
Checkpoints are a well-known fault-tolerance mechanism in stream processing. But what does it have to do with Delta Lake?
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Checkpoints and Delta Lake
Checkpoints in Delta Lake has a similar role to the snapshot files in Apache Spark Structured Streaming, i.e. they provide a faster way to read the metadata information. The difference is the content, of course.
Checkpoints in Delta Lake store X most recent commits to reduce the number of delta files to read while discovering the state of a table. They're performed in 2 different ways presented in the schema below:
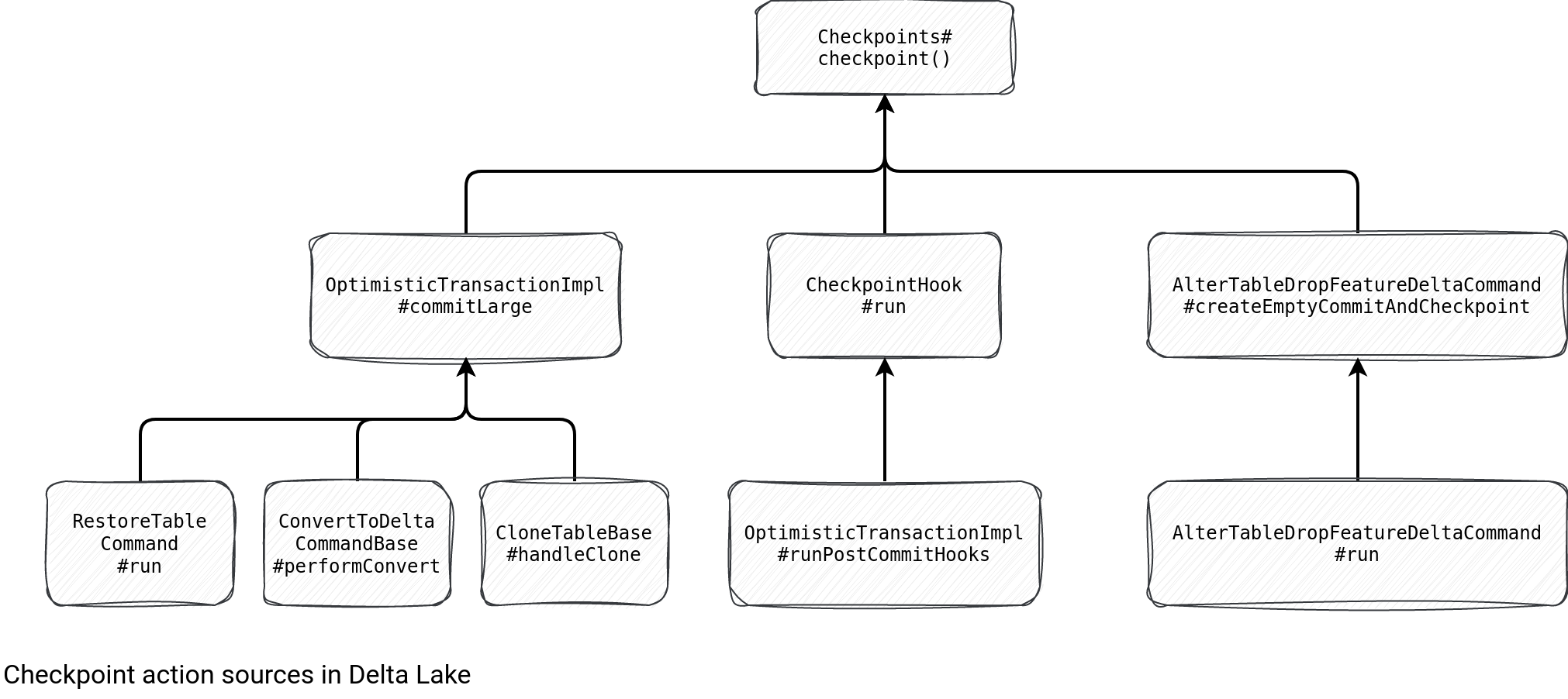
As you can see, there are 3 main triggers for the checkpoints:
- Large table actions, such as restore table, convert existing data into Delta Lake, or clone an existing table. It does make sense. All of them create a new structure and having potentially hundreds of files to deal with would be inefficient for the readers.
