
The previous blog from the series we discovered streaming reader. However, an end-to-end streaming Delta Lake pipeline also requires a writer which will be our focus today.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Commit
Commit log is one of Delta Lake's powerful features and at the same time, one of the most challenging ones. After all, Apache Spark is a distributed data processing framework and synchronizing the work in that context has never been easy. However, Apache Spark has solved this problem many years ago with the _SUCCESS file marker and I already blogged about this in the Apache Spark's _SUCESS anatomy. Turns out, Delta Lake writer relies on the same classes, as shown in the schema below:
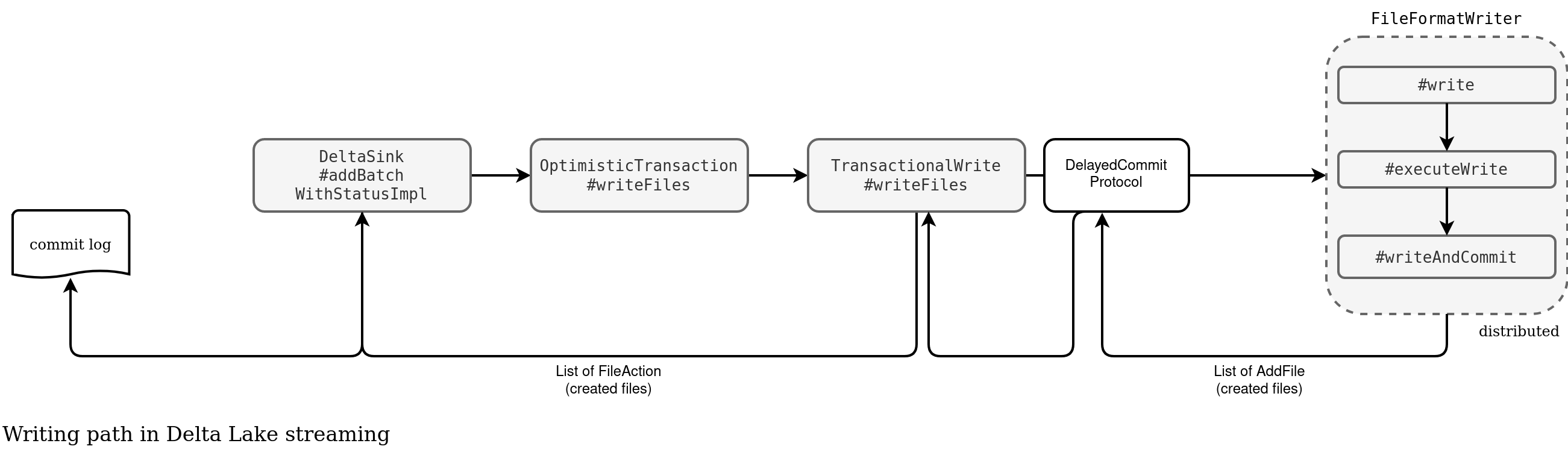
The upper arrows show the forward actions while the bottom ones the feedback ones. As you can see, at some point the writer creates a DelayedCommitProtocol that tracks all files physically created on the executors (rightmost side):
class DelayedCommitProtocol(
// ...
@transient val addedStatuses = new ArrayBuffer[AddFile]
override def commitJob(jobContext: JobContext, taskCommits: Seq[TaskCommitMessage]): Unit = {
val (addFiles, changeFiles) = taskCommits.flatMap(_.obj.asInstanceOf[Seq[_]])
.partition {
case _: AddFile => true
case _: AddCDCFile => false
case other =>
throw DeltaErrors.unrecognizedFileAction(s"$other", s"${other.getClass}")
}
// we cannot add type information above because of type erasure
addedStatuses ++= addFiles.map(_.asInstanceOf[AddFile])
this.changeFiles ++= changeFiles.map(_.asInstanceOf[AddCDCFile]).toArray[AddCDCFile]
}
The protocol intercepts all commit messages produced for each task with the list of written files. It passes them to the DeltaSink#addBatchWithStatusImpl where Delta Lake creates the commit log file combining added and removed files:
// case class DeltaSink
private def addBatchWithStatusImpl(batchId: Long, data: DataFrame): Boolean = {
val txn = deltaLog.startTransaction(catalogTable)
// ...
val info = DeltaOperations.StreamingUpdate(outputMode, queryId, batchId, options.userMetadata)
val pendingTxn = PendingTxn(batchId, txn, info, newFiles, deletedFiles)
pendingTxn.commit()
This is the happy path but as you know, things often go wrong, especially in distributed systems. How does Delta Lake writer handle retries or failed transactions?
Retries and failures
For the retries, it's easier than you think. When a task fails, it simply doesn't send the commit message (TaskCommitMessage):
// FileFormatWriter
private[spark] def executeTask(
// ...
committer.setupTask(taskAttemptContext)
// ...
try {
Utils.tryWithSafeFinallyAndFailureCallbacks(block = {
// Execute the task to write rows out and commit the task.
dataWriter.writeWithIterator(iterator)
dataWriter.commit()
})(catchBlock = {
// If there is an error, abort the task
dataWriter.abort()
logError(s"Job $jobId aborted.")
}, finallyBlock = {
dataWriter.close()
})
As a result, the temporary files being written are lost from the Delta Lake transactional perspective. However, the files are not cleaned.
Retries task, if it succeeds, automatically overcomes the failed results of its predecessors. But what about a failed writing job? Here the impact will be different if the failure is caused by a partial failure, so a job with both succeeded and failed tasks. If that happens, your Delta table will have some named files that don't belong to any commit in the commit log.
