
One of the great features of modern table file formats is the ability to handle write conflicts. It wouldn't be possible without commits that are the topic of this new blog post.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Why?
First of all, why should we even need to handle conflicts in lake-like systems? After all, having a single writer and multiple readers per location, plus immutable dataset, is quite a nice and easy pattern to implement. Indeed,it is. But the problems may start later, when you start to cover more and more data use cases.
Let's take an example. We have a users dataset and 2 different writers. The first writer covers the right-to-be-forgotten and does DELETE operations on particular lines. The second one implements the offline data enrichment scenario, hence does the UPDATE operations. Both operations are explicitly implemented as read the dataset ⇒ change the dataset ⇒ rewrite it fully.
I bet you already see the problem. If not, maybe the schema will help...
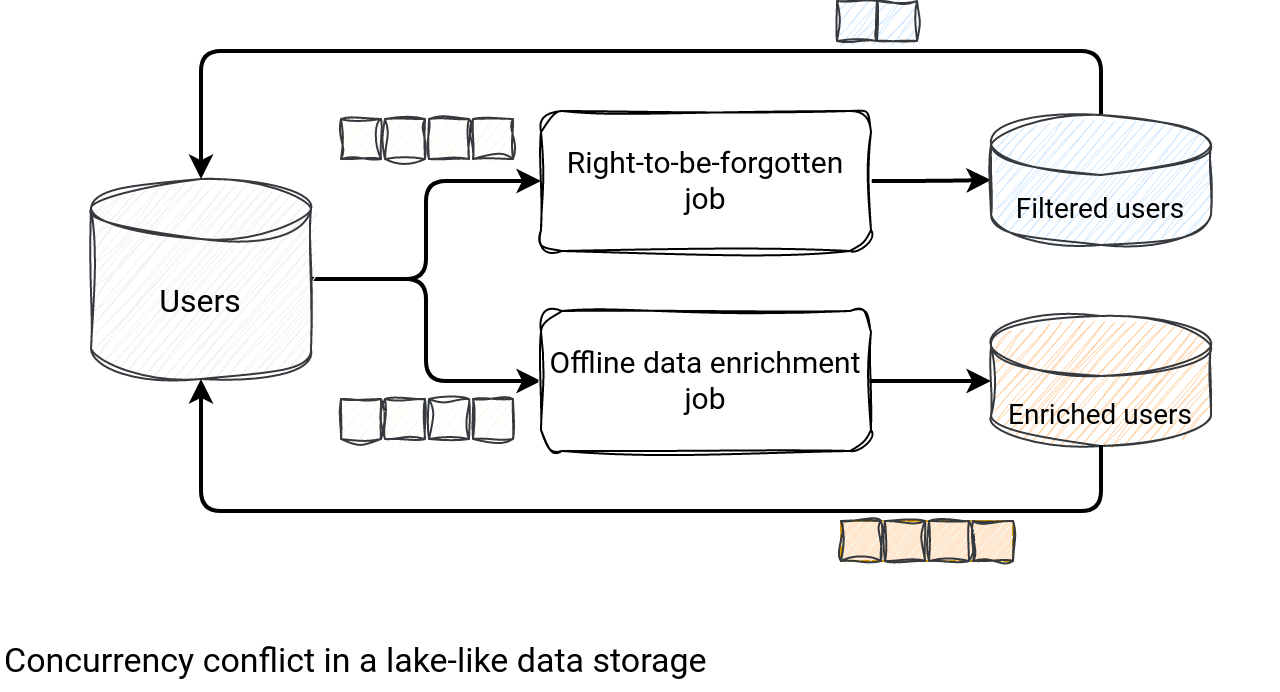
...yes, both jobs are fully asynchronous but they override the same dataset [and the same files] and one will replace the other. If the Offline data enrichment is always the last successful writer, it will invalidate the filtering work made by the Right-to-be-forgotten one. How is it different with modern table file formats? In that configuration where jobs operate on the same set of files, only one of them can succeed. If it is the GDPR one, the data enrichment will be made on the filtered users. If it's the opposite, the GDPR job will need to rerun on the same set of files but the outcome will still be the same - a dataset with fewer rows.
