
Even though I'm into streaming these days, I haven't really covered streaming in Delta Lake yet. I only slightly blogged about Change Data Feed but completely missed the fundamentals. Hopefully, this and next blog posts will change this!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Streaming a Delta Lake table is relatively easy from the end user's perspective. All you have to do is to use the stream API as in the example below:
// Batch
sparkSession.table(tableName).show(truncate = false)
// Streaming
sparkSession.readStream.format("delta").table(tableName)
Although this high level looks like the difference is small, many other interesting things happened under-the-hood. Let's see some of them.
DeltaSource
When you issue a readStream.format("delta") you indirectly call the streaming functions exposed by the DeltaSource class:

The first 2 calls are part of a standard path for Structured Streaming data sources execution. Delta-specific points start from the createSource method where these 2 important actions for the rest of processing happen:
- DeltaLog and Snapshot preparation at the latest version of the table. The latest version is intentional because the stream evaluates against the most recent schema.
- Schema resolution. Even though one of the function's parameters is schema: Option[StructType], users are not allowed to define a custom schema because their queries will throw an exception:
Exception in thread "main" org.apache.spark.sql.delta.DeltaAnalysisException: [DELTA_UNSUPPORTED_SCHEMA_DURING_READ] Delta does not support specifying the schema at read time.
The schema comes either from the schema metadata files (schema tracking must be enabled) or from the table snapshot associated to the query.
Planning the offsets
The first step for the streaming reader is to get the starting position. If the query has already been running it's easy as the information comes from the checkpoint files. Otherwise, there are 2 alternative ways. The time-travel if you set the startingVersion or startingTimestamp options, or the default one if you set nothing in the options.
We could stop here but Delta Lake has another options impacting this very first stage, the rate limits. You can configure either the max data size or max number of files to read with, respectively, maxBytesPerTrigger and maxFilesPerTrigger. If you don't set, by default Delta Lake will limit your reader to 1000 files. But beware, these "files" are data files and not the commits! Moreover, the bytes limit is an approximate one because it analyzes the size of the whole file defined in the commit log:
def admit(fileAction: Option[FileAction]): Boolean = {
// ...
def getSize(action: FileAction): Long = {
action match {
case a: AddFile =>
a.size
case r: RemoveFile =>
r.size.getOrElse(0L)
case cdc: AddCDCFile =>
cdc.size
}
}
val shouldAdmit = hasCapacity
if (fileAction.isEmpty) {
return shouldAdmit
}
take(files = 1, bytes = getSize(fileAction.get))
// ...
}
protected def take(files: Int, bytes: Long): Unit = {
filesToTake -= files
bytesToTake -= bytes
}
Default limit
Delta Lake data source class implements the SupportsAdmissionControl interface used by the micro-batch executor to get the default limit, defined as follows for Delta Lake:
// DeltaSource
override def getDefaultReadLimit: ReadLimit = {
AdmissionLimits().toReadLimit
}
// AdmissionLimits
// this one is called by the admit function referenced above
var filesToTake = maxFiles.getOrElse {
if (options.maxBytesPerTrigger.isEmpty) {
DeltaOptions.MAX_FILES_PER_TRIGGER_OPTION_DEFAULT
} else {
Int.MaxValue - 8 // - 8 to prevent JVM Array allocation OOM
}
}
def toReadLimit: ReadLimit = {
if (options.maxFilesPerTrigger.isDefined && options.maxBytesPerTrigger.isDefined) {
CompositeLimit(
ReadMaxBytes(options.maxBytesPerTrigger.get),
ReadLimit.maxFiles(options.maxFilesPerTrigger.get).asInstanceOf[ReadMaxFiles])
} else if (options.maxBytesPerTrigger.isDefined) {
ReadMaxBytes(options.maxBytesPerTrigger.get)
} else {
ReadLimit.maxFiles( options.maxFilesPerTrigger.getOrElse(DeltaOptions.MAX_FILES_PER_TRIGGER_OPTION_DEFAULT))
}
}
// DeltaOptions
val MAX_FILES_PER_TRIGGER_OPTION_DEFAULT = 1000
Consequently, if none of the throughput control options is present, by default Delta Lake will read 1000 files.