Below you can find what happens when the writer fails. Agree, I'm simulating pretty weird case of an already existing file but the point is to show that in case of any error, you'll be left with orphan data files:
Now, you understand better why the VACUUM command is so important, even if you don't run any OPTIMIZE job for a while.
Idempotent writes
Delta Lake writer has a special mode called idempotent writer. A quick look at the DeltaOptions explains it well:
// DeltaWriteOptionsImpl
val txnVersion = options.get(TXN_VERSION).map { str =>
Try(str.toLong).toOption.filter(_ >= 0).getOrElse {
throw DeltaErrors.illegalDeltaOptionException(TXN_VERSION, str, "must be a non-negative integer")
}
}
val txnAppId = options.get(TXN_APP_ID)
private def validateIdempotentWriteOptions(): Unit = {
// Either both txnVersion and txnAppId must be specified to get idempotent writes or
// neither must be given. In all other cases, throw an exception.
val numOptions = txnVersion.size + txnAppId.size
if (numOptions != 0 && numOptions != 2) {
throw DeltaErrors.invalidIdempotentWritesOptionsException("Both txnVersion and txnAppId "
"must be specified for idempotent data frame writes")
}
validateIdempotentWriteOptions()
From the snippet you can learn that an idempotent writer expects txnVersion and txnAppId defined. Idempotent writer is typically useful in the fan-out data distribution when Spark writes one dataset into multiple Delta tables from the foreachBatch operation. If one of the writes fails and you restart the job, Delta writer will skip the tables with the given app id and version committed. Sounds familiar? That's how writing skipping for file sink works!
The control check comes from the hasBeenExecuted inherited in WriteIntoDelta:
// WriteIntoDelta
override def run(sparkSession: SparkSession): Seq[Row] = {
deltaLog.withNewTransaction(catalogTableOpt) { txn =>
if (hasBeenExecuted(txn, sparkSession, Some(options))) {
return Seq.empty
}
val actions = write(txn, sparkSession)
val operation = DeltaOperations.Write(mode, Option(partitionColumns),
options.replaceWhere, options.userMetadata)
txn.commitIfNeeded(actions, operation)
}
Seq.empty
}
These app id and versions are written to the commit log as a transactional context:
$ cat /tmp/delta_table2/_delta_log/00000000000000000000.json
...
{"txn":{"appId":"1-2-3-4","version":0,"lastUpdated":1705841607000}}
...
When the feature is used, you'll see the logs like ("1-2-3-4" is the txnAppId):
INFO Already completed batch 0 in application 1-2-3-4. This will be skipped. (org.apache.spark.sql.delta.commands.WriteIntoDelta:60)
Idempotent writers are then a great way to improve end-to-end data quality, exactly as schemas are. But if you remember, schemas were one of the challenging points in the streaming reads. How they look for the writers?
Schemas
DeltaSink gives some hints for the schema management just before writing the files:
// DeltaSink // Streaming sinks can't blindly overwrite schema. See Schema Management design doc for details updateMetadata(data.sparkSession, txn, data.schema, partitionColumns, Map.empty, outputMode == OutputMode.Complete(), rearrangeOnly = false)
The highlighted method not only updates the schema but also throws an error if the writing schema is incompatible with the existing one. However, it only happens if you turned the mergeSchema or overwriteSchema flag off. The failure detects incompatibilities between table fields and partitioning columns.
When you introduced some schema issues, Delta Lake will quickly notify you with the errors like this one:
Caused by: org.apache.spark.sql.AnalysisException: A schema mismatch detected when writing to the Delta table (Table ID: 57f95aec-d081-4824-8994-d0a92cc3dd00).
To enable schema migration using DataFrameWriter or DataStreamWriter, please set:
'.option("mergeSchema", "true")'.
For other operations, set the session configuration
spark.databricks.delta.schema.autoMerge.enabled to "true". See the documentation
specific to the operation for details.
Table schema:
root
-- timestamp: timestamp (nullable = true)
-- value: long (nullable = true)
-- old_column: string (nullable = true)
Data schema:
root
-- timestamp: timestamp (nullable = true)
-- value: long (nullable = true)
-- new_column: string (nullable = true)
An important thing to notice is that using the options may not be enough for streaming. Overwriting schema works only if you defined the job's output mode to Complete, as shows the source code:
// DeltaSink override protected val canOverwriteSchema: Boolean = outputMode == OutputMode.Complete() && options.canOverwriteSchema
The problem is, this mode is only supported for a specific type of job. If you run a simple transformation job, you'll end up with the exception like this:
Exception in thread "main" org.apache.spark.sql.AnalysisException: Complete output mode not supported when there are no streaming aggregations on streaming DataFrames/Datasets; Project [timestamp#0, array(a, b) AS value#4] +- StreamingRelationV2 org.apache.spark.sql.execution.streaming.sources.RatePerMicroBatchProvider@3ea9a091, rate-micro-batch, org.apache.spark.sql.execution.streaming.sources.RatePerMicroBatchTable@45c408a4, [rowsPerBatch=500, advanceMillisPerMicroBatch=120000, startTimestamp=1653474300000, numPartitions=10], [timestamp#0, value#1L]
Besides the schema options, Delta Lake streaming writer supports maxRecordsPerFile and compression. Both are relatively easy to understand so I won't detail them much in this blog post. Instead, you can see them in action in the Github repo. I'm not done with Delta Lake exploration yet but I'm taking a short break from it now to focus on Apache Flink concepts. See you next time!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