
Two great features whose I experienced when I have been working with Dataflow were the serverless character and the auto-scalability. That's why when I first saw the Apache Spark on Kubernetes initiative, I was more than happy to write one day the pipelines automatically adapting to the workload. That also encouraged me to discover the horizontal scalability and this post is the first result of my recent research on that topic.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The post is called "introduction" and I will show here the basic points about the horizontal scalability. Each of sections answers to one question. The first one answers to the "what the horizontal scalability is". The second one focuses on the "when the horizontal scalability is used". The last section explains the "how to implement horizontal scalability nowadays".
What the horizontal scalability is ?
In simple terms, a horizontal scalability is the ability of the system or the application to handle more load by adding more compute resources and, therefore, distribute the work more evenly. It can be described by 2 activities, scale out and scale in. The former one adds more resources to handle load peak whereas the latter does the opposite.
Nowadays adding or removing compute power, which can be a new physical node or simply a new containerized program, is easy. Much harder is to write the applications that may be scaled with a dynamically changing runtime environment. And one of blocking points for scaling is everything with stateful character, of course under the condition that the state is stored alongside the scaled application. Another difficulty is to find a good moment to scale. The workloads can sometimes have small load peaks and a good auto-scaling algorithm should be able to interpret the short-term peaks correctly and not trigger the scaling activity too early and too often.
When the horizontal scalability is used ?
In order to understand the context of the scalability better, let's start by analyzing some of traffic patterns:
- The first one of them is called on/off because the resources are used during some time and after that, they're turned off. Obviously, this pattern exists in all development environments or on-demand analytics pipelines:
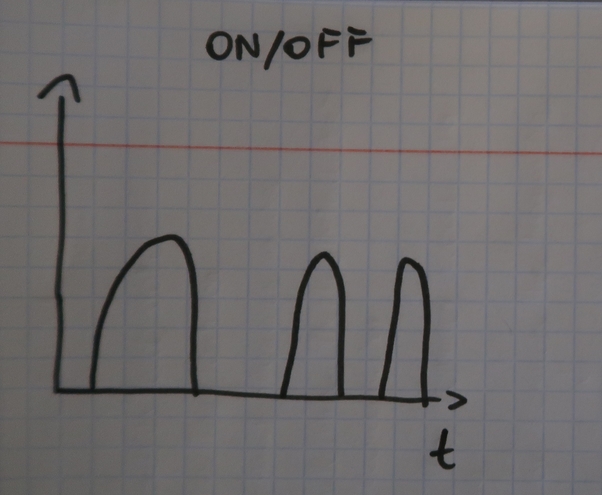
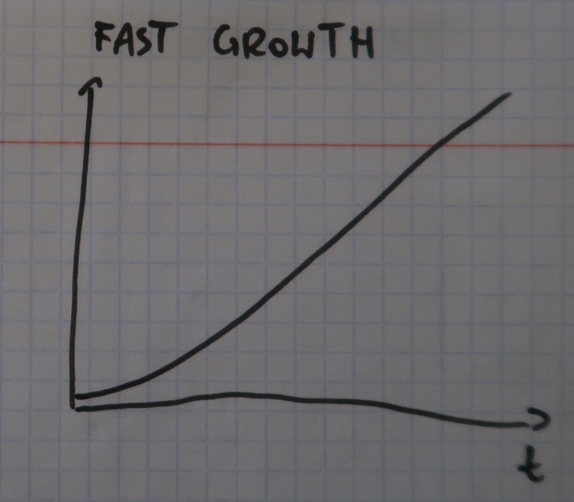
- The second pattern is called fast growth. It's characterized by only increasing load which can be produced, for instance, in case of business growth.
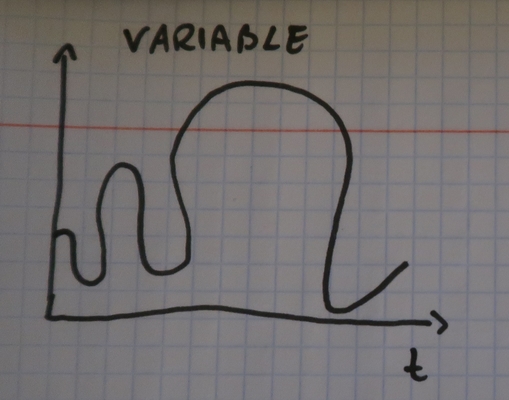
- The next pattern is the first one where the traffic is unpredictable and that's why it's called variable. It will be the case of any news site where one information can make a buzz from time to time and therefore, create an unpredictable load peek:
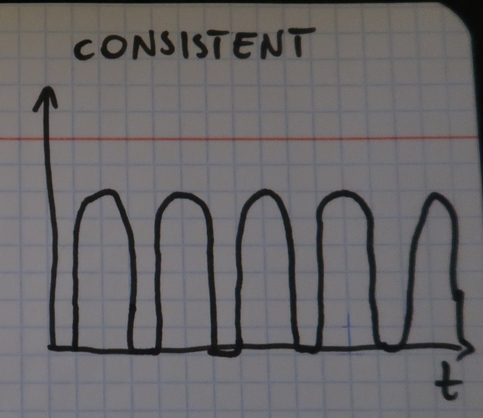
- The final pattern is the opposite of the previous one because it's based on predictable and consistent workload. Because of that it's called consistent and a simple chart could look like in the following image:
Some of these patterns are quite easy to scale. Every time you are able to predict the load, you will be able to put an optimal scaling policy in front of it. On the other side, some patterns like the variable traffic one will be more difficult to scale. As you can see in the picture, the peaks are not constant and because of that, the scaling policy must be dynamic. To implement it you can use different methods. Three of them are the most popular, at least if you take a look at the cloud providers or resource manager frameworks:
- manual - it's a static policy where you define when and how to scale. Because of the static character, it fits pretty well for the predictable workloads. For instance, if you have an e-commerce store and you know that 80% of orders are passed between 8 and 9 PM GMT, you may define a policy to add more servers for that interval. On the other side, if your e-commerce store is worldwide and you have a global success in different continents without the ability to predict the traffic peaks, this scheduling method won't be efficient.