Offsets, indexes, and reservoirs
The Delta Lake's offsets introduce a reservoir concept which turns out to be a legacy name for a Delta table (Jacek explains it greatly in his Delta Lake internals book). You can find this, and a few other attributes, in the Delta-specific offset class:
case class DeltaSourceOffset private(
sourceVersion: Long,
reservoirId: String, reservoirVersion: Long,
index: Long, isStartingVersion: Boolean
) extends Offset with Comparable[DeltaSourceOffset] {
Among the attributes you'll find:
- sourceVersion is the serialization version for a given offset. The version number 3 supports schema change index values and is involved in the schema tracking presented in the end of the blog post.
- reservoirId and reservoirVersion are respectively, the table id and the table version (aka commit log file name)
- index is the file's position in the commit log
- isStartingVersion is the boolean flag marking the offset as coming from the first micro-batch execution for the reader
Getting the data
Next it comes data retrieval from the selected files, hence the DataFrame creation.

Let's focus on the rightmost box of the schema. The first step here is to get all files included between the starting and ending offsets by calling the same method as for applying the rate limits, the getFileChanges. The single difference is that for data retrieval, the ending offset is always defined while for the rate limit, it's empty since the max options control when to stop reading:
protected def getFileChangesAndCreateDataFrame
// ...
val fileActionsIter = getFileChanges(
startVersion, startIndex, isStartingVersion, endOffset = Some(endOffset)
)
At this moment it's worth mentioning the index generation. If you look at the commit log's content, you'll see there is any index mention for the files part. It's a runtime property generated as an auto-incremented number individually for each file. Here is the snippet:
private def filterAndGetIndexedFiles(iterator: Iterator[Action], version: Long,
// ...
): Iterator[IndexedFile] = {
// ...
var index = -1L
val indexedFiles = new Iterator[IndexedFile] {
override def hasNext: Boolean = filteredIterator.hasNext
override def next(): IndexedFile = {
index += 1 // pre-increment the index (so it starts from 0)
val add = filteredIterator.next().copy(stats = null)
IndexedFile(version, index, add, isLast = !filteredIterator.hasNext)
}
}
// ...
However, this operation only returns the files so called IndexedFiles, included in the offsets range. It's only the next method, createDataFrame(indexedFiles: Iterator[IndexedFile]) that converts those files into a DataFrame. It has to deal with 2 situations. The first one is relatively easy as it takes all the files and forwards the DataFrame creation to the DeltaLog#createDataFrame with the streaming flag (isStreaming) set to true. Under-the-hood, the function reads the content of the files and exposes it as a DataFrame:
