
Having a scalable architecture is the nowadays must but sometimes it may not be enough to provide consistent performance. Sometimes the business requirements, such as consistent delivery time or ordered delivery, can add some additional overhead. Consequently, scalability may not suffice. Fortunately, there are other mechanisms like backpressure that can be helpful.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Backpressure 101
Backpressure protects a system against being overloaded. Let's say your data consumers have a limited compute capacity and you can scale them up to a limit. What happens when you reach this limit but the data producers continue sending more and more data? At best, the consumer will accumulate some delay. At worst, it'll fail.
But generally speaking, it'll behave hazardously. To avoid such variations and unpredictability you might need to implement a backpressure mechanism that will guarantee a stable and predictable behavior. How? Let's see some of the examples in the next section.
Backpressure and the data systems
Generally we can distinguish 3 different backpressure approaches:<:p>
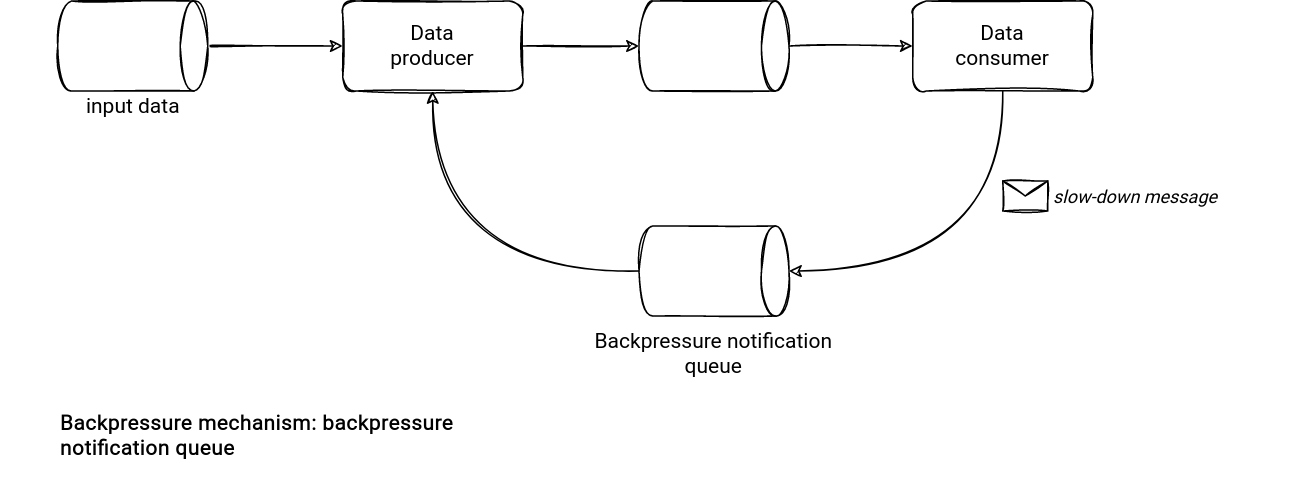
- Ask the producer to slow down. In this approach the consumer must inform the data producer that the generation is too fast. It's easy to implement for microservices communication but turns out to be more challenging for a data system. For example, imagine that you have 2 Apache Spark streaming jobs where one reads the data produced by another from a streaming broker. There is an easy way to slow down the generation? The solutions do exist but require some additional complexity in the system.
- Buffer the extra load on the consumer side. Here the consumer is fully responsible for the throughput management. The data producer is not even aware of the existence of the backpressure mechanism! Sounds ideal but depending on the consumer technology (stateful, stateless), having it implemented may also require an extra effort.
- Reject the extra records on the consumer side. That's definitely the easiest choice. However, it has this major issue of dropping the data.
Let's discuss these 3 approaches with the examples.
Producer slowing down
If we take the aforementioned example with 2 dependent Apache Spark Structured Streaming jobs (let's call them A → B for simplicity), how to make them communicate? The first solution uses technical messages delivered to a technical queue. In normal circumstances, the job A continuously generates the data to process and at the end of each micro-batch, looks at the new backpressure messages in the shared queue. If there is nothing new, it continues at the previous rate. Otherwise, it sends less records and stores the extra ones in an internal buffer.