- Post-commit callback. Each table can be configured with a checkpointInterval property that defines how often Delta Lake will create a checkpoint for a table. It defaults to 10 meaning that every 10 commits the table commit logs will be checkpointed:
protected def setNeedsCheckpoint(committedVersion: Long, postCommitSnapshot: Snapshot): Unit = { def checkpointInterval = deltaLog.checkpointInterval(postCommitSnapshot.metadata) needsCheckpoint = committedVersion != 0 && committedVersion % checkpointInterval == 0 } - The ALTER TABLE t DROP FEATURE f command.
It's worth noticing that for the post-hook scenario the checkpointing is a best-effort operation whose failure doesn't impact the entire transaction. Unless you decide the opposite and configure the checkpoint.exceptionThrowing.enabled to true. It's not a recommended practice and the configuration itself is described more as the one reserved to the testing purposes. Anyway, that's why the checkpointing process is wrapped by this try-catch block:
protected def withCheckpointExceptionHandling(deltaLog: DeltaLog, opType: String)(thunk: => Unit): Unit = {
try {
thunk
} catch {
case NonFatal(e) =>
recordDeltaEvent(
deltaLog, opType,
data = Map("exception" -> e.getMessage(), "stackTrace" -> e.getStackTrace())
)
logWarning(s"Error when writing checkpoint-related files", e)
val throwError = Utils.isTesting || spark.sessionState.conf.getConf(DeltaSQLConf.DELTA_CHECKPOINT_THROW_EXCEPTION_WHEN_FAILED)
if (throwError) throw e
}
The content
What does the content of a checkpoint look like? Let's take this example:
sparkSession.sql(
s"""
|CREATE TABLE ${tableName} (id int) USING delta
| TBLPROPERTIES ('delta.checkpointInterval' = 5)
|""".stripMargin)
(0 until 5).foreach(_ => {
(0 to 100).toDF("id").writeTo(tableName).append()
})
Once you analyze the commit log, you'll see new files created:

The first of the highlighted files looks like a commit file. The single difference at this level is its .checkpoint.parquet extension. However, inside you'll find the files added and removed in all the previous transactions, alongside the stats, metadata, and partition values. A simple - let's call it raw - commit contains only this information for a single transaction. Below the content for our example:
+----+--------------------+------+--------------------+------------------+--------------+
| txn| add|remove| metaData| protocol|domainMetadata|
+----+--------------------+------+--------------------+------------------+--------------+
|NULL|{part-00001-b20dc...| NULL| NULL| NULL| NULL|
|NULL|{part-00001-9910d...| NULL| NULL| NULL| NULL|
|NULL|{part-00001-6e1b2...| NULL| NULL| NULL| NULL|
|NULL|{part-00000-7bedd...| NULL| NULL| NULL| NULL|
|NULL|{part-00000-ec69f...| NULL| NULL| NULL| NULL|
|NULL|{part-00001-f18f6...| NULL| NULL| NULL| NULL|
|NULL|{part-00001-cf21b...| NULL| NULL| NULL| NULL|
|NULL|{part-00000-ecab5...| NULL| NULL| NULL| NULL|
|NULL| NULL| NULL| NULL|{1, 2, NULL, NULL}| NULL|
|NULL| NULL| NULL|{a766259d-e933-46...| NULL| NULL|
|NULL|{part-00000-8a36e...| NULL| NULL| NULL| NULL|
|NULL|{part-00000-c1960...| NULL| NULL| NULL| NULL|
+----+--------------------+------+--------------------+------------------+--------------+
Additionally there is also a _last_checkpoint file. It stores the metadata about the most recent checkpoint, hence the schema, size, or version. It also knows about the checkpoint type because yes, there are different checkpoint types. Three to be more precise: classical, UUID-based, and multi-part. Since the last one is deprecated, I'll skip it in the blog post. The content of the _last_checkpoint file for our example is (schema removed for the sake of readability):
{
"version":5,
"size":12,
"sizeInBytes":16248,
"numOfAddFiles":10,
"checkpointSchema":{
"type":"struct",
"fields":[
// ...
