
Data lakes have made the data-on-read schema popular. Things seem to change with the new open table file formats, like Delta Lake or Apache Iceberg. Why? Let's try to understand that by analyzing their schema evolution parts.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Schema enforcement vs. schema evolution
Before delving into code, there is one important point to explain. The schema evolution doesn't mean the schema enforcement but both are present in Delta Lake. Moreover, schema evolution is a side effect of the schema enforcement.
Why so? When you try to write a DataFrame that doesn't comply with the table's schema, you'll get the exception like:
Exception in thread "main" org.apache.spark.sql.AnalysisException: A schema mismatch detected when writing to the Delta table (Table ID: 677731f2-cc36-4838-9c1f-526d91b6930e).
To enable schema migration using DataFrameWriter or DataStreamWriter, please set:
'.option("mergeSchema", "true")'.
# ...
Pretty clear now, isn't it? The mergeSchema option suggested by the stack trace message is the enabler of the schema evolution. Without that, you won't be able to write any data that has new columns or the same columns with different types.
Schema metadata
The first step in our schema journey is to understand where these schemas are stored. They're part of the metadata associated to each transaction:
# cat cat /tmp/table-file-formats/007_schema_evolution/delta_lake/_delta_log/00000000000000000000.json
{"protocol":{"minReaderVersion":1,"minWriterVersion":2}}
{"metaData":{"id":"f819f05a-d6b6-4f19-8501-6b2da695aa75","format":{"provider":"parquet","options":{}},"schemaString":"{\"type\":\"struct\",\"fields\":[{\"name\":\"id\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{}},{\"name\":\"multiplication_result\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{}}]}","partitionColumns":[],"configuration":{},"createdTime":1680573431142}}
# ...
Whenever you change the table schema, Delta Lake simply writes it as a new schemaString:
# cat cat /tmp/table-file-formats/007_schema_evolution/delta_lake/_delta_log/00000000000000000001.json
{"metaData":{"id":"f819f05a-d6b6-4f19-8501-6b2da695aa75","format":{"provider":"parquet","options":{}},"schemaString":"{\"type\":\"struct\",\"fields\":[{\"name\":\"id\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{}},{\"name\":\"multiplication_result\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{}},{\"name\":\"generation_time\",\"type\":\"timestamp\",\"nullable\":true,\"metadata\":{}}]}","partitionColumns":[],"configuration":{},"createdTime":1680573431142}}
# ...
When you read a Delta Lake table, you inherently reference the schema associated with the read transaction and pass it to the internal class representing the table (HadoopFsRelation):
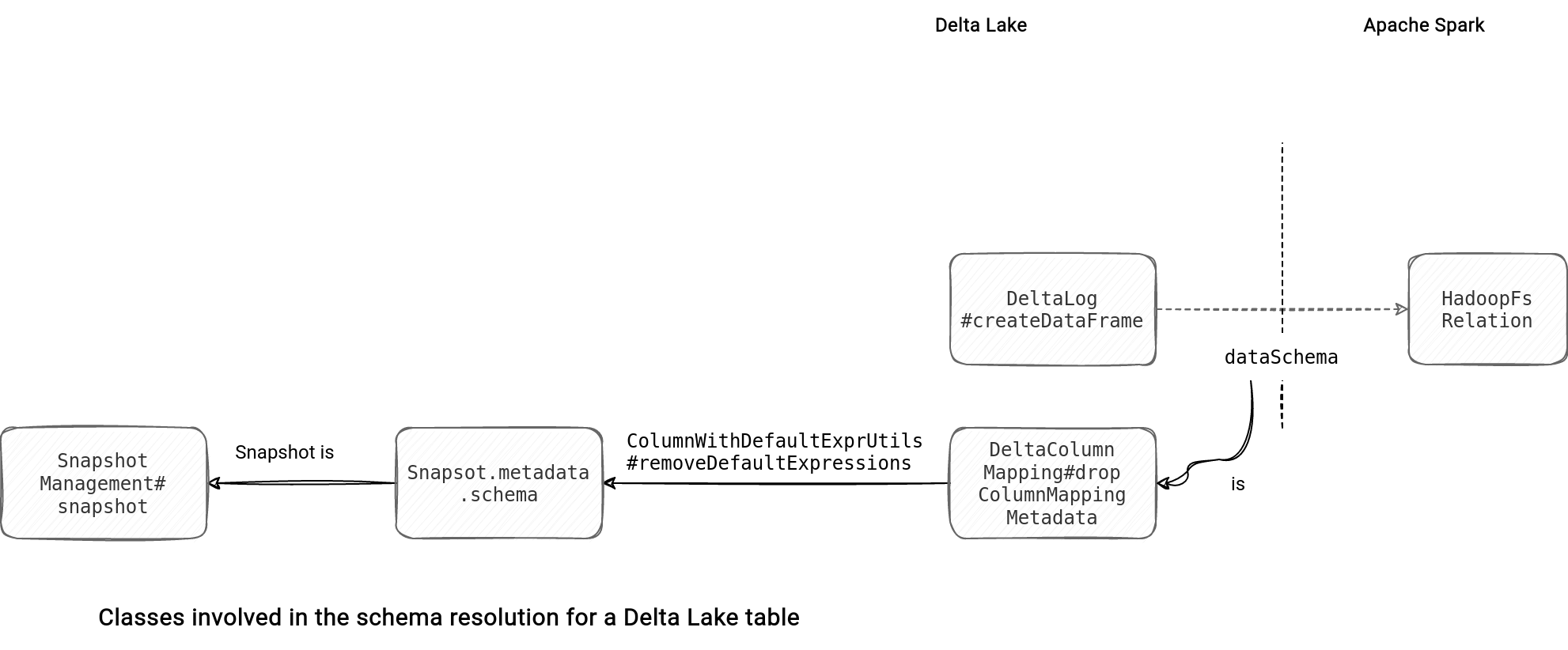
Column mapping
You've certainly noticed an interesting class in the picture, the DeltaColumnMapping. It's related to the column mapping feature that gives more flexibility in the schema manipulation. The mapping represents schema columns with unique id and name attributes and is required for more advanced schema evolution scenarios, such as column renaming or dropping.
