
In my recent exploration of the compaction, aka OPTIMIZE command, in Delta Lake, I found this famous Z-Ordering mode. It was one of the most outstanding features when I first heard about Delta Lake. You can't even imagine how impatient I was to see what it is doing under-the-hood. Fortunately, this time has come!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Z-Order vs. partitioning
Let's talk first about the Z-Order relationship to the partitioning. First, there are some similarities between these concepts. Both rely on the data layout organization to perform data processing optimizations. However, it also implies the first differences. Partitioning is a pure data layout concept because it's based on the partition path. On the other hand, the Z-Order is a metadata-based optimization requiring statistics on the indexed columns. So it won't be exposed anyhow by the file system or object store. Instead, all relevant information will be stored in the metadata layer (_commit_log).
Second, the type of columns is different for both optimizations. Partitioning works best with low cardinality (= a few distinct values) columns. Otherwise, it can create a significant overhead on the partitions metadata management side (listing, indexing in a data catalog, ...). By contracts, the Z-Order optimization is adapted to high cardinality (= a lot of distinct values) columns. The operation consists of collocating related rows in the same data files and with a few distinct values, it would create big files and finally, could be less efficient than the basic and write-optimized partitioning.
As you can see, both concepts, albeit performing data storage optimization, operate on different levels and apply to different types of columns. Now when this aspect is clear, let's go to the Z-Order algorithm before analyzing how Delta Lake implements it.
Z-Order curve
The Z-Order curve wouldn't be necessary if there were no limitation of the lexicographical order. Unfortunately, there is one concerning multi-columns sort. Let's take this picture where the data is ordered by the columns letter and isVowel:
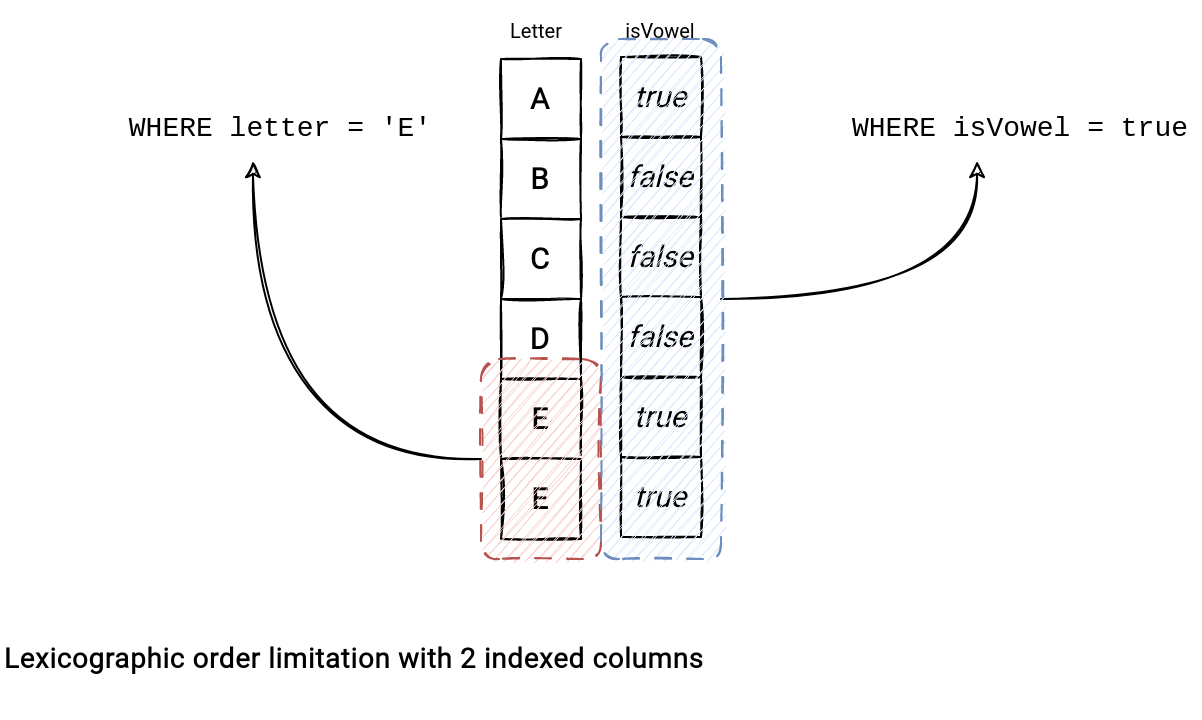
The lexicographic order works well for the first column but not at all if the query involves only the secondary index where the filtering remains local to the query after reading all the rows. Put differently, the search space exploded from a single to 5 places. The Z-Order curve addresses that explosion issue by reducing the search space and colocating close rows from this 2-dimensional space together.