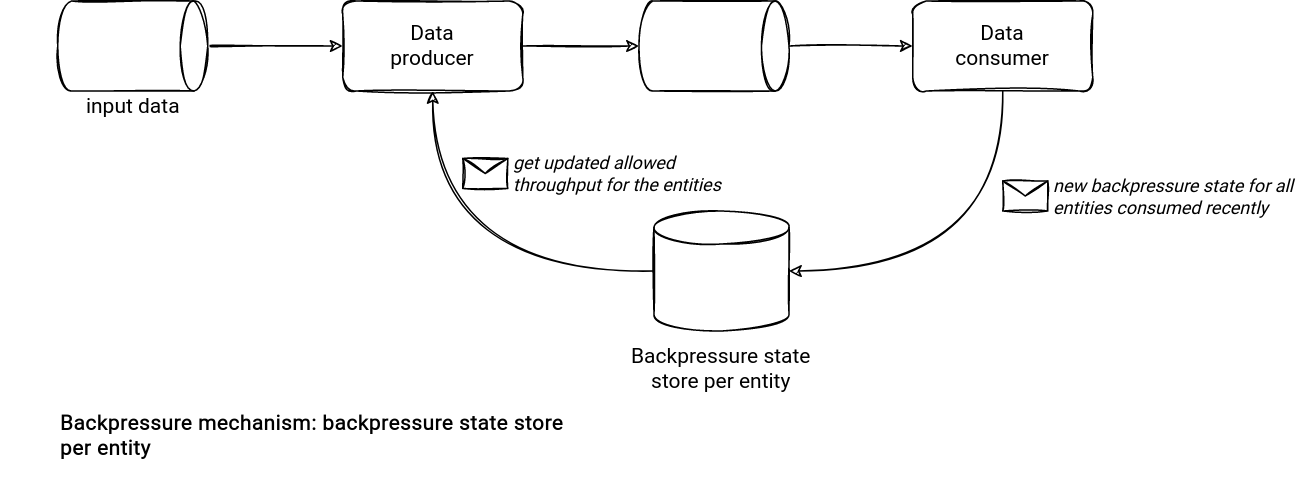
This queueing approach is not the only one. As an alternative, you can use a shared fast-access data store, such as a key/value store or an in-memory cache with persistence layer. The difference? The database-based approach seems better fitting into the scenarios requiring backpressure per record. The backpressure can be about the whole throughput but also only about a throughput per client in a multi-tenant data producer.
The solution here checks whether the client's key is present in the database before delivery the records to the consumer. It's an all-or-nothing design but it can be extended to the capacity-based solution by simply storing the number of allowed messages in the column of the table.
Consumer buffer
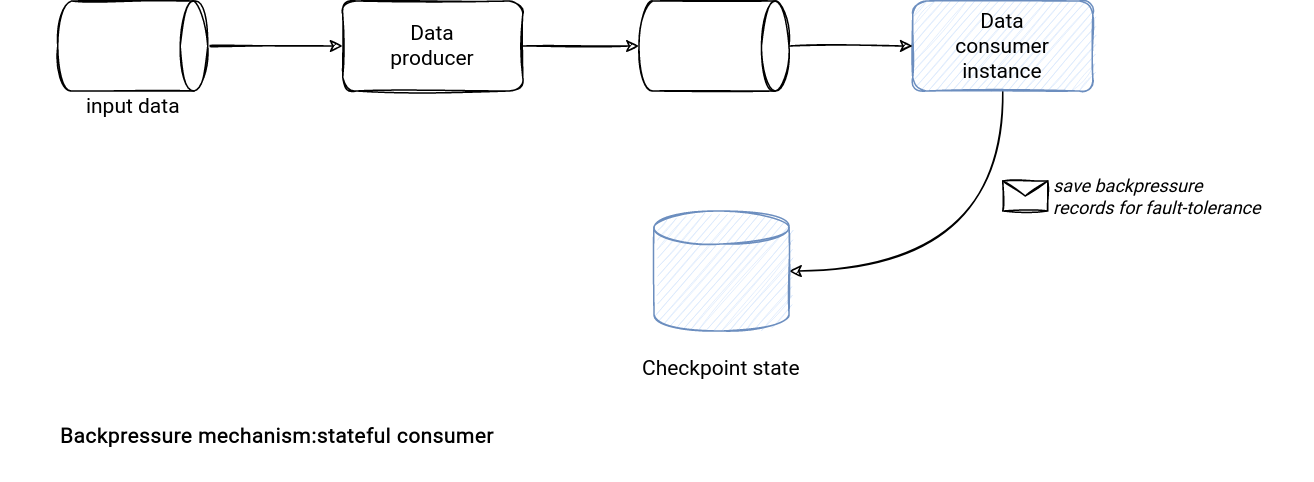
When it comes to the consumer buffering, here the coding implementation is easy if you have stateful consumers. By "stateful" here I mean a consumer that might change the runtime but keep its identity. The identity is very helpful to checkpoint all buffered records for fault-tolerance in case of a failure or the previously mentioned, runtime environment relocation.