// DeltaLog#createDataFrame val fileIndex = new TahoeBatchFileIndex(spark, actionType, addFiles, this, dataPath, snapshot) val relation = buildHadoopFsRelationWithFileIndex(snapshot, fileIndex, bucketSpec = None) Dataset.ofRows(spark, LogicalRelation(relation, isStreaming = isStreaming))
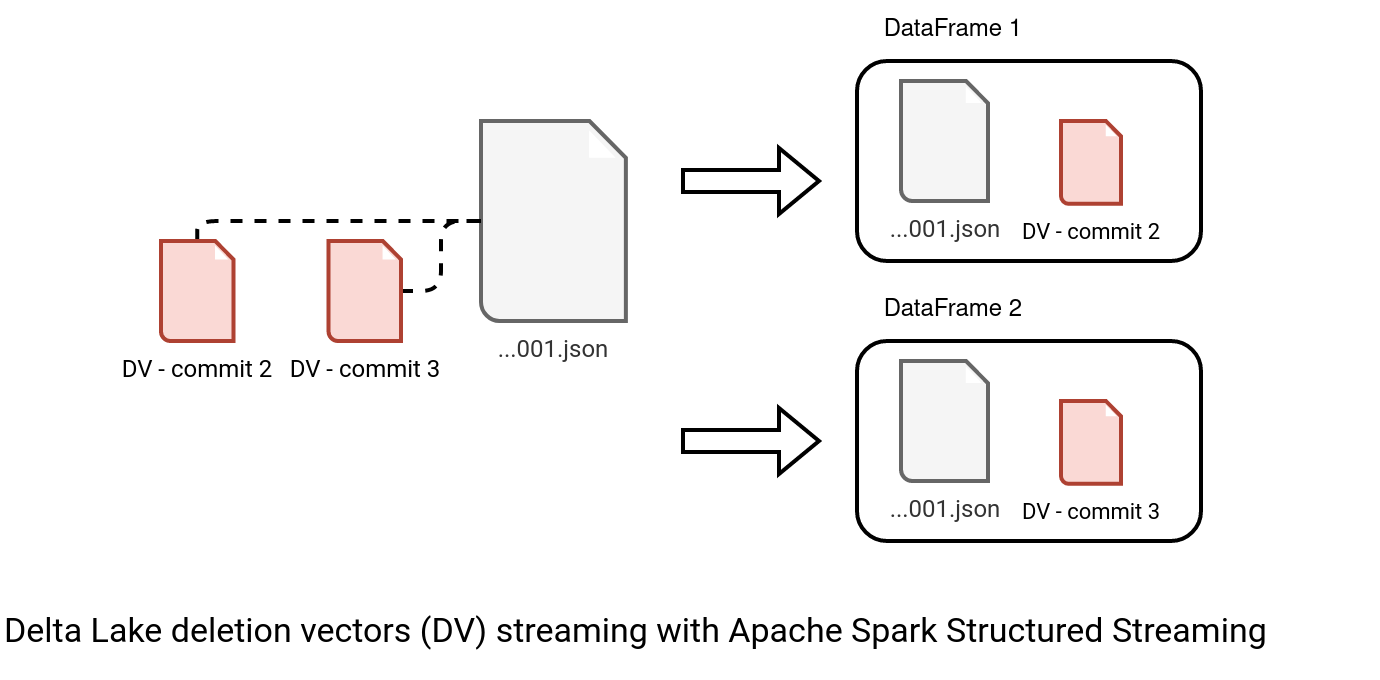
But it's not that simple for the second scenario which happens if any of the files has a deletion vector. It's not a pure streaming feature but has an impact on reading. Without deletion vector, Delta Lake overwrites all the files with rows modified by in-place operations (UPDATE, DELETE). It's the Copy-on-Write strategy. With deletion vectors, the commit writes only the modified rows and leaves the responsibility for getting the most recent version to the readers. Hence the Merge-on-Read. For that reason, the streaming reader can't directly use the indexed files.
The specificity for the deletion vectors comes from the technical limitation and is clearly explained in the comment:
if (hasDeletionVectors) {
// Read AddFiles from different versions in different scans.
// This avoids an issue where we might read the same file with different deletion vectors in
// the same scan, which we cannot support as long we broadcast a map of DVs for lookup.
// This code can be removed once we can pass the DVs into the scan directly together with the
// AddFile/PartitionedFile entry.
addFiles.groupBy(_.version).values
.map { addFilesList =>
deltaLog.createDataFrame(readSnapshotDescriptor,
addFilesList.map(_.getFileAction.asInstanceOf[AddFile]),
isStreaming = true)
}
.reduceOption(_ union _)
In other words, it creates one DataFrame for each commit version instead of one common DataFrame for all version if there is no deletion vectors:
Starting version
Very often in the code you'll find a reference to a starting version. The getBatch resolves this flag from the extractStartingState alongside the start commit and start index to read from. The flag is hardcoded to true only for the real first micro-batch execution if you don't specify the time-travel options.
The flag later goes to the getFileChanges via createDataFrameBetweenOffsets. It's used there to reload the snapshot:
// DeltaSource#getFileChanges
var iter = if (isStartingVersion) {
Iterator(1, 2).flatMapWithClose { // so that the filterAndIndexDeltaLogs call is lazy
case 1 => getSnapshotAt(fromVersion).toClosable
case 2 => filterAndIndexDeltaLogs(fromVersion + 1)
}
} else {
filterAndIndexDeltaLogs(fromVersion)
}
Why this new snapshot retrieval? Remember the first part of the blog post? Yes, the reader first uses the most recent table snapshot and its schema which might not correspond to the version in the data reading part. Consequently, getting a new snapshot may result in a schema error but I let you discover this schema part at the end of the blog post.