Commit
How does Delta Lake manage conflicts? It relies on transactions. Whenever you run a writing operation, Delta Lake starts a transaction from DeltaLake#withNewTransaction, as here for the UPDATE operation:
final override def run(sparkSession: SparkSession): Seq[Row] = {
recordDeltaOperation(tahoeFileIndex.deltaLog, "delta.dml.update") {
val deltaLog = tahoeFileIndex.deltaLog
deltaLog.withNewTransaction { txn =>
DeltaLog.assertRemovable(txn.snapshot)
// ...
performUpdate(sparkSession, deltaLog, txn)
// ...
}
If you don't see the commit, that's normal because it's made inside the performUpdate. And by saying "commit", I'm oversimplifying because actually, there are 2 "commit" methods, the commit and commitIfNeeded. The difference is subtle because it consists of a different value of the canSkipEmptyCommits flag, set to false for former and to true for latter methods. What is the role of this flag in the context of commits?
Simply speaking, a commit can be empty, i.e. without any action to record to the commit log. In that case, and only if the skipRecordingEmptyCommits remains enabled, and the table uses snapshot or serializable isolation levels, Delta Log won't contain any update for this empty operation. This mode applies to all in-place operations, hence DELETE, UPDATE and MERGE. It was added to avoid incorrect behavior for write serializable mode for empty commits, and to standardize the semantic for in-place operations in the serializable mode. I'll write about these modes later and before them, let's focus on the conflicts management algorithm located in the commit as per the diagram below:

The class responsible for ensuring the correctness of a transaction is the ConflictChecker. It performs various validations of the transaction about to be committed against the most recently committed transaction. If any of the checks fails, a corresponding exception gets thrown. In the diagram you can also notice a doCommitRetryIteratively method. Under-the-hood it tries to commit a transaction at most maxCommitAttempts times.
