
After a 2-years break, I had a chance to speak again, this time at the Big Data Warsaw 2023. Even though I couldn't be in Warsaw that day, I enjoyed the experience and also watched other sessions available through the conference platform.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
I learned the hard way that it's impossible to do everything when it comes to watching all the talks of any conference. That's why I only select some of them that match my current topics of interest. Below is the list for Big Data Warsaw 2023, including streaming processing, data lineage, and some DataOps.
Streaming processing
Apache Flink: Introduction and new Features by Robert Metzger
In the first talk Robert Metzger gave a quick introduction to Apache Flink and its 3 primitives:
- Events, aka the processed data represented as an execution dataflow.
- State. Current state of the job stored in a durable datastore via periodic checkpoints.
- Time. Event time represents here the time when something happened. Watermark is the virtual clock for event time.
All these primitives are available from different APIs:
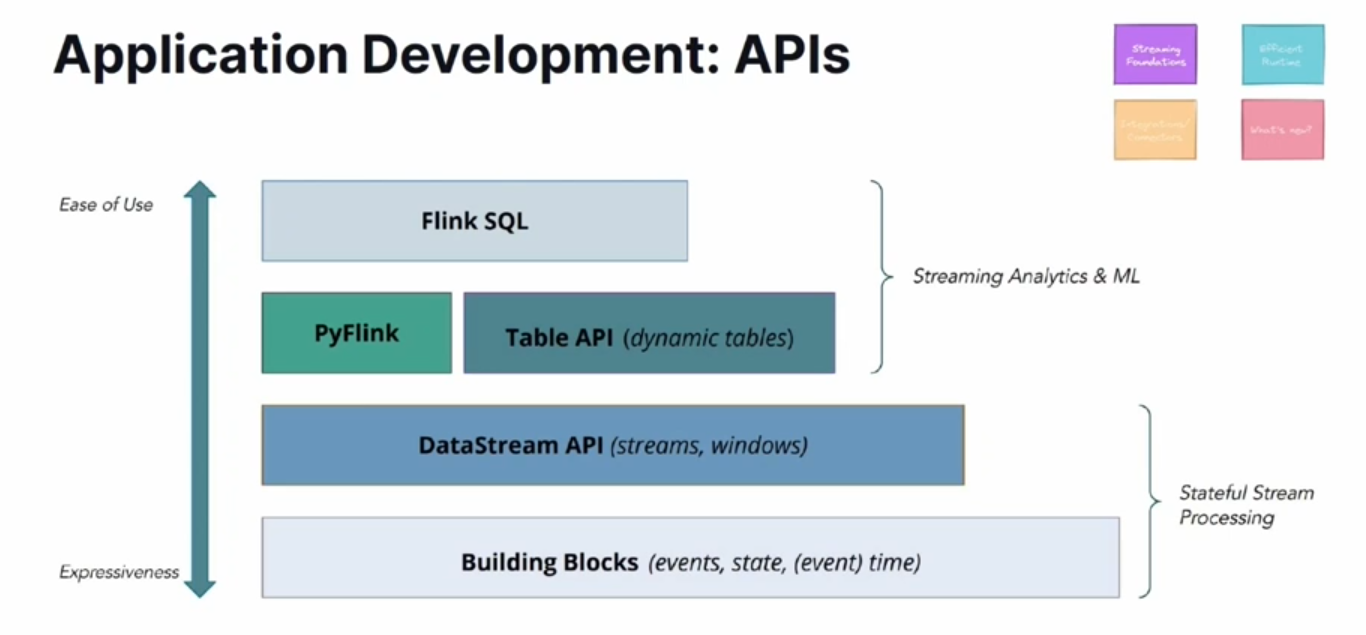
Besides the introduction, Robert also shared more low-level details about:
- Checkpoints. Apache Flink doesn't use a naive approach with the stop-of-the-world where the whole processing stops before the checkpoint is made for all operators. Instead, it supports a continuous checkpoint based on the following steps:
- Checkpoint coordinator asks the sources to perform the checkpoint.
