
Sequential writes made their proofs in distributed data-driven systems. Usually they perform better than random writes, especially in systems with intensive writes. Beside the link to the Big Data, the sequential writes are also related to another type of systems called log-structured file systems that were defined late 1980's.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post focuses on sequential writes in the context of log-structured file system. The first section explains the sequential writes and their differences with random writes. The second part introduces the concept of log-structured file system (LFS). The last part shows a simple implementation of some concepts of this system in Scala.
Sequential writes defined
Before talking about sequential writes, we'd begin by recall 2 units impacting writing data on flash disks: block and page. A block is the smallest unit that can be erased. In the other side, a page is the smallest writable unit. So to tell simply, when we write a new file, we write the pages and when we remove one, the work is done on blocks.
With this short recall we can now see what happens for sequential writes. A sequential write occurs when the block written by given operation directly follows the last block of previous I/O operation. Thus as we can correctly deduce, the data is written per block basis. It guarantees a good write performance as well for file creation and removal operations.
It's not the case of random writes where the pages are written sequentially but throughout the blocks. Thus one block can store the data belonging to 2 or more different files. As you imagine, it makes the I/O operations more complex - especially for the removal when the erased block contains both valid and invalid data. For this case, the valid data must be moved to other block. Since the sequential writes work per block, most of time there is no need to move parts between blocks.
Another difference concerns classical magnetic disks. In these traditional disk-based systems the random writes are based on "seek-write-seek-write" pattern. Each seek takes about 10 ms and since random writes make a seek for each write, this operation automatically takes longer than sequential one where seeks don't exist. The difference is less visible for the case of already quoted flash disks that don't have moving parts. However it can also be observed here, especially when data smaller than page size is written.
Log-structured file system
The LFS is based on the following concepts:
- append-only log - the writes are sequential and they're done in an append-only log data structure.
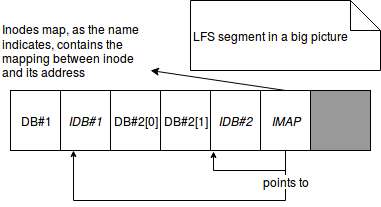
- segments - all writes (data + metadata) are buffered in an in-memory large segment (typically of some MB). A segment contains a lot of data blocks and inodes. When it's full, it's written to the append-only log. More precisely, each segment is composed of:
- inodes
- directories
- inode map
- log of directory changes
- segment summary that contains the pointer to the next summary (of next segment) and helps to identify for file block: the inode number and relative block number (offset)
- immutability - the blocks and inodes are never modified. In the case of modification new block(s) and inode are created and written to the new segment at the end of the log.
- inodes - unlike classical file systems, the inodes for the same block in LFS are spread across different segments. Because of the immutability, if the block is modified, it can't be changed in-place. Instead of that, it's written together with new inode in a new segment.
- inodes map (imap) - is an indirection structure helping to locate the most recent version of given inode. The imap chunks are written for each segment. The final imap is assembled on their base and usually is small enough to be cached in memory. In this final imap we can find the mapping between inode and its the most recent address. So if a given block was modified, it's written to a segment with new address to the inode in imap's chunks.
The most recent imap can be found thanks to the structure called checkpoint region. It must be updated every time when a new segment is written because this segment defines new most recent version of imap. - checkpoint region (CR) - it's an important place from the imap's point of view. It references the addresses of the latests chunks of all imaps. In the case of file change, the references stored by CR are very often updated periodically.
The CR is located in fixed place on disk. - garbage collection - the invalid (overriden, removed) data blocks or inodes are removed by the garbage collection process. This process is segment-by-segment basis. The cleaner looks for partially used segments, that means segments with some of used and not used data blocks. Next it compacts still used data and writes the compaction result to new segments that, in their turn, are written to new location. By doing that, the cleaner makes the partially used segments totally available to handling new writes.
The detection of not used data blocks is quite straightforward. The cleaner reads first the segment summary and retrieves the inode number of given data block. Later it checks if the current imap contains block just read. If it's the case, the block is considered as alive. Otherwise, it's considered as dead (not used) and the segment cleaning can begin. Similar thing happens if we append something to a file. The inode containing the map to n-1 addresses (where n is the new number of file blocks) is marked as dead and is removed later by garbage collection process. Only the new inode storing n addresses is considered as alive.