Configuration properties
The time-travel and rate limit options are not the single configuration properties. Besides them you can use:
- excludeRegex - I didn't find an official mention in the documentation but looks like an option to exclude some data files from the output DataFrame:
// DeltaSourceBase#getFileChangesAndCreateDataFrame // … val filteredIndexedFiles = fileActionsIter.filter { indexedFile => indexedFile.getFileAction != null && excludeRegex.forall(_.findFirstIn(indexedFile.getFileAction.path).isEmpty) } createDataFrame(filteredIndexedFiles)The snippet below excludes all input files of a table:
sparkSession.readStream.format("delta") .option("startingVersion", 0) .option("excludeRegex", "part-000") // Exclude all files .table(NumbersWithLettersTable) .writeStream.format("console").start() - ignoreChanges - a boolean flag to enable or disable ignoring data-based in-place operations, such as deletes in multiple partitions (partition is missing in the WHERE condition)
- ignoreDeletes - a boolean flag to enable or disable ignoring partition-based deletes (partition column present in the WHERE condition).
Append-only log table?
Delta Lake supports append-only tables where only insert operations are permitted. Streaming them is slightly easier as you don't need to worry about data changes.
To create an append-only table, set the delta.appendOnly property to true.
Thank you, Scott, for sharing this tidbit.
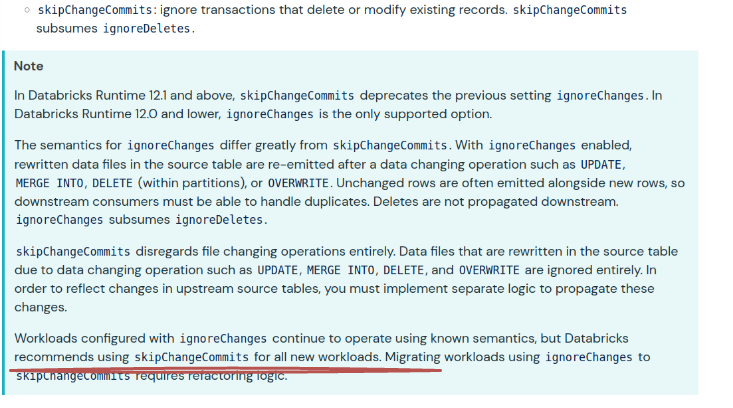
- skipChangeCommits - a boolean flag to enable or disable processing of the transactions modifying the existing data with updates or deletes. It includes ignoreDeletes and is recommended for all workloads:
⚠ Errors on updates
Although the skipChangeCommits option is optional and it defaults to false, leaving it empty will lead to stream failures with the errors like:
[DELTA_SOURCE_TABLE_IGNORE_CHANGES] Detected a data update (for example part-00000-b8eb5cef-5254-46d5-937a-0d935bf23b3a-c000.snappy.parquet) in the source table at version 1. This is currently not supported. If you'd like to ignore updates, set the option 'skipChangeCommits' to 'true'. If you would like the data update to be reflected, please restart this query with a fresh checkpoint directory.
If you want to read updates, a quick fix would be enabling the readChangeFeed:
sparkSession.readStream.format("delta") .option("startingVersion", 0) .option("skipChangeCommits", false) .option("readChangeFeed", true) - failOnDataLoss - enables or disables failure on the data loss. Data loss occurs when the reader doesn't process 2 consecutive commits logs, i.e. when current commit log > last commit log + 1.
- ...and of course the ones related to the Change Data Feed feature but for them I invite you to one of my previous blog posts Table file formats - Change Data Capture: Delta Lake
- ...and finally, I don't include the schema tracking options here as they deserve a separate explanation
These skip or ignore flags are key to understand why getting files for the micro-batch involves this function:
protected def validateCommitAndDecideSkipping(
actions: Iterator[Action], version: Long,
batchStartVersion: Long, batchEndVersionOpt: Option[Long] = None,
verifyMetadataAction: Boolean = true): (Boolean, Option[Metadata], Option[Protocol]) = {
/// ...
val shouldAllowChanges = options.ignoreChanges || ignoreFileDeletion || skipChangeCommits
val shouldAllowDeletes = shouldAllowChanges || options.ignoreDeletes || ignoreFileDeletion
/// ...
