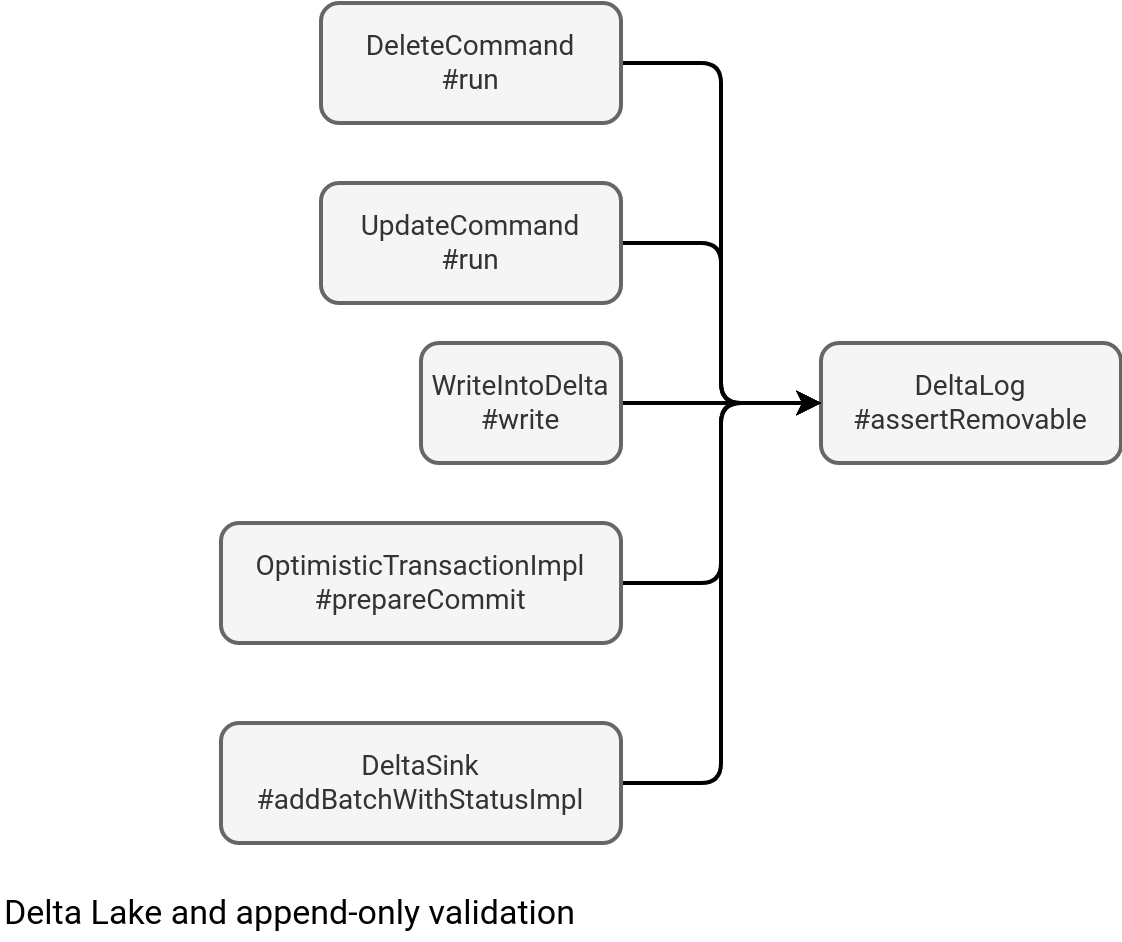
The DeleteCommand and UpdateCommand entrypoints are pretty clear. They concern the DELETE and UPDATE operations. When it comes to the three others, I must admit, it's not that easy at first glance but let's deep dive to understand this:
- WriteIntoDelta#write - calls the assertRemovable before overwriting the dataset. You can think about it like of a big DELETE FROM table operation:
else if (mode == SaveMode.Overwrite) { DeltaLog.assertRemovable(txn.snapshot) } - OptimisticTransactionImpl#prepareCommit - detects whether there are some delete actions among the files, just before committing the transaction.