The concepts above can be resumed in the following images:
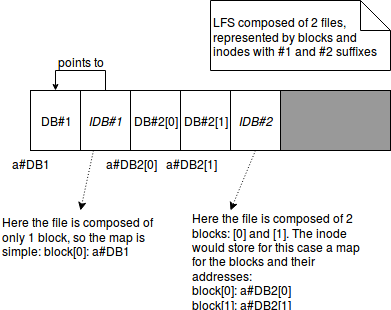
Inode
It's a data structure describing a directory or file in Unix-style file system. It contains some metadata (as time of last change, owner or permissions) and disk block(s) location(s).
In Ubuntu the stats about inodes can be retrieved with df -i command and a simple output can look like:
bartosz:~$ df -i -h Filesystem Inodes IUsed IFree IUse% Mounted on udev 1,5M 578 1,5M 1% /dev tmpfs 1,5M 896 1,5M 1% /run /dev/sda8 34M 1,2M 33M 4% /
The LFS sounds familiar ? Yes, the similar concept is used in Big Data systems such as Apache Kafka. As explained in the introduction to Apache Kafka, it's an append-only log system. We retrieve some of LFS important concepts: data buffering in memory and sequence writes to persistent log file. LFS concept can also be found in Cassandra, especially through commitlog directory.
Log-structured file system example
A simplified version of log-structured file system is implemented in the below snippet:
class LogStructuredFileSystemTest extends FunSuite with BeforeAndAfter with Matchers {
before {
AddressRepository.clear
}
test("should create LFS with 2 segments") {
val segment2 = new Segment()
val segment1 = new Segment(Some(segment2))
val logStructuredFileSystem = getNewLogStructuredFileSystem(segment1)
segment1.addFile(File("README.md", Seq(Block(0, AddressRepository.getNextAddress),
Block(1, AddressRepository.getNextAddress), Block(2, AddressRepository.getNextAddress))))
segment1.addFile(File("LogStructuredFileSystem.scala", Seq(Block(0, AddressRepository.getNextAddress),
Block(1, AddressRepository.getNextAddress))))
segment1.flush(logStructuredFileSystem)
segment2.addFile(File("log4j.properties", Seq(Block(0, AddressRepository.getNextAddress))))
segment2.flush(logStructuredFileSystem)
val stringifiedLfs = logStructuredFileSystem.stringify()
stringifiedLfs should equal("CR (INodeMap(Map(README.md -> A#3, LogStructuredFileSystem.scala -> A#6, " +
"log4j.properties -> A#8))) | Block#0 | Block#1 | Block#2 | README.md; address[0]=A#0, address[1]=A#1, " +
"address[2]=A#2| Block#0 | Block#1 | LogStructuredFileSystem.scala; address[0]=A#4, address[1]=A#5| " +
"Block#0 | log4j.properties; address[0]=A#7")
}
test("should append new fragment to file") {
val segment2 = new Segment()
val segment1 = new Segment(Some(segment2))
val logStructuredFileSystem = getNewLogStructuredFileSystem(segment1)
// Create the 1st segment with the file to override
segment1.addFile(File("README.md", Seq(Block(0, AddressRepository.getNextAddress),
Block(1, AddressRepository.getNextAddress), Block(2, AddressRepository.getNextAddress))))
segment1.flush(logStructuredFileSystem)
// Append new fragment in another segment
segment2.appendToFile(File("README.md", Seq(Block(3, AddressRepository.getNextAddress))),
logStructuredFileSystem.checkpointRegion.mostRecentINodeMap)
segment2.flush(logStructuredFileSystem)
val readmeFileBlocks = logStructuredFileSystem.readFile("README.md")
readmeFileBlocks should have size 4
// It's 0, 1, 2 and 4 because 3 and 5 addresses are taken by inodes
readmeFileBlocks should contain allOf("A#0", "A#1", "A#2", "A#4")
}
test("should override the file") {
val segment2 = new Segment()
val segment1 = new Segment(Some(segment2))
val logStructuredFileSystem = getNewLogStructuredFileSystem(segment1)
// Create the 1st segment with the file to overriden
segment1.addFile(File("README.md", Seq(Block(0, AddressRepository.getNextAddress),
Block(1, AddressRepository.getNextAddress), Block(2, AddressRepository.getNextAddress))))
segment1.flush(logStructuredFileSystem)
// Create the final segment overriding the file from the 1st segment
segment2.addFile(File("README.md", Seq(Block(0, AddressRepository.getNextAddress))))
segment2.flush(logStructuredFileSystem)
