
The popularization of NoSQL data stores brought a new concept in data management called polyglot persistence. This term is very similar to polyglot programming and it'll be presented below.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In this post about polyglot persistence we'll focus on 2 points. The first one, described in the first section, is about the definition of this term. The other one, developed in the remaining parts of this post, will show 2 different implementations of the polyglot persistence.
What is polyglot persistence ?
We can categorize the polyglot persistence as a pragmatic manner of thinking about data storage. After all, does a key-value store is better suited for searching purposes than a search engine ? Or does graph database is less adapted to represent n-level relationships than a RDBMS ? In the polyglot persistence there is no single database responsible for all use cases. If the application represents multiple nested relationships between entities, it'll probably do it in graph form. In the other case, if the same application must implement searching with a "do you mean...?" feature, it'll add a search engine to handle it.
As you can correctly deduce, the polyglot here means that the data is duplicated among different data stores. Of course, to avoid discrepancies in these different storage places, one place can be designated as a source of truth. So called source represents the place where the reference data is stored.
Different criteria exist to choose a good data store. One of them categorizes the data according to its volume and value. And then, for a low-volume but high-value data, as for instance private user information, a RDBMS can be preferred because of ACID. When we need to deal with high-volume but low-value data, as for instance, application logs, then we can opt for a document-oriented solution as MongoDB. Another distinction criteria can be based on data type. For instance, any big files will fit probably better in a DFS (distributed file system) as HDFS or S3, than in a RDBMS as blob columns. Similarly, memory-based stores as Redis will be better suited for caching purposes than a DFS or other store reading the data from disk.
Polyglot persistence implementation: decoupled microservices
This approach represents the situation where 3 different microservices are decoupled and backed by different databases:
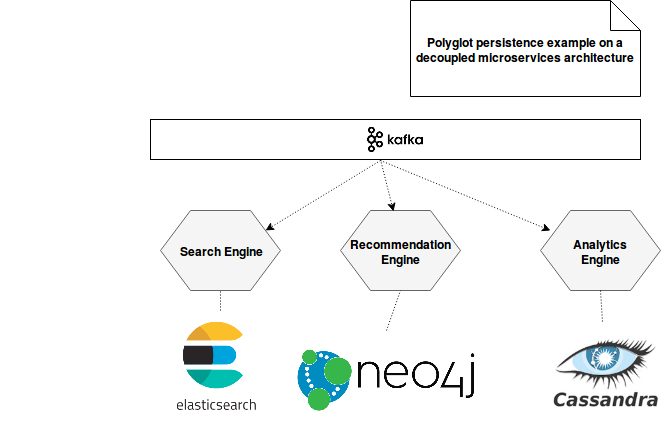
Thanks to the decoupling the services gain in flexibility since they're not dependent on each other. For instance, we can envisage that the Recommendation Engine stores the raw data with an additional enriched user entity and the Analytics Engine contains only counters of an action time extracted from the raw data.
Polyglot persistence implementation: source of truth
A possible schema to represent polyglot persistence with a source of truth could look like in the below image:
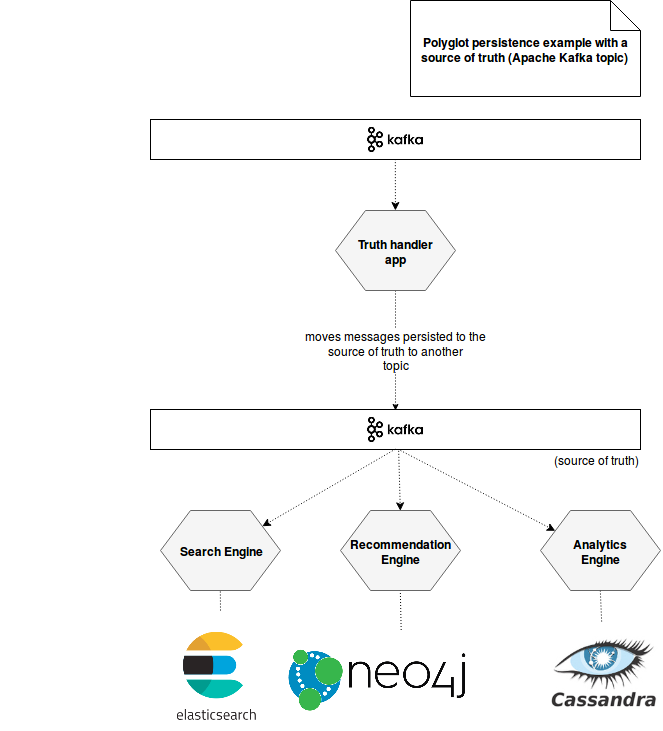
As you can see, Apache Kafka acts as the source of truth for all data exploited later by 3 different engines. In this architecture an intermediary application called Truth handler app was added. Its role consists on reading, validating and enriching the raw data in order to construct one single true representation and persist it in the source of truth storage. Thus after a successful preparation, the data is pushed to another Kafka topic. The remaining 3 user-exposed applications read formatted messages from there.
This approach is similar to the previous one. However, it has an intermediary layer enforcing the data quality. With the previous approach we have a lot of flexibility because the services are independent. They only retrieve the raw data and do whatever they want with it. And it's here where discrepancies can appear because nothing really guarantees that Search Engine and Recommendation Engine will use the same reference to build the valuable data (e.g. can use a different reference database for an entity).
The intermediary layer also guarantees the data consistency. It's obviously the place where an identifier for each raw entry could be computed. In the case of the decoupled microservices, once again each engine could be its own source of truth and generate its own ID. An eventual data reconciliation between services would be painful without a common reference.
But because of the intermediary layer the changes are less flexible. Let's imagine the case where Truth app handler enrichs the raw logs with some information about the users and that retrieving this information costs a lot in terms of loading time. Now the Recommendation Engine needs some more insight and asks Truth app handler team to add these additional entries to enriched data. Depending on adopted schema flexibility strategy, the Search Engine and Analytics Engine can be forced to do some updates - even if the additional input won't be exploited by them. For the decoupled microservices architecture it wouldn't be required since every service has its own enrichment logic.
The polyglot persistence is not a new concept. It was popularized with the development of NoSQL solutions and can be categorized as a pragmatic way to thinking about the data organization. It stores the data in the store adapted to the query pattern (access per key, per not exact pattern) and data type (hight/low value, high/low volume). Two modelisation approaches for polyglot persistance systems were proposed in the last 2 sections. The first one shown independent microservices where each of them is free implements its own data logic. The second example was similar except the fact that it contained an intermediary layer responsible for the source of truth. This source can be used as a data reference stored and helps to keep crucial data properties consistent among the services.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Polyglot persistence - definition and examples here:
- Designing microservices: Data considerations NoSQL, Heroku, and You What is Polyglot Persistence? Polyglot persistence The Force.com Multitenant Architecture
Related blog posts:
- Data Vault 2.0 and Big Data
- Data modeling with Data Vault - part 1
- Optimistic concurrency control - a little bit of theory and a little bit more examples