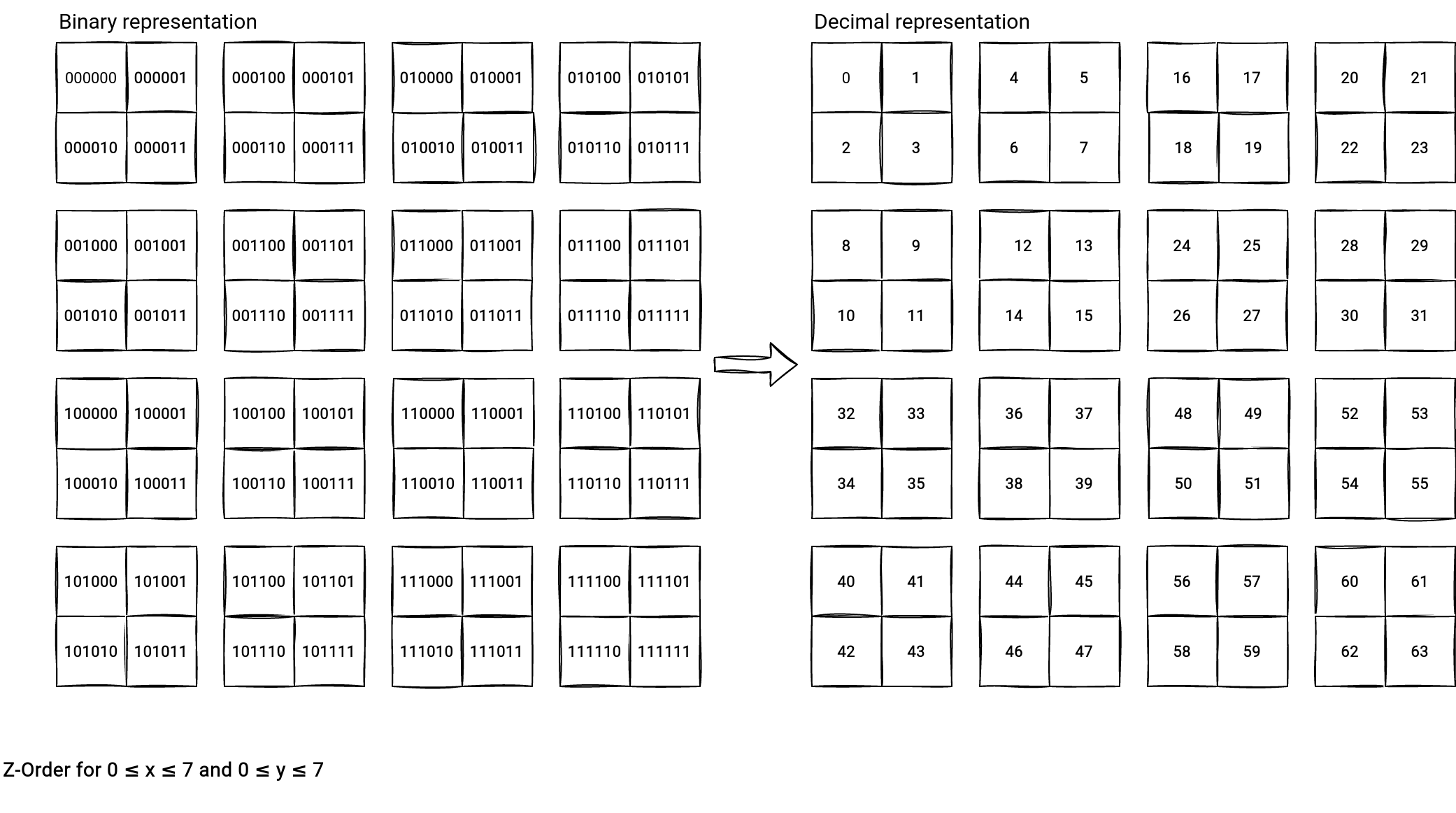
To better understand the collocation, let's check another picture. It shows the lexicographic order for a 2-dimensional space consisting of 0 <= x <= 7 and 0 <= y <= 7:

You can see that the query for the "WHERE x = 0 or y = 0" condition needs to read 9 files. On the other hand, the Z-Order collocated data requires only 7 files:

How does this collocation work? The Z-Order curve interleaves binary coordinate values starting to the right with the x-bit and alternating to the left with the y-bit. How does it impact our previous schema? Let's replace the (x, y) by the Z-Values:
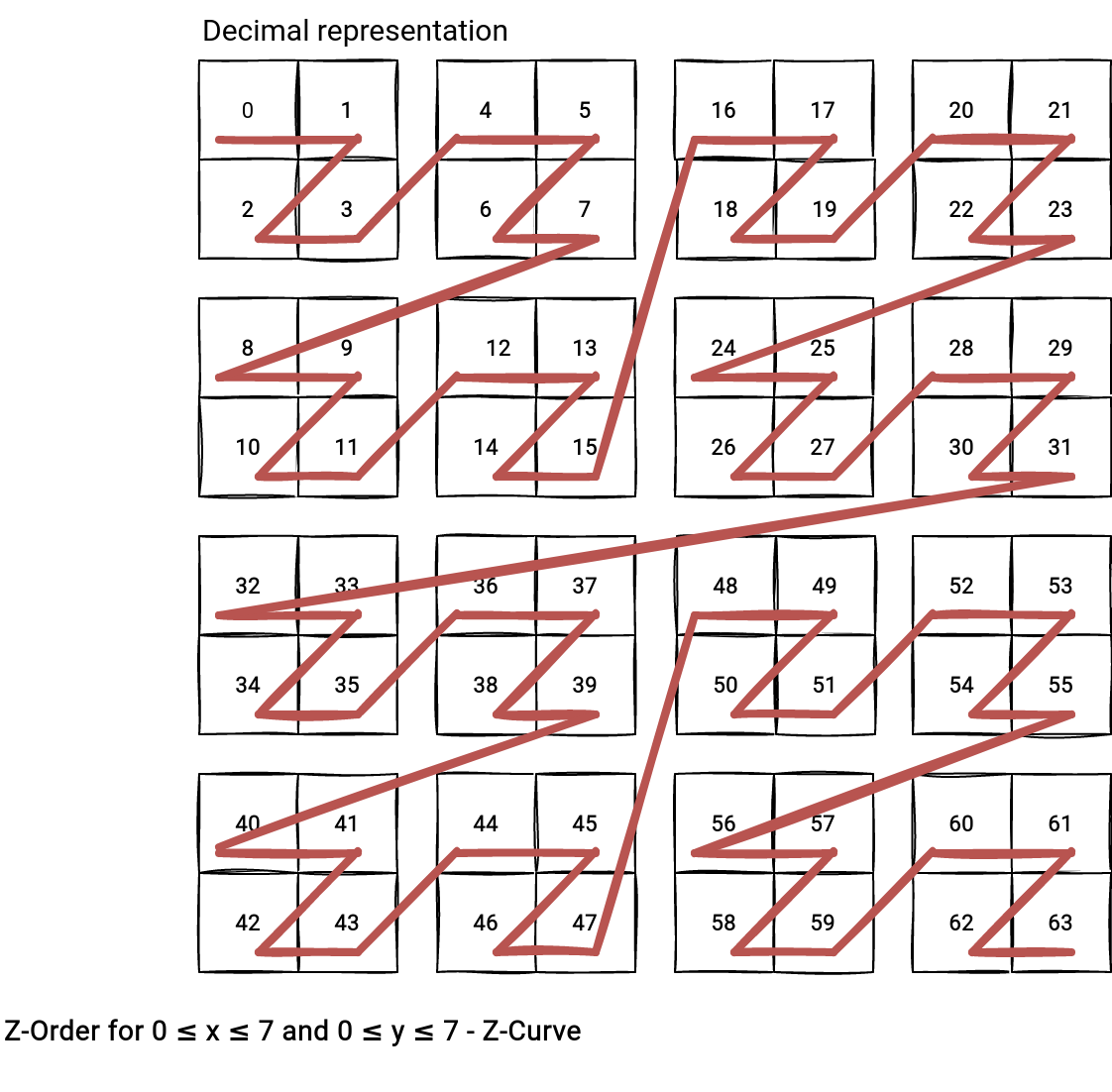
The decimal representation helps understand another point. Why do we call this a Z-Curve? If you connect the numerical values of the decimal representation you will see the Z-pattern appearing:
Z-Order in Delta Lake
After all this theoretical introduction it's time to see Delta Lake implementation of the Z-Order optimization. First, the OptimizeTableCommand looks for the presence of the Z-Order columns in the command. If they are present, it passes them to the OptimizeExecutor and starts the optimization process.