val readmeFileBlocks = logStructuredFileSystem.readFile("README.md")
readmeFileBlocks should have size 1
readmeFileBlocks(0) should equal("A#4")
}
test("should remove not used blocks and inodes") {
val segment3 = new Segment()
val segment2 = new Segment(Some(segment3))
val segment1 = new Segment(Some(segment2))
val logStructuredFileSystem = getNewLogStructuredFileSystem(segment1)
// Create the 1st segment with the file to override
segment1.addFile(File("README.md", Seq(Block(0, AddressRepository.getNextAddress),
Block(1, AddressRepository.getNextAddress), Block(2, AddressRepository.getNextAddress))))
segment1.flush(logStructuredFileSystem)
// Create the next segment with another file
segment2.addFile(File("about.html", Seq(Block(0, AddressRepository.getNextAddress))))
segment2.flush(logStructuredFileSystem)
// Create the final segment overriding the file from the 1st segment
segment3.addFile(File("README.md", Seq(Block(0, AddressRepository.getNextAddress))))
segment3.flush(logStructuredFileSystem)
val invalidAddresses = GarbageCollector.getInvalidAddresses(logStructuredFileSystem)
invalidAddresses should contain allOf("A#0", "A#1", "A#2")
}
private def getNewLogStructuredFileSystem(firstSegment: Segment): LogStructuredFileSystem = {
val checkpointRegion = new CheckpointRegion(Some(firstSegment))
new LogStructuredFileSystem(checkpointRegion)
}
}
class LogStructuredFileSystem(val checkpointRegion: CheckpointRegion) {
def addSegment(segment: Segment): Unit = {
checkpointRegion.mostRecentINodeMap = buidNewMostRecentINodeMap(segment.getINodeMap)
}
def stringify(): String = {
val stringifiedCheckpointRegion = checkpointRegion.stringify()
var currentSegment = checkpointRegion.firstSegment
var stringifiedSegments = ""
while (currentSegment.isDefined) {
stringifiedSegments += currentSegment.get.stringify()
currentSegment = currentSegment.get.nextSegment
}
s"${stringifiedCheckpointRegion} ${stringifiedSegments}"
}
def readFile(fileName: String): Seq[String] = {
// Instead of reading a file we'll simply return its blocks
val fileMostRecentINodeAddress = checkpointRegion.mostRecentINodeMap.inodes(fileName)
val mostRecentInode = SystemCache.globalCache(fileMostRecentINodeAddress)
mostRecentInode.blockAddresses
}
private def buidNewMostRecentINodeMap(segmentINodeMap: INodeMap): INodeMap = {
// Please note that the INodeMap creation is often delayed in time
// But here for the reason of simplicity we prefer to build it immediately
val newMap = checkpointRegion.mostRecentINodeMap.inodes ++ segmentINodeMap.inodes
INodeMap(newMap)
}
}
class CheckpointRegion(val firstSegment: Option[Segment]) {
var mostRecentINodeMap: INodeMap = new INodeMap(Map.empty)
def stringify(): String = {
s"CR (${mostRecentINodeMap})"
}
}
class Segment(val nextSegment: Option[Segment] = None) {
private val files = new ListBuffer[File]()
private var iNodeMap: Option[INodeMap] = None
def addFile(file: File): Unit = files.append(file)
def appendToFile(file: File, mostRecentImap: INodeMap) = {
val fileMostRecentINodeAddress = mostRecentImap.inodes(file.fileName)
val mostRecentInode = SystemCache.globalCache(fileMostRecentINodeAddress)
val fileWithOldAndNewBlocks = file.copy(previousBlockAddresses = mostRecentInode.blockAddresses)
files.append(fileWithOldAndNewBlocks)
}
def flush(logStructuredFileSystem: LogStructuredFileSystem): Unit = {
iNodeMap = Some(constructINodeMap)
logStructuredFileSystem.addSegment(this)
}
def stringify(): String = {
val segmentContent = files.map(file => file.stringify).mkString("")
segmentContent
}
def getINodeMap = iNodeMap.get
def getSegmentSummary: Map[String, (String, Int)] = {
val summary: Map[String, (String, Int)] = Map(files.flatMap {
file =>file.blocks.map(block => block.address -> (file.fileName, block.index))
}: _*)
summary
}
private def constructINodeMap(): INodeMap = {
val inodesMap = files.map(file => (file.fileName, file.inode.address)).toMap