]
},
"checksum":"4274df52276b0ef4c063578707bac1ad"
}
Besides different types, there are also 2 different protocols, V1 and V2. The former consists of only a single checkpoint file with all the actions made on the table. The V2 is different because it stores all add and remove files actions in sidecar files. To enable it, you've to set the checkpointPolicy attribute at the table level:
sparkSession.sql(
s"""
|CREATE TABLE table_checkpoint_v2 (id int) USING delta
| TBLPROPERTIES ('delta.checkpointPolicy' = 'v2')
|""".stripMargin)
As you can see, the checkpoint's outcome is rather basic. However, the process leading to its creation and reading is more complex. We'll focus on it in the remaining parts of the blog post with the goal to understand it a bit better.
Creation
Let's first understand the checkpointing process itself. All starts with detecting the checkpointPolicy defined at the table level. If it's the V2 protocol, the checkpoint process selects the output format which is either JSON or Apache Parquet. Later on, the process initializes a few important instances, including the accumulators to get all checkpointed rows and all checkpointed commit logs:
trait Checkpoints extends DeltaLogging {
self: DeltaLog =>
// ...
private[delta] def writeCheckpoint(
spark: SparkSession,
deltaLog: DeltaLog,
snapshot: Snapshot): LastCheckpointInfo = recordFrameProfile(
// ...
val v2CheckpointEnabled = v2CheckpointFormatOpt.nonEmpty
val checkpointRowCount = spark.sparkContext.longAccumulator("checkpointRowCount")
val numOfFiles = spark.sparkContext.longAccumulator("numOfFiles")
Later, the logic reads the checkpoint.partSize property to know whether the checkpointing job should be parallelized or not. The parallelization formula divides the number of added and removed files in all checkpointed commits by this partSize property:
val numParts = checkpointPartSize.map { partSize =>
math.ceil((snapshot.numOfFiles + snapshot.numOfRemoves).toDouble / partSize).toLong
}.getOrElse(1L).toInt
After that, the code creates a new DataFrame that contains a decorated set of SingleAction rows with all the visible and valid changes made to the commit log so far:
val repartitioned = snapshot.stateDS
.repartition(numParts, coalesce(col("add.path"), col("remove.path")))
.map { action =>
if (action.add != null) {
numOfFiles.add(1)
}
action
}
case class SingleAction(
txn: SetTransaction = null, add: AddFile = null, remove: RemoveFile = null,
metaData: Metadata = null, protocol: Protocol = null, cdc: AddCDCFile = null,
checkpointMetadata: CheckpointMetadata = null, sidecar: SidecarFile = null,
domainMetadata: DomainMetadata = null,commitInfo: CommitInfo = null) {
The preparation step removes some of the irrelevant columns. Later so prepared DataFrame is transformed and enriched with extra attributes for the add files actions. They include partition values, stats, size, modification time, or yet tags. The preparation step also repartitions the data based on one of the file names from the action columns (add or delete). 💡 The repartitioning using the file names is intentional as it guarantees consistency across retries. If for whatever reason there are 2 concurrent checkpoint operations from the same client, where one is a zombie task, this deterministic repartitioning is necessary to avoid table corruption.
This enriched DataFrame is later written to the checkpoint file(s) from an internal def executeFinalCheckpointFiles() method:
def executeFinalCheckpointFiles(): Array[SerializableFileStatus] = qe .executedPlan .execute() .mapPartitions(...)
The files writing logic is defined in the mapPartitions and it has 2 main blocks. The first block defines the checkpoint file name. 💡 It's actually this part which defines whether the checkpoint should follow the V1 or the V2 protocol.. How? Simply by returning a different checkpoint file name! For the V2 protocol it'll return a path prefixed by the _sidecards while for the V1 it will return a name within the commit log. Below is the called method:
def getCheckpointWritePath(
conf: Configuration, logPath: Path, version: Long, numParts: Int,
part: Int, useRename: Boolean, v2CheckpointEnabled: Boolean): (Path, Path) = {
// ...
val destinationName: Path = if (v2CheckpointEnabled) {
newV2CheckpointSidecarFile(logPath, version, numParts, part + 1)
} else {
if (numParts > 1) {
assert(part < numParts, s"Asked to create part: $part of max $numParts in checkpoint.")