if (removeFileActionPath.isDefined) {
if (seenFileAdd && !shouldAllowChanges) {
throw DeltaErrors.deltaSourceIgnoreChangesError(version, removeFileActionPath.get,
deltaLog.dataPath.toString
)
} else if (!seenFileAdd && !shouldAllowDeletes) {
throw DeltaErrors.deltaSourceIgnoreDeleteError(version, removeFileActionPath.get,
deltaLog.dataPath.toString
)
}
}
Schema incompatibilities
When you use an Apache Spark Structured Streaming job for Delta Lake you must be careful when the streamed table evolves the schema. If it gets a new column, that shouldn't be a problem as you planned the job to deal with some specific data structure. However, it's not the case and when the table changes, you'll encounter an, as in the snippets below where the table renamed the "number" column to the "id_number"...:
org.apache.spark.sql.streaming.StreamingQueryException: [DELTA_SCHEMA_CHANGED_WITH_VERSION] Detected schema change in version 3: streaming source schema: root -- number: integer (nullable = true) -- letter: string (nullable = true) data file schema: root -- id_number: integer (nullable = true) -- letter: string (nullable = true) Please try restarting the query. If this issue repeats across query restarts without making progress, you have made an incompatible schema change and need to start your query from scratch using a new checkpoint directory.
...and here the error when a new column was added:
[DELTA_SCHEMA_CHANGED_WITH_VERSION] Detected schema change in version 1: streaming source schema: root -- number: integer (nullable = true) -- letter: string (nullable = true) data file schema: root -- number: integer (nullable = true) -- letter: string (nullable = true) -- upper_letter: string (nullable = true) Please try restarting the query. If this issue repeats across query restarts without making progress, you have made an incompatible schema change and need to start your query from scratch using a new checkpoint directory.
As the last error recovers by itself after relaunching the job, let's focus on the first one..
Here, the streaming job has been operating on the table with the following operations: table creation => schema evolution by adding a new column => schema evolution by renaming an existing and streamed column. As you can deduce, this workflow records not only the data but also the metadata operations in the commit log:
$ grep "metaData" numbers_with_letters/_delta_log/*