The default value for the config is 10 000 000. Does it mean any conflicted transaction will be retried 10 000 000 times? Well, no. The retry happens only for the FileAlreadyExistsException. The others, including the conflict ones, do stop the commit with an error.
Commit and log
Now, when you already know how Delta Lake ensures the lack of conflicts, it's time to see what it means, to commit a transaction. In the end of each operation, the engine confirms their outcome by generating a JSON file inside the _delta_log location. The name is an incremental number padded on 20 integers and inside you'll find all actions made in the transactions, including:
- Added and removed files
- The table's supported protocol settings.
- Metadata including the files format, schema, partition columns.
- The commit info with the attributes such as the transaction id, the SQL operation, user metadata, operation metrics, or the engine info.
You'll find an example in your _delta_log but if you don't want to search, below is one of my commits:
{"commitInfo":{"timestamp":1690682462564,"operation":"MERGE","operationParameters":{"predicate":"[\"(id#598 = id#2218)\"]","matchedPredicates":"[{\"actionType\":\"update\"}]","notMatchedPredicates":"[{\"actionType\":\"insert\"}]","notMatchedBySourcePredicates":"[]"},"readVersion":2,"isolationLevel":"Serializable","isBlindAppend":false,"operationMetrics":{"numTargetRowsCopied":"3","numTargetRowsDeleted":"0","numTargetFilesAdded":"1","numTargetBytesAdded":"934","numTargetBytesRemoved":"928","numTargetRowsMatchedUpdated":"1","executionTimeMs":"2384","numTargetRowsInserted":"1","numTargetRowsMatchedDeleted":"0","scanTimeMs":"1625","numTargetRowsUpdated":"1","numOutputRows":"5","numTargetRowsNotMatchedBySourceUpdated":"0","numTargetChangeFilesAdded":"0","numSourceRows":"2","numTargetFilesRemoved":"1","numTargetRowsNotMatchedBySourceDeleted":"0","rewriteTimeMs":"710"},"engineInfo":"Apache-Spark/3.4.0 Delta-Lake/2.4.0","txnId":"5b068d91-2a11-4fa2-a73c-c7033ba20335"}}
{"remove":{"path":"part-00000-72d68ff7-80c0-4d01-bc29-c7647952d2e5-c000.snappy.parquet","deletionTimestamp":1690682462548,"dataChange":true,"extendedFileMetadata":true,"partitionValues":{},"size":928}}