checkpointFileWithParts(logPath, version, numParts)(part)
} else {
checkpointFileSingular(logPath, version)
}
}
getCheckpointWritePath(destinationName) -> destinationName
}
Once the file names, hence the protocol, are resolved, the writing function generates the files. 💡 It leverages an explicitly initialized ParquetOutputWriter so that the checkpoint process can control the file names. Otherwise, it would be challenging to get the file names and put to the checkpoint manifest file:
val writeAction = () => {
try {
val writer = factory.newInstance(
writtenPath.toString, schema,
new TaskAttemptContextImpl(
new JobConf(serConf.value),
new TaskAttemptID("", 0, TaskType.REDUCE, 0, 0))
)
iter.foreach { row =>
checkpointRowCount.add(1)
writer.write(row)
}
At this point, the checkpoint files storing the compacted information from the previous commit logs are created. However, the operation doesn't stop here. If the V2 protocol is used, the process will write yet another file. This one will reference all sidecars.
Only after this optional operation, the checkpoint comes to its end. It creates an instance of the LastCheckpointInfo that stores the metadata information from the checkpoint operation and writes it to the _last_checkpoint file we saw in the previous section.
Reading
Now, when we're aware of the writing process, let's stay focused only on the V2 protocol and see when and how the checkpoints are used. The class responsible for recovering table state from a checkpoint is one of the CheckpointProviders. For the V2 it'll be V2CheckpointProvider.
The checkpoint recovery process detects the V2 protocol by reading the v2Checkpoint attribute from the _last_checkpoint file:
{"version":4,"size":12,"sizeInBytes":9981,"numOfAddFiles":8,"v2Checkpoint":{"path":"00000000000000000004.checkpoint.871a4373-bcf5-48fe-8918-9f9d2616be6d.json" ...
"sidecarFiles":[{"path":"00000000000000000004.checkpoint.0000000001.0000000001.1d1345b0-7b33-4237-be17-375847c718c6.parquet","sizeInBytes":9287 ...
At the same moment, it retrieves the sidecarFiles highlighted in the snippet above. The Snapshot instance directly uses them to materialize the commit log exposed to all read operations:
class Snapshot(
val path: Path, override val version: Long, val logSegment: LogSegment,
override val deltaLog: DeltaLog, val timestamp: Long, val checksumOpt: Option[VersionChecksum]
)
protected def loadActions: DataFrame = {
fileIndices.map(deltaLog.loadIndex(_))
.reduceOption(_.union(_)).getOrElse(emptyDF)
.withColumn(ADD_STATS_TO_USE_COL_NAME, col("add.stats"))
}
The fileIndices from highlighted part represent the sidecar files retrieved before and the loadIndex(...) method transforms each of them to a DataFrame with the file actions:
class DeltaLog
// ...
def loadIndex(index: DeltaLogFileIndex, schema: StructType = Action.logSchema): DataFrame = {
Dataset.ofRows(spark, indexToRelation(index, schema))
}
Below is the output example for one of the tests I made:
+----+--------------------+------+--------+--------+----+------------------+-------+--------------+----------+-------+
| txn| add|remove|metaData|protocol| cdc|checkpointMetadata|sidecar|domainMetadata|commitInfo|version|
+----+--------------------+------+--------+--------+----+------------------+-------+--------------+----------+-------+
|NULL|{part-00000-2ed82...| NULL| NULL| NULL|NULL| NULL| NULL| NULL| NULL| -1|
|NULL|{part-00001-57005...| NULL| NULL| NULL|NULL| NULL| NULL| NULL| NULL| -1|
|NULL|{part-00001-6ac31...| NULL| NULL| NULL|NULL| NULL| NULL| NULL| NULL| -1|
|NULL|{part-00000-1beb1...| NULL| NULL| NULL|NULL| NULL| NULL| NULL| NULL| -1|
|NULL|{part-00001-85596...| NULL| NULL| NULL|NULL| NULL| NULL| NULL| NULL| -1|
|NULL|{part-00000-abdf1...| NULL| NULL| NULL|NULL| NULL| NULL| NULL| NULL| -1|
|NULL|{part-00000-274e5...| NULL| NULL| NULL|NULL| NULL| NULL| NULL| NULL| -1|
|NULL|{part-00001-64910...| NULL| NULL| NULL|NULL| NULL| NULL| NULL| NULL| -1|
+----+--------------------+------+--------+--------+----+------------------+-------+--------------+----------+-------+
All these files are later added to the InMemoryLogReplay referenced at the snapshot state reconstruction:
protected def stateReconstruction: Dataset[SingleAction] = {
// ...