- DeltaSink#addBatchWithStatusImpl - used by the streaming sink with the Complete output mode:
val deletedFiles = outputMode match { case o if o == OutputMode.Complete() => DeltaLog.assertRemovable(txn.snapshot) txn.filterFiles().map(_.remove) case _ => Nil }
What about vacuum or compaction?
It would be bad if a table couldn't be vacuumed or optimized, wouldn't it? Thankfully both operations are not considered as operating at the data level, therefore they're not prohibited by the append-only configuration. They only reorganize the dataset layout and it is not considered as an operation altering the data, i.e. the dataChange flag associated to the rewritten files in the commit log is always false, as shown below:
.
{"commitInfo":{,"operation":"OPTIMIZE",...,"operationMetrics":{"numRemovedFiles":"1000","numRemovedBytes":"826418","p25FileSize":"3955","numDeletionVectorsRemoved":"0","minFileSize":"3955","p75FileSize":"3955","p50FileSize":"3955","numAddedBytes":"3955","numAddedFiles":"1","maxFileSize":"3955"},...
{"add":{"path":"part-00000-820aea38-67a9-475b-92c1-c908effbf46b-c000.snappy.parquet","partitionValues":{},"dataChange":false...
{"remove":{"path":"part-00003-d42002e7-bdc1-4b9f-9b9b-cdef0e7e5594-c011.gz.parquet","dataChange":false,"extendedFileMetadata":true,"partitionValues":{},"size":825,"stats":"{\"numRecords\":1}"}}
...
I'm mentioning this dataChange flag on purpose. If you look at the OptimisticTransactionImpl#prepareCommit caller, you'll see that it filters out all remove actions without the data change:
// We make sure that this isn't an appendOnly table as we check if we need to delete
// files.
val removes = actions.collect { case r: RemoveFile => r }
if (removes.exists(_.dataChange)) DeltaLog.assertRemovable(snapshot)
When it comes to the VACUUM operation, by definition the command cleans the files not referenced by any commit log. Consequently, it doesn't change the data either, so it's safe to run it for the append-only tables.
But despite the no-data character, the VACUUM command passes by the prepareCommit function and the code snippet presented before. However, as it's a command without the data associated, the actions variable is empty. Below what will be added to the commit log when the VACUUM happens:
$ cat _delta_log/00000000000000000004.json
{"commitInfo":{"timestamp":1711283273000,"operation":"VACUUM START","operationParameters":{"retentionCheckEnabled":false,"defaultRetentionMillis":604800000,"specifiedRetentionMillis":0},"readVersion":3,"isolationLevel":"SnapshotIsolation","isBlindAppend":true,"operationMetrics":{"numFilesToDelete":"1000","sizeOfDataToDelete":"826418"},"engineInfo":...,"txnId":"638f8aab-b5df-4f1f-9d04-b3a9d0d424f9"}}
bartosz@bartosz:/tmp/delta-lake-playground/013_streaming_writer/warehouse/demo4_table$ cat _delta_log/00000000000000000005.json
{"commitInfo":{"timestamp":1711283280000,"operation":"VACUUM END","operationParameters":{"status":"COMPLETED"},"readVersion":4,"isolationLevel":"SnapshotIsolation","isBlindAppend":true,"operationMetrics":{"numDeletedFiles":"1000","numVacuumedDirectories":"1"},"engineInfo":...,"txnId":"cc90fe81-f19e-4a84-8a83-f13abd08aff8"}}
Representing changes
The last question you can ask yourself, how to transform the inserts into updates or deletes? Here too, a lot depends on the producer. You might consider:
- Tombstone pattern to mark a row as deleted. Here the provider should typically keep only the id column and nullify the other ones, marking the row - by convention - as removed.
- Operation flag column. Here the producer would add a column with the operation type, such as i for new row, u for an update, d for a delete.
As you can see, transforming a table into an append-only changelog is rather easy. As many other things, it's only the matter of good configuration. However, what is hidden behind this simplicity is the complexity for the clients. The data producer must write data differently and all the consumers must rebuild the table state by themselves.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