
We all agree, data quality is essential to build trustworthy dashboards or ML algorithms. For so long the single possibility to validate the data for file formats before writing was reserved to the data processing jobs. Thankfully, Delta Lake constraints made this validation possible at the data storage layer (technically, it's still a compute layer but at a very high level of abstraction).
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
📌 Not only checks
If you need more advanced data quality checks, Delta Lake constraints won't be enough as they are limited to the columns. Besides, they don't support data validation strategies such as separating invalid records from the valid ones. But there is hope. Nowadays many open source project brings this advanced data validation engine to Apache Spark and Databricks.
A few months ago I published a new series on that topic: data quality on Databricks.
Constraints setup
Delta Lake supports two types of constraints: nullability checks and value checks. Their creation is different and:
- Nullability checks are set at the table creation level as simple NOT NULL statements. They can be later removed with ALTER TABLE CHANGE COLUMN...DROP NOT NULL command.
- The same is not valid for the value checks. They can only be added on top of the existing table via ALTER TABLE...ADD CONSTRAINT...CHECK, and respectively removed if you run ALTER TABLE...DROP CONSTRAINT...
Another difference between these two types is also their scope. Nullability checks are valid only for one column. On the other hand, the value check is based on SQL expressions. Consequently, it can contain validation rules leveraging several columns and, for example, if-else statements like in the next snippet:
ALTER TABLE demo3 ADD CONSTRAINT numberGreaterThan0OrLetterDifferentThanDots CHECK (CASE WHEN number = 0 THEN letter != 'x' ELSE letter != '..' END)
Execution flow
How do the constraints integrate to the execution flow? The answer is quite simple, wrapping. Whenever you try to write a DataFrame to a table with defined constraints, Delta writer will wrap the initial execution plan with a DeltaInvariantChecker node. You can see an example of the plan wrapped by the invariants checker just below:

Next comes the physical stage where Delta writer transforms constraints definition into real code. Yes, each expression is converted to the code that you can see in the logs. Below you can find an example of the generated code for the numbergreaterthan0 check:
/* 025 */ public UnsafeRow apply(InternalRow i) {
/* 026 */ mutableStateArray_0[0].reset();
/* 027 */
/* 028 */
/* 029 */ mutableStateArray_0[0].zeroOutNullBytes();
/* 030 */
/* 031 */ int value_2 = i.getInt(1);
/* 032 */
/* 033 */ boolean value_1 = false;
/* 034 */ value_1 = value_2 > 0;
/* 035 */
/* 036 */ if (false || value_1 == false) {
/* 037 */ java.util.List<String> colList_0 = new java.util.ArrayList<String>();
/* 038 */ java.util.List<Object> valList_0 = new java.util.ArrayList<Object>();
/* 039 */ colList_0.add("number");
/* 040 */ int value_4 = i.getInt(1);
/* 041 */ if (false) {
/* 042 */ valList_0.add(null);
/* 043 */ } else {
/* 044 */ valList_0.add(value_4);
/* 045 */ }
/* 046 */ throw org.apache.spark.sql.delta.schema.DeltaInvariantViolationException.apply(
/* 047 */ ((org.apache.spark.sql.delta.constraints.Constraints$Check) references[0] /* errMsg */), colList_0, valList_0);
/* 048 */ }
I bet the two lists left you puzzled. When you look at this, you'll see the validation function adding invalid references to both lists but it doesn't mean the validator will apply the checks on top of the whole DataFrame before returning the exception. No, it'll stop at the first error and both lists are there simply to create a nice error message indicating the first row not respecting the constraint:
[DELTA_VIOLATE_CONSTRAINT_WITH_VALUES] CHECK constraint numbergreaterthan0 (number > 0) violated by row with values: - number : -1
Two checks
And what if we define two check constraints and both trigger the validation exception? Let's take a look at the generated code to understand what will happen:
/* 036 */ if (false || value_1 == false) {
/* 037 */ java.util.List<String> colList_0 = new java.util.ArrayList<String>();
/* 038 */ java.util.List<Object> valList_0 = new java.util.ArrayList<Object>();
/* 039 */ colList_0.add("number");
/* 040 */ int value_4 = i.getInt(1);
/* 041 */ if (false) {
/* 042 */ valList_0.add(null);
/* 043 */ } else {
/* 044 */ valList_0.add(value_4);
/* 045 */ }
/* 046 */ throw org.apache.spark.sql.delta.schema.DeltaInvariantViolationException.apply(
/* 047 */ ((org.apache.spark.sql.delta.constraints.Constraints$Check) references[0] /* errMsg */), colList_0, valList_0);
/* 048 */ }
/* 049 */ if (true) {
/* 050 */ mutableStateArray_0[0].setNullAt(0);
/* 051 */ } else {
/* 052 */
/* 053 */ }
/* 054 */
/* 055 */ Object value_12 = CheckDeltaInvariant_0(i);
/* 056 */ if (true) {
/* 057 */ mutableStateArray_0[0].setNullAt(1);
/* 058 */ } else {
/* 059 */
/* 060 */ }
/* 061 */
/* 062 */ boolean isNull_13 = i.isNullAt(0);
/* 063 */ UTF8String value_14 = isNull_13 ?