{"add":{"path":"part-00000-b8f8d303-30e3-4b84-906b-8775ebfcc7c5-c000.snappy.parquet","partitionValues":{},"size":934,"modificationTime":1690682462534,"dataChange":true,"stats":"{\"numRecords\":5,\"minValues\":{\"id\":1,\"login\":\"user1\"},\"maxValues\":{\"id\":6,\"login\":\"user6\"},\"nullCount\":{\"id\":0,\"login\":0,\"isActive\":0}}"}}
Knowing that Delta Lake creates these padded on 20 integers commit files, we may try to decipher the doCommitRetryIteratively method:
val maxRetryAttempts = spark.conf.get(DeltaSQLConf.DELTA_MAX_RETRY_COMMIT_ATTEMPTS)
recordDeltaOperation(deltaLog, "delta.commit.allAttempts") {
for (attemptNumber <- 0 to maxRetryAttempts) {
try {
val postCommitSnapshot = if (attemptNumber == 0) {
doCommit(commitVersion, updatedCurrentTransactionInfo, attemptNumber, isolationLevel)
} else recordDeltaOperation(deltaLog, "delta.commit.retry") {
val (newCommitVersion, newCurrentTransactionInfo) = checkForConflicts(
commitVersion, updatedCurrentTransactionInfo, attemptNumber, isolationLevel)
commitVersion = newCommitVersion
updatedCurrentTransactionInfo = newCurrentTransactionInfo
doCommit(commitVersion, updatedCurrentTransactionInfo, attemptNumber, isolationLevel)
}
committed = true
return (commitVersion, postCommitSnapshot, updatedCurrentTransactionInfo)
} catch {
case _: FileAlreadyExistsException => // Do nothing, retry
}
}
}
For the first attempt there are no conflicts checks. It isn't normal since we may also have conflicts there, don't we? Indeed! But in that case, while the commit protocol will try to write this JSON commit file, it'll fail with the FileAlreadyExistsException. It'll lead to the retry and only then - knowing that there is already another transaction committed - the engine will perform the conflict checks. If they don't impact the set of files modified within the transaction, a new commit number is returned and used to generate the commit file. On the other hand, if any conflict is detected, the operation fails since only the FileAlreadyExistsException errors are managed.
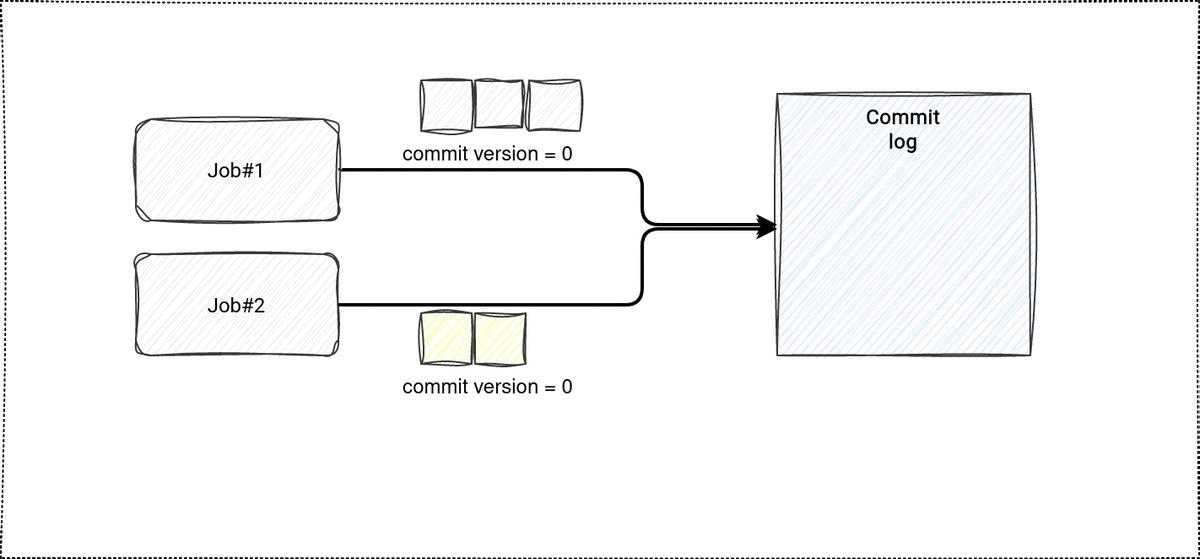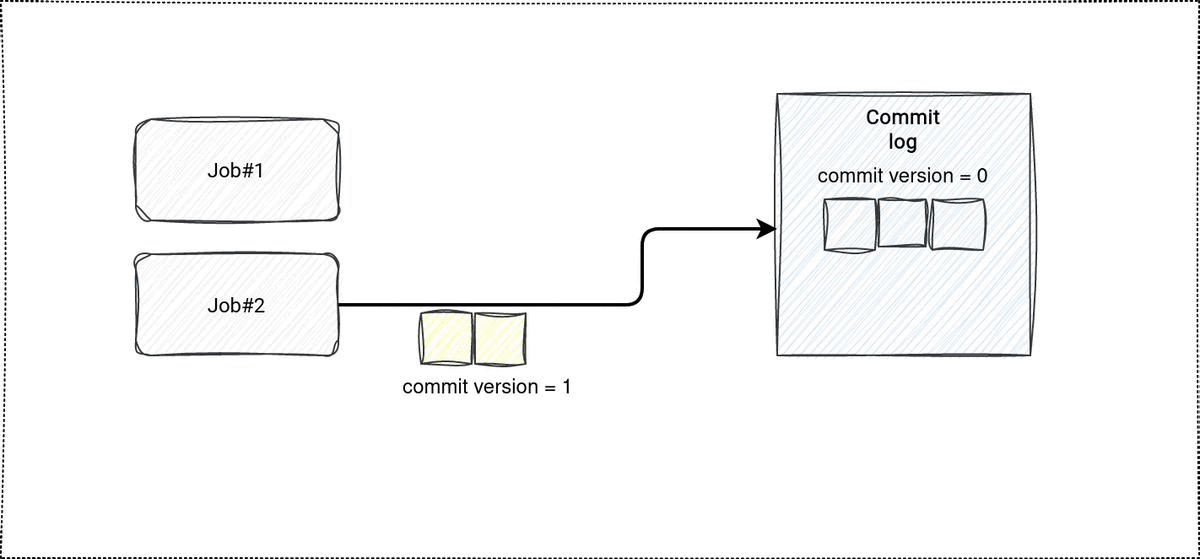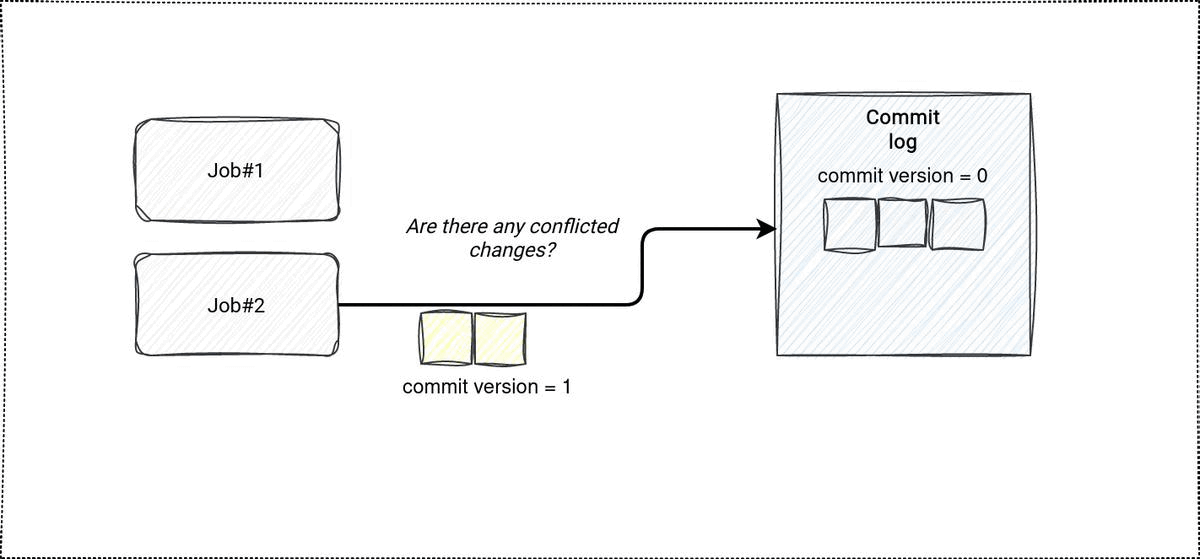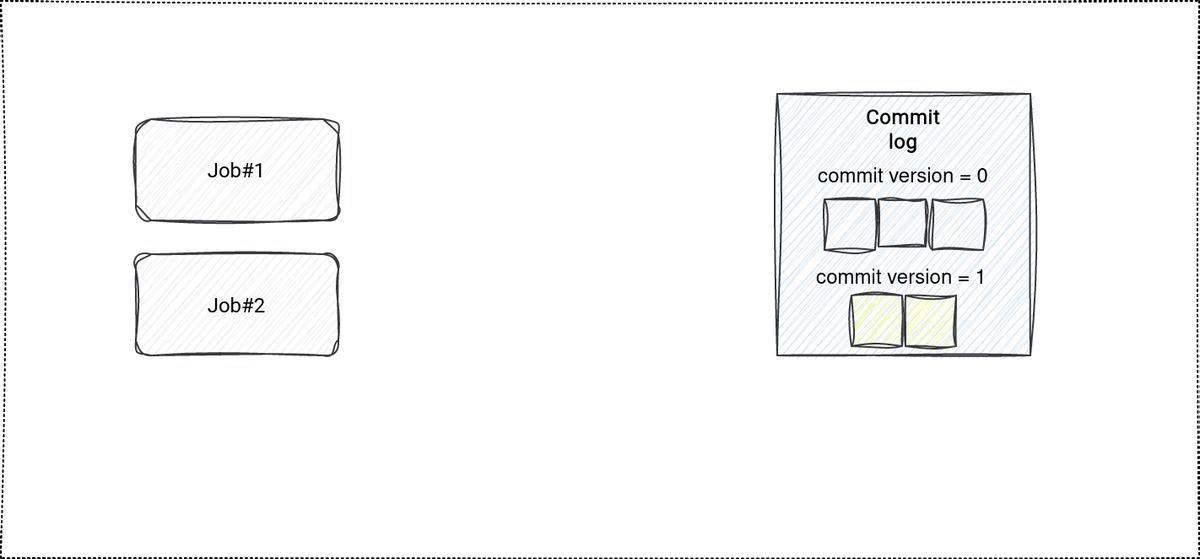
Demo