val ADD_PATH_CANONICAL_COL_NAME = "add_path_canonical"
val REMOVE_PATH_CANONICAL_COL_NAME = "remove_path_canonical"
loadActions
// ...
.as[SingleAction]
.mapPartitions { iter =>
val state: LogReplay = new InMemoryLogReplay(
localMinFileRetentionTimestamp,
localMinSetTransactionRetentionTimestamp)
state.append(0, iter.map(_.unwrap))
state.checkpoint.map(_.wrap)
}
Retention and compact checkpoint
Even though the checkpoint files look like special components of the commit log, they're considered as regular commit logs for the metadata cleanup process. If the table is configured with the cleanup enabled (enableExpiredLogCleanup), the checkpoint process removes obsolete files in the end of the generation process:
trait Checkpoints extends DeltaLogging {
// ...
def checkpointAndCleanUpDeltaLog(snapshotToCheckpoint: Snapshot): Unit = {
val lastCheckpointInfo = writeCheckpointFiles(snapshotToCheckpoint)
writeLastCheckpointFile(snapshotToCheckpoint.deltaLog, lastCheckpointInfo
LastCheckpointInfo.checksumEnabled(spark))
doLogCleanup(snapshotToCheckpoint)
}
What happens in this cleanup process? First, it detects a so-called file cut-off time which is based on the logRetentionDuration config; the time is truncated to the day at midnight:
val retentionMillis = deltaRetentionMillisOpt.getOrElse(deltaRetentionMillis(snapshot.metadata)) val fileCutOffTime = truncateDate(clock.getTimeMillis() - retentionMillis, cutoffTruncationGranularity).getTime
As a result, all files older than this time that have a checkpoint file created after them, will be removed from the commit log. The second part of the condition is really important. Without it, the cleaning process would lead to the corrupted table with missing commits [the log wouldn't be continuous].
After resolving the commit logs to remove, and only if there are any, the cleaning process creates a compatibility checkpoint. The compatibility file follows the V1 protocol naming convention and is created for compatibility reasons. That way older Delta Lake readers who can't understand the V2 protocol, can interpret the checkpoint parameters, including the protocol, and fail gracefully.
In the next step, the process deletes all the resolved logs one by one. In the end, if there were any checkpoint file deleted, it removes any orphan checkpoint files:
private[delta] def cleanUpExpiredLogs(
// ...
expiredDeltaLogs.map(_.getPath).foreach { path =>
// recursive = false
if (fs.delete(path, false)) {
numDeleted += 1
if (FileNames.isCheckpointFile(path)) {
wasCheckpointDeleted = true
}
}
}
if (wasCheckpointDeleted) {
// Trigger sidecar deletion only when some checkpoints have been deleted as part of this
// round of Metadata cleanup.
val sidecarDeletionMetrics = new SidecarDeletionMetrics
identifyAndDeleteUnreferencedSidecarFiles(
snapshotToCleanup,
fileCutOffTime.getTime,
sidecarDeletionMetrics)
logInfo(s"Sidecar deletion metrics: $sidecarDeletionMetrics")
}
And right now you may be asking yourself, Hey, but if the cleanup removes old commit log files, why doesn't it remove the corresponding data files? After all, they might not be referenced anymore! Well, in fact, they're still referenced. They remain valid as long as you don't delete the data. Eventually, they might become unavailable for the time-travel past this retention period but the table will still be consistent and Delta Lake will not delete any data without your explicit action.