/* 064 */ null : (i.getUTF8String(0));
/* 065 */
/* 066 */ if (isNull_13) {
/* 067 */ throw org.apache.spark.sql.delta.schema.DeltaInvariantViolationException.apply(
/* 068 */ ((org.apache.spark.sql.delta.constraints.Constraints$NotNull) references[3] /* errMsg */));
/* 069 */ }
// ...
/* 088 */ if (!isNull_9) {
/* 089 */ value_8 = CollationSupport.Upper.execBinaryICU(value_9);
/* 090 */ }
/* 091 */ if (!isNull_8) {
/* 092 */
/* 093 */
/* 094 */ isNull_7 = false; // resultCode could change nullability.
/* 095 */ value_7 = value_8.binaryEquals(((UTF8String) references[1] /* literal */));
/* 096 */
/* 097 */ }
/* 098 */ boolean isNull_6 = isNull_7;
/* 099 */ boolean value_6 = false;
/* 100 */
/* 101 */ if (!isNull_7) {
/* 102 */ value_6 = !(value_7);
/* 103 */ }
/* 104 */
/* 105 */ if (isNull_6 || value_6 == false) {
/* 106 */ java.util.List<String> colList_1 = new java.util.ArrayList<String>();
/* 107 */ java.util.List<Object> valList_1 = new java.util.ArrayList<Object>();
/* 108 */ colList_1.add("letter");
/* 109 */ boolean isNull_11 = i.isNullAt(0);
/* 110 */ UTF8String value_11 = isNull_11 ?
/* 111 */ null : (i.getUTF8String(0));
/* 112 */ if (isNull_11) {
/* 113 */ valList_1.add(null);
/* 114 */ } else {
/* 115 */ valList_1.add(value_11);
/* 116 */ }
/* 117 */ throw org.apache.spark.sql.delta.schema.DeltaInvariantViolationException.apply(
/* 118 */ ((org.apache.spark.sql.delta.constraints.Constraints$Check) references[2] /* errMsg */), colList_1, valList_1);
/* 119 */ }
As you can notice the fail-fast approach is still in place. Delta writer stops at the first encountered error. It won't help you by applying all the checks to validate the failed row completely. As a consequence, if you rely on the constraints to discover all errors your DataFrame might have, this process can take time because you'll need to restart it at the first encountered error. In that case it's better to transform the constraints into filters and save all invalid rows for further analysis. At least you can do it in a single shot.
Adding a constraints to existing data
Besides multiple constraints, there is another aspect to consider, constraints evolution, i.e. what happens when you adds a constraints to a non-empty table. The answer is - you know, I'm a freelance consultant and someone said it's one of the consultant's favorite sayings - it depends. Two things can happen when you add a constraint to a not empty table:
- If all rows don't break the constraint, the constraint is correctly added.
- If there is at least on row breaking the validation rule, the ADD CONSTRAINT fails but this time with a different error:
[DELTA_NEW_CHECK_CONSTRAINT_VIOLATION] 3 rows in spark_catalog.default.demo2 violate the new CHECK constraint (number > 10)
If you analyze the stack trace you'll quickly realize the error is related to the ALTER TABLE command that evaluates the constraint candidate on top of existing data:
case class AlterTableAddConstraintDeltaCommand(
table: DeltaTableV2,
name: String,
exprText: String) extends AlterTableConstraintDeltaCommand {
override def run(sparkSession: SparkSession): Seq[Row] = {
// ...
val n = df.where(Column(Or(Not(unresolvedExpr), IsUnknown(unresolvedExpr)))).count()
if (n > 0) {
throw DeltaErrors.newCheckConstraintViolated(n, table.name(), exprText)
}
Orphan files
The last point I wanted to check for this blog post were orphan files, you know those files in your table's location that are not connected to any commit log, for example after the OPTIMIZE operation or a failed write where only some of the tasks succeeded.
Constraints validation for the performance reasons is part of the writing process. Since it breaks at the first encountered error, a failed write due to the constraints violation can leave orphan files behind. If you want to test it, you can check out the demoavailable on my Github.