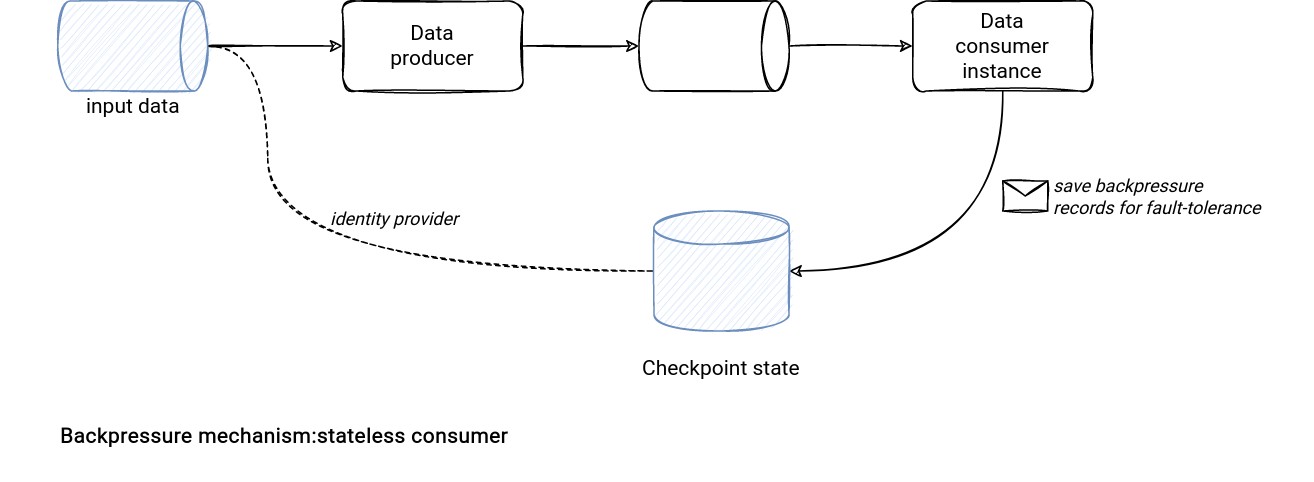
The situation is different for a stateless, so an identity-less consumer. It can be relocated at any time and you don't have a clear way to recognize the specific instance. Hopefully, there is maybe a solution. If your consumer is always responsible for the same partition, such as a partition from an Apache Kafka topic, or a partition from a dataset stored on S3, you can rely on this information to make it stateful. Put another way, the consumer id is the partition it processes. A drawback for that approach, though, is the inability to have multiple concurrent consumers per partition.
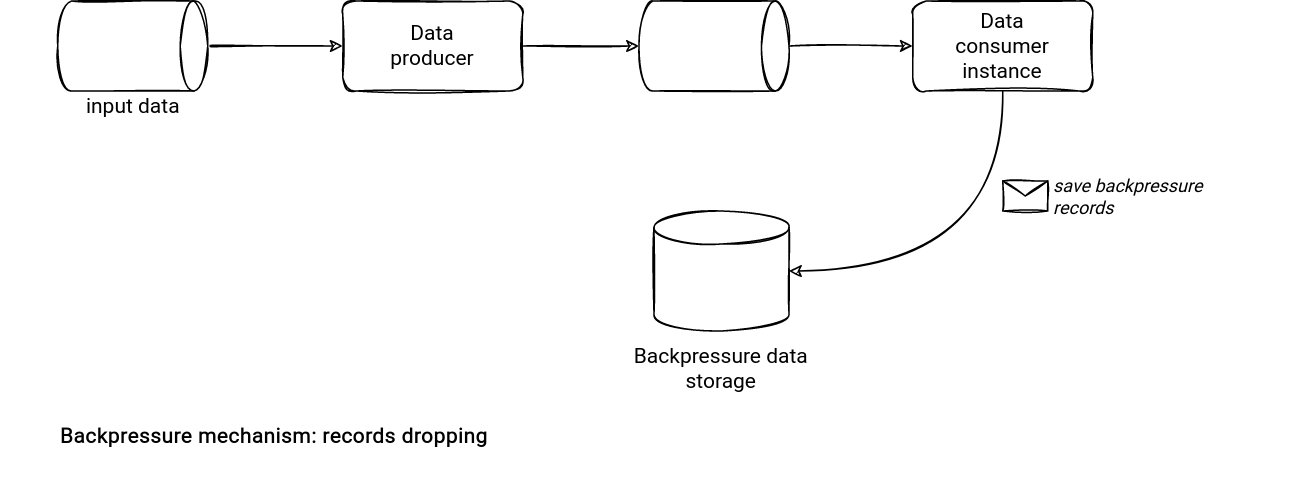
Records dropping
Finally, the records dropping. Here the consumer can ignore processing extraneous records if it doesn't have enough capacity. The ignore can take 2 forms. The consumer can silently drop the records and forget about them or save them into a backup storage. The latter is better but still has some I/O overhead. To keep it the least impactful possible to the main pipeline, the backup storage should be very basic and write-optimized, without writing overhead. For example, an RDBMS with indexes might not be well-suited for this task but a cloud object store should be.
Backpressure is another software engineering concept that might integrate to the data systems. There is for sure the implementation difference but overall, it fulfills the same purpose of limiting the throughput for a consumer.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Backpressure in the data systems here:
Related blog posts:
- Infoshare 2024: Stream processing fallacies, part 2
- Infoshare 2024: Stream processing fallacies, part 1
- Event time skew in stream processing
- Files streaming is quite a challenge
- Stream processing models
Backpressure is often the term related to software engineering. However, consumers in data systems may also need to slow down. I analyzed how in the new blog post ? https://t.co/kQMXNtRG3U
— Bartosz Konieczny (@waitingforcode) February 23, 2023