It has been a while since my last demo recorded on my YouTube channel and I somehow miss it! That's why this time I'll focus on the commit log and its internals visually. The code is still on my Github, though.
In the demo I wanted to see the impact of conflicts in case of concurrent updates. The first test case is obvious, it just modifies a table in 2 threads. No surprise, a failure due to the concurrency is inevitable. The second case is a little bit more nuanced. Before updating the rows, I'm explicitly identifying 2 items stored in different files. The assumption is that, since they're not overwritten, the concurrency shouldn't block any of the isolated updates. It turns out, the assumption is wrong. Even though both updates read different files, there is no such guarantee the rows changed by the first successful transaction shouldn't be changed by the second, not yet committed, update. The error message is self-explanatory in that case: ConcurrentAppendException: Files were added to the root of the table by a concurrent update. Please try the operation again..
And this "to the root" introduces another test family. If the changes do not concern the root and instead are made at each partition separately, will they work? Yes, they are going to work but you must ensure to explicitly set the partition column as a part of your predicate. Otherwise Delta Lake considers it as a root scan-based operation and detects conflict due to appending files from the root standpoint.
Finally, in the last demo you can see the automatic conflict resolution, the one based on the FileAlreadyExistsException. More in the video below:
I must admit, the blog post is so long and I haven't even covered all I wanted! I missed the isolation levels among others and I'm trying to catch up on these topics next weeks.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Commit log decorator with userMetadata property
- Truncating a Delta Lake table, aka metadata-only operations
- Idempotent writer
One of the great features of table file formats is the ability to handle write conflicts. It wouldn't be possible without commits that are the topic of my #DeltaLake blog post. https://t.co/WIi6W6RpW8
— Bartosz Konieczny (@waitingforcode) August 30, 2023