INodeMap(inodesMap)
}
}
case class Block(index: Int, address: String) {
def stringify: String = s"Block#${index}"
}
case class INode(fileName: String, address: String, blockAddresses: Seq[String]) {
def stringify: String = {
val addresses = blockAddresses.zipWithIndex
.map(addressWithIndex => s"address[${addressWithIndex._2}]=${addressWithIndex._1}")
.mkString(", ")
s"${fileName}; ${addresses}"
}
}
case class INodeMap(inodes: Map[String, String])
case class File(fileName: String, blocks: Seq[Block], previousBlockAddresses: Seq[String] = Seq.empty) {
val blockAddresses = previousBlockAddresses ++ blocks.map(block => block.address)
val inode: INode = {
INode(fileName, AddressRepository.getNextAddress, blockAddresses)
}
SystemCache.addToGlobalCache(inode)
def stringify: String = {
val blocksSeparated = blocks.map(block => block.stringify).mkString(" | ")
"| " + blocksSeparated + " | " + inode.stringify
}
}
object GarbageCollector {
def getInvalidAddresses(logStructuredFileSystem: LogStructuredFileSystem): Seq[String] = {
// To keep the code simple we don't implement here the segments cleaning part
// Instead we only show how the invalid blocks are detected
var notUsedAddresses: Seq[String] = Seq.empty
val mostRecentIMap = logStructuredFileSystem.checkpointRegion.mostRecentINodeMap
var readSegment = logStructuredFileSystem.checkpointRegion.firstSegment
while (readSegment.isDefined) {
val segmentSummary = readSegment.get.getSegmentSummary
val notUsedSegmentsAddresses = segmentSummary.filterNot(entry => {
val (address, fileWithIndex) = entry
checkIfAddressIsUsed(address, fileWithIndex, mostRecentIMap)
}).map(entry => entry._1)
notUsedAddresses = notUsedAddresses ++ notUsedSegmentsAddresses
readSegment = readSegment.get.nextSegment
}
notUsedAddresses
}
private def checkIfAddressIsUsed(address: String, fileWithIndex: (String, Int),
mostRecentIMap: INodeMap): Boolean = {
val iNodeAddress = mostRecentIMap.inodes.getOrElse(fileWithIndex._1, "")
val inode = SystemCache.globalCache.get(iNodeAddress)
if (inode.isDefined) {
val addressForIndex = inode.get.blockAddresses.applyOrElse(fileWithIndex._2, s"--${address}")
addressForIndex == address
} else {
false
}
}
}
object SystemCache {
val globalCache = mutable.Map[String, INode]()
def addToGlobalCache(inode: INode): Unit = globalCache.put(inode.address, inode)
}
object AddressRepository {
private var currentAddressIndex = -1
def getNextAddress: String = {
currentAddressIndex += 1
s"A#${currentAddressIndex}"
}
def clear = currentAddressIndex = -1
}
This post shown how sequential writes can be used in the construction of log-based systems. In the first section we could discover the main reasons behind sequential writes performance: no time spent on seeks and easier I/O operations based on blocks. The second section introduced a system built on sequential writes - log-structured file system. We could learn its main concepts, such as: segments, append-only character, imap or garbage collection. The last part shown a simple implementation of some of these concepts in object-oriented Scala code.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Log-structured file system here:
- Coding for SSDs – Part 5: Access Patterns and System Optimizations Difference between sequential write and random write Log Structured File System : An Introduction Log-Structured File System (LFS) Log-structured File Systems The Design and Implementation of a Log-Structured File System
Related blog posts:
- Data Vault 2.0 and Big Data
- Data modeling with Data Vault - part 1
- Optimistic concurrency control - a little bit of theory and a little bit more examples
A new post on waitingforcode, this time about log-structured file system. Shows some ideas implemented in #ApacheKafka and #ApacheCassandra https://t.co/kDlexGOPFF
— bardev (@waitingforcode) February 11, 2018