# numbers_with_letters/_delta_log/00000000000000000000.json
{"commitInfo":{"timestamp":1704618048658,"operation":"CREATE OR REPLACE TABLE AS SELECT","operationParameters":{"isManaged":"true","description":null,"partitionBy":"[]","properties":"{\"delta.enableChangeDataFeed\":\"true\"}"},"isolationLevel":"Serializable","isBlindAppend":false,"operationMetrics":{"numFiles":"1","numOutputRows":"4","numOutputBytes":"705"},"engineInfo":"Apache-Spark/3.5.0 Delta-Lake/3.0.0","txnId":"0563cc31-789b-44f5-b48b-f7094f07daf2"}}
{"metaData":{"id":"d3219e3c-fce8-4f4e-9ca8-dc53e45d9890","format":{"provider":"parquet","options":{}},"schemaString":"{\"type\":\"struct\",\"fields\":[{\"name\":\"number\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{}},{\"name\":\"letter\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}}]}","partitionColumns":[],"configuration":{"delta.enableChangeDataFeed":"true"},"createdTime":1704618045295}}
# numbers_with_letters/_delta_log/00000000000000000002.json
{"commitInfo":{"timestamp":1704618069524,"operation":"RENAME COLUMN","operationParameters":{"oldColumnPath":"number","newColumnPath":"id_number"},"readVersion":1,"isolationLevel":"Serializable","isBlindAppend":true,"operationMetrics":{},"engineInfo":"Apache-Spark/3.5.0 Delta-Lake/3.0.0","txnId":"044b6e69-317a-47fb-8a0f-d57962b4b2c7"}}
{"metaData":{"id":"d3219e3c-fce8-4f4e-9ca8-dc53e45d9890","format":{"provider":"parquet","options":{}},"schemaString":"{\"type\":\"struct\",\"fields\":[{\"name\":\"id_number\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{\"delta.columnMapping.id\":1,\"delta.columnMapping.physicalName\":\"number\"}},{\"name\":\"letter\",\"type\":\"string\",\"nullable\":true,\"metadata\":{\"delta.columnMapping.id\":2,\"delta.columnMapping.physicalName\":\"letter\"}}]}","partitionColumns":[],"configuration":{"delta.enableChangeDataFeed":"true","delta.columnMapping.mode":"name","delta.columnMapping.maxColumnId":"2"},"createdTime":1704618045295}}
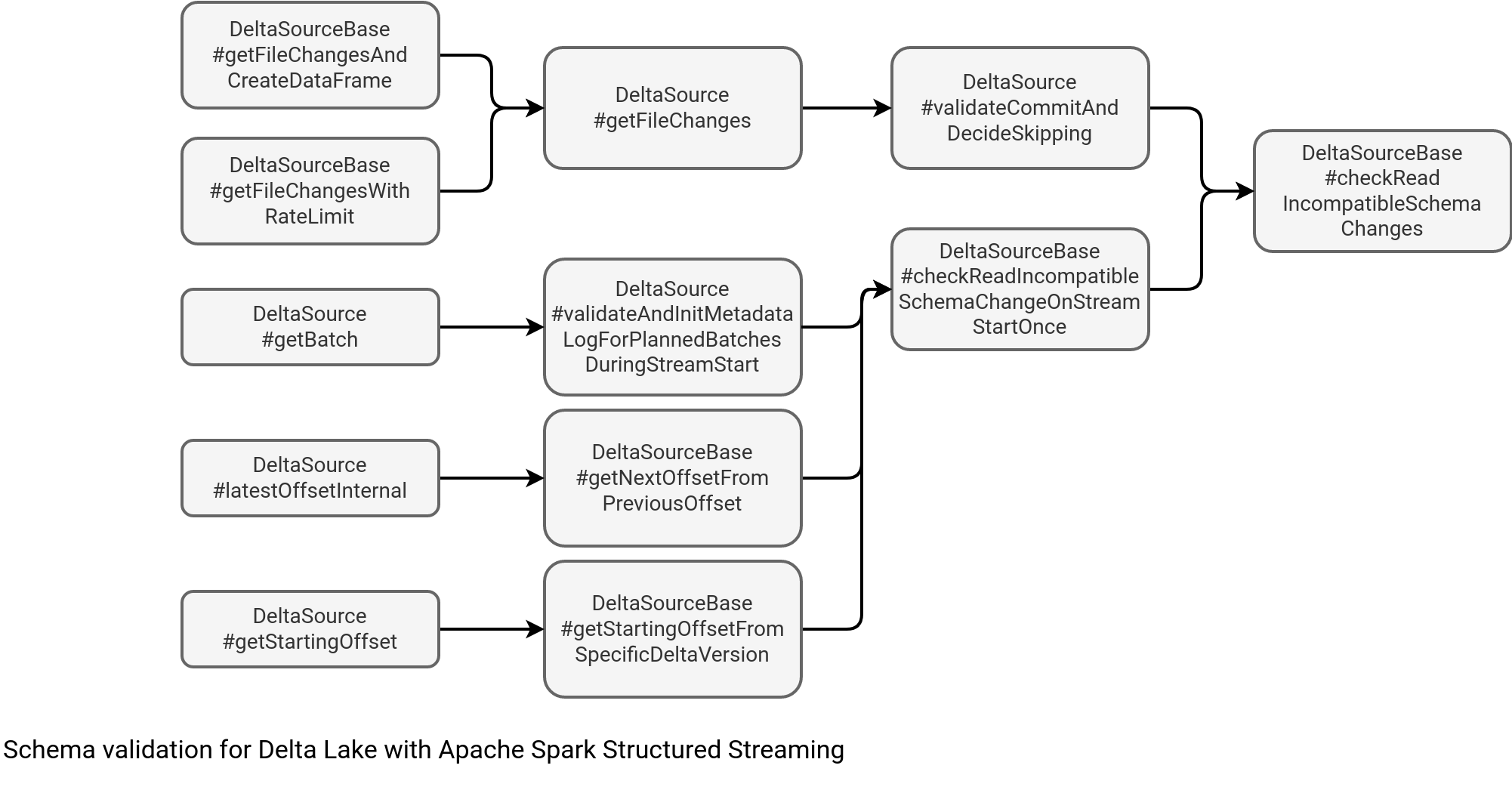
How does it impact the streaming reader? After all, it processes data and might ignore the metadata. That is unfortunately not true as the metadata operations are a part of the streaming reader:
# DeltaSource#validateCommitAndDecideSkipping(actions: Iterator[Action], ...)
actions.foreach {
case m: Metadata =>
if (verifyMetadataAction) {
checkReadIncompatibleSchemaChanges(m, version, batchStartVersion,
batchEndVersionOpt)
}
assert(metadataAction.isEmpty,
"Should not encounter two metadata actions in the same commit")
metadataAction = Some(m)
The highlighted method is the one responsible for verifying the schema compatibility:
// #checkReadIncompatibleSchemaChanges
// ...