The OptimizeExecutor starts by setting a isMultiDimClustering flag that will be used to adapt the operation semantic:
class OptimizeExecutor(sparkSession: SparkSession, txn: OptimisticTransaction, partitionPredicate: Seq[Expression],
zOrderByColumns: Seq[String])
extends DeltaCommand with SQLMetricsReporting with Serializable {
private val isMultiDimClustering = zOrderByColumns.nonEmpty
What happens next looks similar to the classical compaction job:
- The executor lists all files to optimize. For the case of Z-Order, it processes all files.
- For each partition to optimize, the executor runs the bin-packing algorithm. The difference with the classical optimization is that the operation always generates 1 file per partition.
- For all bin-packs (1/partition), the executor runs the runOptimizeBinJob that physically performs the optimization.
- In the end, the executor adds some Z-Order summary statistics to the metadata.
Although the high-level steps are similar, the bin job is completely different from the classical compaction process. The ZOrderClustering class is responsible for the Z-Order compaction. It changes the execution plan a bit by adding:
- A repartition key column name. The value of that column is the result of the rangepartitionid(${column}) function. Under-the-hood the physical execution for this logical node is delegated to the RangePartitionIdRewrite that creates new numerical partition ids for the columns from the Z-Order expression. The operation performs some sampling on the optimized RDD, so it adds an extra overhead to the process:
case class RangePartitionIdRewrite(session: SparkSession) extends Rule[LogicalPlan] { def apply(plan: LogicalPlan): LogicalPlan = plan transformUp { case node: UnaryNode => node.transformExpressionsUp { case RangePartitionId(expr, n) => // ... val planForSampling = Filter(IsNotNull(exprAttr), Project(Seq(aliasedExpr), node.child)) val qeForSampling = new QueryExecution(session, planForSampling) // ... SQLExecution.withNewExecutionId(qeForSampling) { withJobGroup(session.sparkContext, jobGroupId, desc) { // The code below is inspired from ShuffleExchangeExec.prepareShuffleDependency() // Internally, RangePartitioner runs a job on the RDD that samples keys to compute // partition bounds. To get accurate samples, we need to copy the mutable keys. val rddForSampling = qeForSampling.toRdd.mapPartitionsInternal { iter => val mutablePair = new MutablePair[InternalRow, Null]() iter.map(row => mutablePair.update(row.copy(), null)) } val sortOrder = SortOrder(exprAttr, Ascending) implicit val ordering = new LazilyGeneratedOrdering(Seq(sortOrder), Seq(exprAttr)) val partitioner = new RangePartitioner(n, rddForSampling, true, sampleSizeHint) PartitionerExpr(expr, partitioner) } }This sampling is probably one of the reasons why the Z-Order operation is not idempotent across runs. - A call to the interleavebits function that interleaves the partition ids generated in the previous step. For example, if we had 2 columns in the Z-Order operation, id1 and id2, the whole added part would look like interleavebits(rangepartitionid(id1), rangepartitionid(id2)).
Eventually, the runner can add a column to deal with data skew. You can control this behavior with the spark.databricks.io.skipping.mdc.addNoise flag.
Once the plan with the interleavebits and range partitioning built, the partition DataFrame is repartitioned on the interleaving bits value:
df.withColumn(repartitionKeyColName, mdcCol)
.repartitionByRange(approxNumPartitions, col(repartitionKeyColName))
That way, the compaction process writes Z-Order-optimized data for each partition.
The Z-Order optimization is also present in Apache Iceberg and that will be the topic of the next blog post of my "Table file formats..." series.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Table file formats - Z-Order compaction: Delta Lake here:
- Hudi Z-Order and Hilbert Space Filling Curves Z-order curve How fast can you bit-interleave 32-bit integers? Z-Order: Visualization and Implementation Z-ordering: take the Guesswork out (part2)
Related blog posts:
- Commit log decorator with userMetadata property
- Truncating a Delta Lake table, aka metadata-only operations
- Idempotent writer
The last blog posts this month is about a feature I have always wanted to share, the Z-Order in #DeltaLake ! It's not new and you probably already got the idea from other articles or videos, but maybe you'll learn something new ? https://t.co/sI1ic4VMKF
— Bartosz Konieczny (@waitingforcode) March 30, 2023