From now on, because I haven't covered this part yet, you may be challenging myself and saying: Hey, but the checkpoint compacts only the new raw commit logs from the previous checkpoint, so the old checkpoints, since they're removed, shouldn't reference any active data. This is not true as well. Indeed, checkpoints compact the last raw commit logs but they also include the information from other prior checkpoints. How is it possible? Remember the stateReconstruction from the previous section? It stores the list of all table action files (add or delete) and it's the input for the checkpoint process:
trait Checkpoints extends DeltaLogging {
// ...
private[delta] def writeCheckpoint(
// ...
val base = {
val repartitioned = snapshot.stateDS
.repartition(numParts, coalesce(col("add.path"), col("remove.path")))
.map { action =>
if (action.add != null) {
numOfFiles.add(1)
}
action
}
And since this reconstructed state is used as the files provider for the checkpoint, there is no risk some data will be lost.
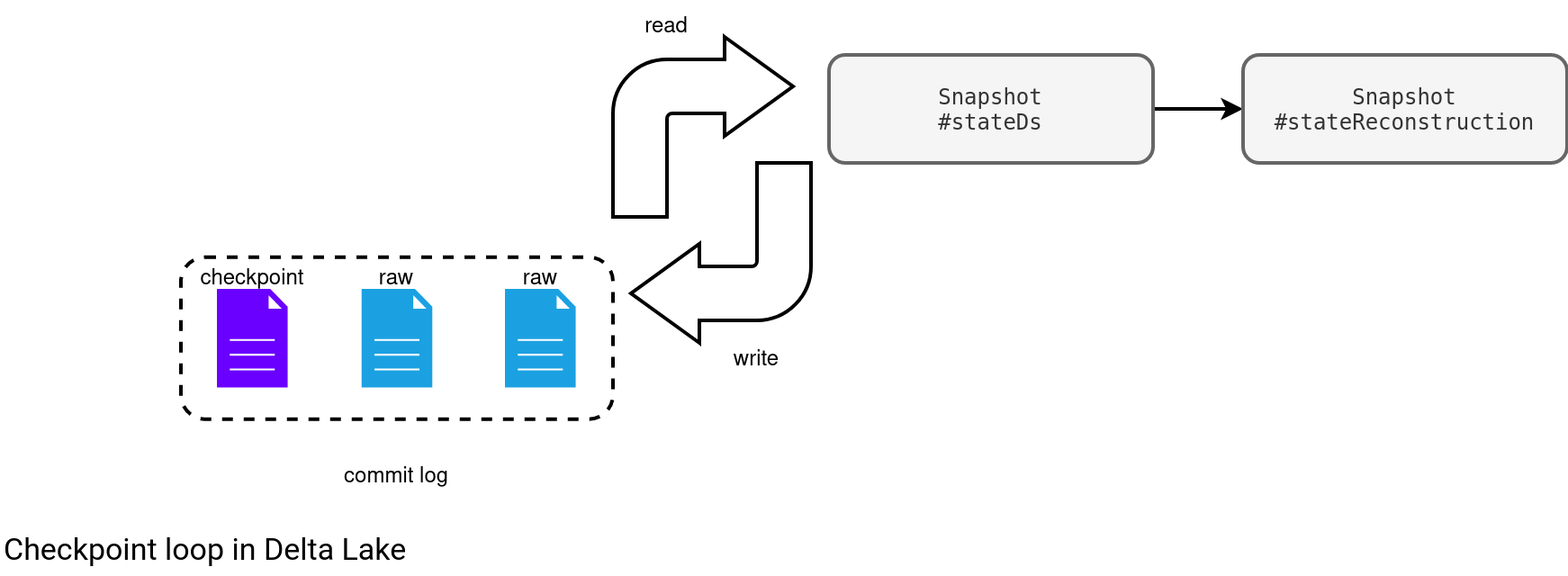
If you had used Apache Spark Structured Streaming stateful processing before Delta Lake, you certainly can find some similarities between the delta files in the streaming framework and the Delta Lake itself. Both register iterative changes but for the optimization reasons, each configured interval, there is a new checkpoint file created (snapshot in Spark). I don't know what will be my next Delta Lake topic but I'm quite curious to either explore the Snapshot [the class, quoted many times today] or the time-travel. No promises though, maybe I'll discover something else ;)
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Table file formats - checkpoints: Delta Lake here:
Related blog posts:
- Commit log decorator with userMetadata property
- Truncating a Delta Lake table, aka metadata-only operations
- Idempotent writer