if (!SchemaUtils.isReadCompatible(schemaChange, schema,
forbidTightenNullability = shouldForbidTightenNullability,
allowMissingColumns = isStreamingFromColumnMappingTable &&
allowUnsafeStreamingReadOnColumnMappingSchemaChanges &&
backfilling,
newPartitionColumns = newMetadata.partitionColumns,
oldPartitionColumns = oldMetadata.partitionColumns
)) {
val retryable = !backfilling && SchemaUtils.isReadCompatible(
schema, schemaChange, forbidTightenNullability = shouldForbidTightenNullability)
throw DeltaErrors.schemaChangedException(
schema,
schemaChange,
retryable = retryable,
Some(version),
includeStartingVersionOrTimestampMessage = options.containsStartingVersionOrTimestamp)
}
And this method is quite popular by the way. If you analyze the invocation tree, you'll find many places relying on it to see whether the stream can move on.
Now the question is, will it break also with the column mapping? After all, it's there to enable schema evolution scenarios including renaming or dropping columns.
Schema tracking
The answer is yes, but before ending this article, let's see why. First thing to do if you want to enable column mapping for streaming readers, besides setting the former on the table, is to define a schemaTrackingLocation on each streamed table. An important requirement here is the location itself that must be within the checkpoint location. Otherwise, you'll get this error:
Exception in thread "Thread-43" org.apache.spark.sql.delta.DeltaAnalysisException: [DELTA_STREAMING_SCHEMA_LOCATION_NOT_UNDER_CHECKPOINT] Schema location '/tmp/checkpoint1704602355716d/schema_tracking/_schema_log_89f5928a-83fc-48d4-a1c3-c55ab8a36043' must be placed under checkpoint location 'file:/tmp/checkpoint1704602355716'.
The feature will create a schema_tracking directory under the checkpoint location and write there all recorded schema changes. Below you can find two files created after renaming a column from number to id_number:
# schema_tracking/_schema_log_e756583b-b765-4810-a191-d19893e54aa8/0
{"tableId":"e756583b-b765-4810-a191-d19893e54aa8","deltaCommitVersion":1,"dataSchemaJson":"{\"type\":\"struct\",\"fields\":[{\"name\":\"number\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{\"delta.columnMapping.id\":1,\"delta.columnMapping.physicalName\":\"number\"}},{\"name\":\"letter\",\"type\":\"string\",\"nullable\":true,\"metadata\":{\"delta.columnMapping.id\":2,\"delta.columnMapping.physicalName\":\"letter\"}}]}","partitionSchemaJson":"{\"type\":\"struct\",\"fields\":[]}","sourceMetadataPath":"file:/tmp/checkpoint1/sources/0","tableConfigurations":{"delta.enableChangeDataFeed":"true","delta.columnMapping.mode":"name","delta.columnMapping.maxColumnId":"2"},"protocolJson":"{\"protocol\":{\"minReaderVersion\":2,\"minWriterVersion\":5}}"}
# schema_tracking/_schema_log_e756583b-b765-4810-a191-d19893e54aa8/1
{"tableId":"e756583b-b765-4810-a191-d19893e54aa8","deltaCommitVersion":2,"dataSchemaJson":"{\"type\":\"struct\",\"fields\":[{\"name\":\"id_number\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{\"delta.columnMapping.id\":1,\"delta.columnMapping.physicalName\":\"number\"}},{\"name\":\"letter\",\"type\":\"string\",\"nullable\":true,\"metadata\":{\"delta.columnMapping.id\":2,\"delta.columnMapping.physicalName\":\"letter\"}}]}","partitionSchemaJson":"{\"type\":\"struct\",\"fields\":[]}","sourceMetadataPath":"file:/tmp/checkpoint1/sources/0","tableConfigurations":{"delta.enableChangeDataFeed":"true","delta.columnMapping.mode":"name","delta.columnMapping.maxColumnId":"2"},"protocolJson":"{\"protocol\":{\"minReaderVersion\":2,\"minWriterVersion\":5}}"}
Despite this metadata present in the checkpoint location, you won't be able to restart the stream. But when you do, Delta Lake will give you a choice to continue by showing this error message:
Caused by: org.apache.spark.sql.delta.DeltaRuntimeException: [DELTA_STREAMING_CANNOT_CONTINUE_PROCESSING_POST_SCHEMA_EVOLUTION] We've detected one or more non-additive schema change(s) (RENAME COLUMN) between Delta version 1 and 2 in the Delta streaming source. Please check if you want to manually propagate the schema change(s) to the sink table before we proceed with stream processing using the finalized schema at 2. Once you have fixed the schema of the sink table or have decided there is no need to fix, you can set (one of) the following SQL configurations to unblock the non-additive schema change(s) and continue stream processing. To unblock for this particular stream just for this series of schema change(s): set `spark.databricks.delta.streaming.allowSourceColumnRenameAndDrop.ckpt_-921269974 = 2`. To unblock for this particular stream: set `spark.databricks.delta.streaming.allowSourceColumnRenameAndDrop.ckpt_-921269974 = always` To unblock for all streams: set `spark.databricks.delta.streaming.allowSourceColumnRenameAndDrop = always`. Alternatively if applicable, you may replace the `allowSourceColumnRenameAndDrop` with `allowSourceColumnRename` in the SQL conf to unblock stream for just this schema change type.
Once you put one of the configurations, you'll be able to resume streaming:
val sparkSession = getDeltaLakeSparkSession(extraConfig = Map( "spark.databricks.delta.streaming.allowSourceColumnRenameAndDrop" -> "always" ))
Why not allow this by default? The problem is that the stream job will from now work on the renamed column (id_number) and the data sinks may still expect the old one (id). Independently on that, even if you do some custom transformation, you'll still need to adapt it to the evolved schema. But the schema tracking gives you at least a chance to replay the stream. A streaming query without the schema tracking will continuously fail with this error message:
Caused by: org.apache.spark.sql.delta.DeltaStreamingColumnMappingSchemaIncompatibleException: [DELTA_STREAMING_INCOMPATIBLE_SCHEMA_CHANGE_USE_SCHEMA_LOG] Streaming read is not supported on tables with read-incompatible schema changes (e.g. rename or drop or datatype changes).
Please provide a 'schemaTrackingLocation' to enable non-additive schema evolution for Delta stream processing.
See https://docs.delta.io/latest/versioning.html#column-mapping for more details.
Read schema: {"type":"struct","fields":[{"name":"number","type":"integer","nullable":true,"metadata":{"delta.columnMapping.id":1,"delta.columnMapping.physicalName":"number"}},{"name":"letter","type":"string","nullable":true,"metadata":{"delta.columnMapping.id":2,"delta.columnMapping.physicalName":"letter"}}]}.
Incompatible data schema: {"type":"struct","fields":[{"name":"id_number","type":"integer","nullable":true,"metadata":{"delta.columnMapping.id":1,"delta.columnMapping.physicalName":"number"}},{"name":"letter","type":"string","nullable":true,"metadata":{"delta.columnMapping.id":2,"delta.columnMapping.physicalName":"letter"}}]}.
If your table supports column mapping, you can overcome this issue without the schema tracking by turning an streaming.unsafeReadOnIncompatibleColumnMappingSchemaChanges.enabled property on, which by the way is marked as "unsafe" not by mistake:
val DELTA_STREAMING_UNSAFE_READ_ON_INCOMPATIBLE_COLUMN_MAPPING_SCHEMA_CHANGES =
buildConf("streaming.unsafeReadOnIncompatibleColumnMappingSchemaChanges.enabled")
.doc(
"Streaming read on Delta table with column mapping schema operations " +
"(e.g. rename or drop column) is currently blocked due to potential data loss and " +
"schema confusion. However, existing users may use this flag to force unblock " +
"if they'd like to take the risk.")
.internal()
.booleanConf
.createWithDefault(false)
As you can see, streaming Delta tables, despite their structured nature, is not an easy task. Rare are the tables that don't evolve which makes the whole operation more tricky. Thankfully, the community has already provided the schema tracking capability that can make your life easier.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