To understand that difference, let's see the schema from the metadata file written for a name-based column mapping strategy after renaming a column from multiplication_result to result:
# {"metaData":{"id":"2cd11f34-d0cd-4d2e-a620-3d327b80f90c","format":{"provider":"parquet","options":{}},"schemaString":"{\"type\":\"struct\",\"fields\":[{\"name\":\"id\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{\"delta.columnMapping.id\":1,\"delta.columnMapping.physicalName\":\"id\"}},{\"name\":\"result\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{\"delta.columnMapping.id\":2,\"delta.columnMapping.physicalName\":\"multiplication_result\"}}]}","partitionColumns":[],"configuration":{"delta.columnMapping.mode":"name","delta.columnMapping.maxColumnId":"2"},"createdTime":1680591264401}}
Despite renaming the column, the multiplication_result is still there. If you check the Parquet files associated with this operation, you'll see that they still have the old column name:
val inputData = (0 to 2).map(nr => (nr, nr * 2)).toDF("id", "multiplication_result")
// ...
val inputDataWithDivisionResult = inputData.withColumn("result", $"id" * 3).drop("multiplication_result")
inputDataWithDivisionResult.write.mode(SaveMode.Append).format("delta").save(outputDir)
sparkSession.read.format("parquet").load(outputDir).printSchema
// Prints:
// root
// |-- id: integer (nullable = true)
// |-- multiplication_result: integer (nullable = true)
sparkSession.table("default.numbers").printSchema
// root
// |-- id: integer (nullable = true)
// |-- result: integer (nullable = true)
Without the column mapping it is not possible to rename a column. Otherwise, this operation would require physically rewriting the Parquet files with the new name and albeit possible, it would be a very costly operation. The logical schema representation at the column mapping level is more optimal because as you saw, it only operates at the metadata level.
There are 3 column mapping strategies possible:
- name - uses the physical names to resolve the columns in the schema.
- id - uses the column id as the identifier. Parquet files have the corresponding field Ids for each column in their file schema. This mode is used for the tables converted from Apache Iceberg:
class IcebergTable( spark: SparkSession, icebergTable: Table, existingSchema: Option[StructType]) extends ConvertTargetTable { // ... override val requiredColumnMappingMode: DeltaColumnMappingMode = IdMappingBTW, I'm quite confused about this Iceberg-to-Delta feature. It seems to be under discussion: [Feature Request] Enable converting from Iceberg to Delta #1462. I'll be happy to hear if you have any information on that. - none - it's not possible to change the column names
Schema evolution
If the schema evolution is enabled, Delta Lake manages it inside the WriteIntoDelta#write method. The first schema-related operation is the definition of 2 flags:
override protected val canMergeSchema: Boolean = options.canMergeSchema private def isOverwriteOperation: Boolean = mode == SaveMode.Overwrite override protected val canOverwriteSchema: Boolean = options.canOverwriteSchema && isOverwriteOperation && options.replaceWhere.isEmpty
Both are used in the schema evolution part to identify the allowed changes. If the schema can be overwritten, there is nothing complex happening. Delta Lake simply writes a whole new data to the table. Otherwise, it delegates the schema merge to the SchemaMergingUtils.mergeSchemas.