- hardware metrics - the first of dynamic scaling policies presented here uses hardware metrics like CPU or memory use, to decide about the scaling action. For instance, if the decision making systems sees that the CPU of one server is below some threshold, it can decide to put this node down. But in some cases, particularly when the code is not optimized and you want to keep reading the data in real-time, the hardware metrics may not be sufficient.
- custom metrics - this strategy is complementary to the previous one. Here, instead of using hardware metrics, you will use the metrics exposed by your application. For instance, you can define a threshold to say that your streaming consumer is in late and when this threshold is reached, start a new consumer to catch up this late. To implement that you can use different techniques and one of them are technical messages .
Technical messagess
I discovered this technique during Kafka at scale @ Criteo ; Microservices :CQRS, Kafka Stream and BPMN @ QuickSign meetup where Ricardo Paiva presented Criteo's Apache Kafka part.
The idea is to send technical messages, outside the main pipeline. These technical messages contain the real datetime. Now, when this messages is read, the consumer can simply compare its datetime with the real datetime to figure out the processing latency.
However, the methods have some gotchas. First and foremost, the scaling is not immediate, unless you have available compute resources in idle state. The time of creating a new server brings another problem of concurrency scaling. The concurrency issue can lead to some unexpected behavior when, for instance, the first action decided to add a new instance and the second action to remove one at the same time. To support these problems, AWS EC2 uses a cooldown policy which defines the period of time during which only 1 scaling activity can be performed.
Also, the scaling algorithm must be aware of sudden and short load peaks. For instance, you can have a sudden and short CPU use peak caused by a GC action. The algorithm should not consider it as a reason to scale. Another point concerns the number of resources to add. The scaling algorithm, still in order to optimize the resources use, should be able to detect how many compute power must be added in order to absorb the peak.
How to implement horizontal scalability nowadays ?
In this last part let's focus on the horizontal scalability implementation in 2 different contexts. The former context is the one of a cloud provider and in this post, it will be AWS EC2 service. The latter context is about an Open Source resource manager and I decided to check Kubernetes for that part.
The EC2 service provides compute resources that can be easily grouped in a cluster. To scale them, you will need to use an auto-scaling group. It ensures not only the automatic scalability but also the high availability with the monitoring of the minimal number of running instances. The group can be scaled with the metrics exposed natively by the service, like the CPU utilization or the network traffic. Luckily, that's not all. The EC2 instances can also be scaled with the use of custom metrics and CloudWatch alarms attached to the scaling policy. And that's quite flexible since the number of added/removed instances may vary depending on the threshold value.
The scaling policy in Kubernetes is built on 2 levels: cluster and pods. The example of the cluster level is the Cluster Autoscaler (link below the post) which is able to create new nodes when the new pods can't start because of the lack of resources or when some of the already existent nodes are underutilized and their pods can be placed elsewhere. The new pods can be added manually but also automatically by the Horizontal Pod Autoscaler. The autoscaler will add new pods according to the defined hardware metrics (CPU, memory), custom metrics (business-based) or object metrics. To do that, it will check the state of these metrics at a regular interval and when some of them reach the defined threshold, it will take an action to rebalance the load by adding or removing the replicas. The number of replicas is computed from ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )] formula. In the case when different metrics are analyzed, each one will have the desired number of replicas and Kubernetes will select the maximal value.
The ability to scale is the key of modern architectures. An application that can't handle the unexpected load will give a bad image of the service and suggest the customers check elsewhere. Fortunately, after several years of effort, we can implement the horizontal scalability on-premise and on the cloud. The challenging part of that is to find meaningful metrics that will be responsible for driving the scaling. But as I quickly illustrated in the last section, we can use any imaginable values for that thanks to the support of custom metrics.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Introduction to horizontal scalability here:
- Autoscaling best practices Scaling Cooldowns for Amazon EC2 Auto Scaling Autoscaling using Custom Metrics AWS Autoscaling Based On Database Query Custom Metrics Cluster autoscaler Horizontal Pod Autoscaler Scale-Out vs. Scale-Up Techniques for Cloud Performance and Productivity
Related blog posts:
- Data Vault 2.0 and Big Data
- Data modeling with Data Vault - part 1
- Optimistic concurrency control - a little bit of theory and a little bit more examples
Horizontal scalability and elasticity are the musts of these days data pipelines. In today's post some notes about traffic patterns, metrics and implementations (#AWS EC2 and #Kubernetes) https://t.co/YqlCZNvn6n
— Bartosz Konieczny (@waitingforcode) April 10, 2019