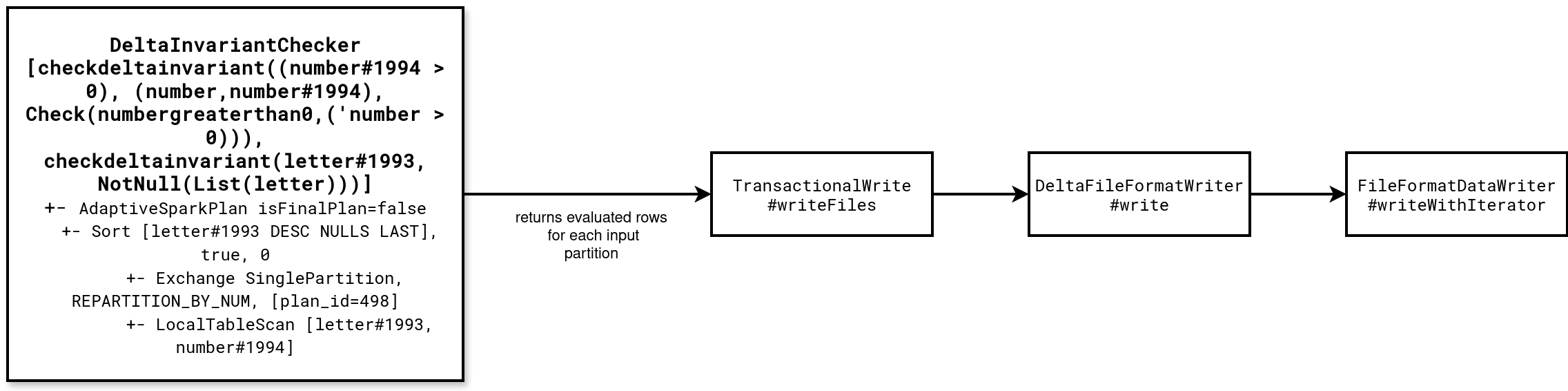
You can also check the source code to analyze the constraints evaluation at writing. The next schema summarizes the execution stack where the DeltaInvariantCheckerExec wraps each row passed to the task-based writer without creating a separated stage:
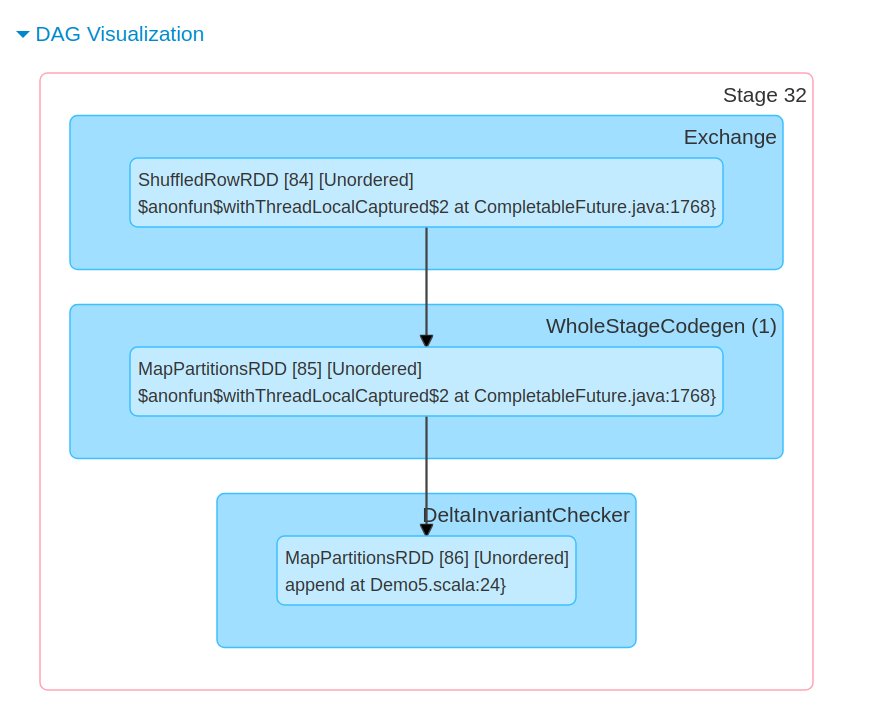
You can also see the common stage for writing and checking in Spark UI:
📌 Integrity constraints
As of this writing they're still informational. For that reason, I will try to cover them later.
Constraints have been the topic I wanted to cover for a long time. Thankfully, this time has come and I could answer all the questions waiting patiently in my head. Hopefully, it's somehow useful to you as well!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