The mergeSchemas function analyzes column types from the current (aka table) and new (aka data) schemas by using the pattern matching. Depending on the change, it does different things. For example, if the implicit conversion between types is allowed, it converts the current type to the new one. It can also change the a NullType to something else or detect broken precision changes for the decimal fields:
(current, update) match {
/// ...
case (current, update)
if allowImplicitConversions && typeForImplicitCast(update, current).isDefined =>
typeForImplicitCast(update, current).get
case (DecimalType.Fixed(leftPrecision, leftScale),
DecimalType.Fixed(rightPrecision, rightScale)) =>
if ((leftPrecision == rightPrecision) && (leftScale == rightScale)) {
current
} else if ((leftPrecision != rightPrecision) && (leftScale != rightScale)) {
throw new DeltaAnalysisException(
errorClass = "DELTA_MERGE_INCOMPATIBLE_DECIMAL_TYPE",
messageParameters = Array(
s"precision $leftPrecision and $rightPrecision & scale $leftScale and $rightScale"))
} else if (leftPrecision != rightPrecision) {
// ...
case (NullType, _) =>
update
case (_, NullType) =>
current
// ...
If the merge validation fails, you'll get an AnalysisException like this one:
Exception in thread "main" org.apache.spark.sql.AnalysisException: Failed to merge fields 'id_as_int' and 'id_as_int'. Failed to merge incompatible data types IntegerType and LongType
at org.apache.spark.sql.delta.schema.SchemaMergingUtils$.$anonfun$mergeSchemas$1(SchemaMergingUtils.scala:201)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:286)
at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36)
Schema on read
Despite the schema-on-write feature, Delta Lake also has an option impacting the schema-on-read part. The spark.databricks.delta.checkLatestSchemaOnRead configuration protects the readers against any incompatible schema changes. Unlike the mergeSchema and overwriteSchema presented so far, it's a SparkSession property. To understand it, let's try to run the following snippet with this flag enabled and disabled:
val inputData = (0 to 2).map(nr => (nr, nr * 2)).toDF("id", "multiplication_result")
inputData.write.mode(SaveMode.Overwrite).format("delta").save(outputDir)
val reader = sparkSession.read.format("delta")
.load(outputDir)
val inputDataWithDivisionResult = (0 to 2).map(nr => (nr, nr.toDouble * 2.toDouble)).toDF("id", "multiplication_result")
inputDataWithDivisionResult.write.option("overwriteSchema", true).mode(SaveMode.Overwrite).format("delta").save(outputDir)
reader.show(false)
If you enable the check, Delta Lake checks the schema compatibility while getting the snapshot to read:
case class TahoeLogFileIndex(
// ...
def getSnapshot: Snapshot = {
val snapshotToScan = getSnapshotToScan
if (checkSchemaOnRead || snapshotToScan.metadata.columnMappingMode != NoMapping) {
// Ensure that the schema hasn't changed in an incompatible manner since analysis time
val snapshotSchema = snapshotToScan.metadata.schema
if (!SchemaUtils.isReadCompatible(snapshotAtAnalysis.schema, snapshotSchema)) {
throw DeltaErrors.schemaChangedSinceAnalysis(
snapshotAtAnalysis.schema,
snapshotSchema,
mentionLegacyFlag = snapshotToScan.metadata.columnMappingMode == NoMapping)
}
}
And as a result, it generates a nice and self-explanatory error message:
Exception in thread "main" org.apache.spark.sql.delta.DeltaAnalysisException: The schema of your Delta table has changed in an incompatible way since your DataFrame or DeltaTable object was created. Please redefine your DataFrame or DeltaTable object. Changes: Latest type for multiplication_result is different from existing schema: Latest: double Existing: integer This check can be turned off by setting the session configuration key spark.databricks.delta.checkLatestSchemaOnRead to false.
On the other hand, if you work without the flag, the exception will be more mysterious:
Exception in thread "main" org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 18.0 failed 1 times, most recent failure: Lost task 0.0 in stage 18.0 (TID 209) (192.168.1.55 executor driver): org.apache.spark.sql.execution.QueryExecutionException: Parquet column cannot be converted in file file:/tmp/table-file-formats/007_schema_evolution/delta_lake/part-00001-5aa0ffdd-f6f8-478c-b368-4bfea9013787-c000.snappy.parquet. Column: [multiplication_result], Expected: int, Found: DOUBLE
at org.apache.spark.sql.errors.QueryExecutionErrors$.unsupportedSchemaColumnConvertError(QueryExecutionErrors.scala:706)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.nextIterator(FileScanRDD.scala:278)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:116)
at org.apache.spark.sql.execution.FileSourceScanExec$$anon$1.hasNext(DataSourceScanExec.scala:553)
Despite its apparent simplicity, the "schema evolution" term hides a lot of other concepts that, hopefully, you understand now better!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Table file formats - Schema evolution: Delta Lake here:
- Demo: Column Mapping Diving Into Delta Lake: Schema Enforcement & Evolution Delta Lake Schema Enforcement
Related blog posts:
- Commit log decorator with userMetadata property
- Truncating a Delta Lake table, aka metadata-only operations
- Idempotent writer
Schema evolution is yet another great feature of table file formats. To understand it, nothing works better for me than blogging and analyzing the internals! The first part covering the #DeltaLake implementation is in the new blog post ? https://t.co/Z87E5kZRMo
— Bartosz Konieczny (@waitingforcode) April 28, 2023