- The sources do the checkpoint and propagate a checkpoint barrier to the execution dataflow.
- The barrier goes to all downstream operators that individually stop the data processing and perform the checkpoint.
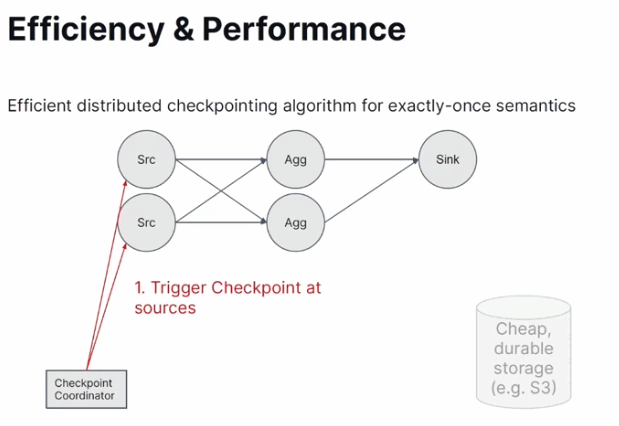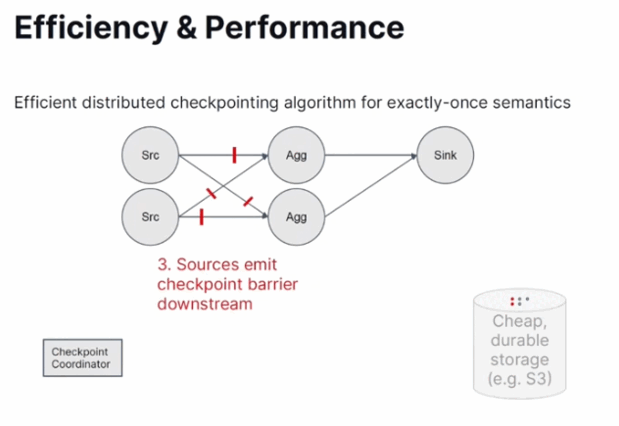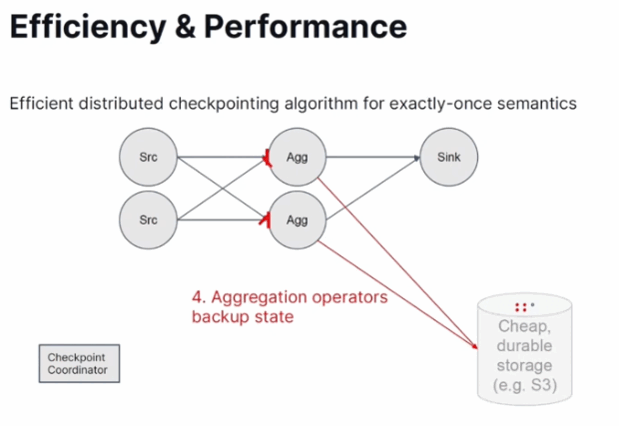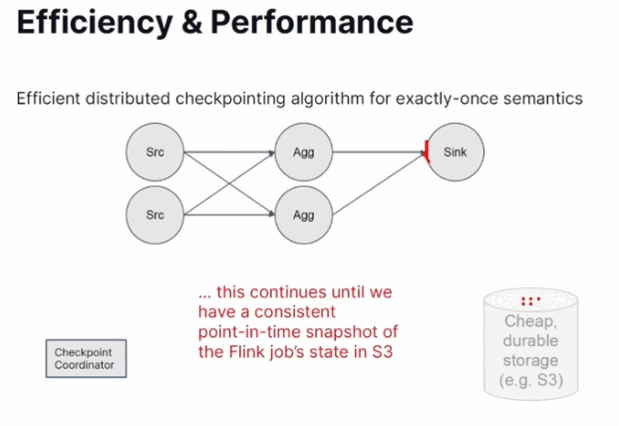
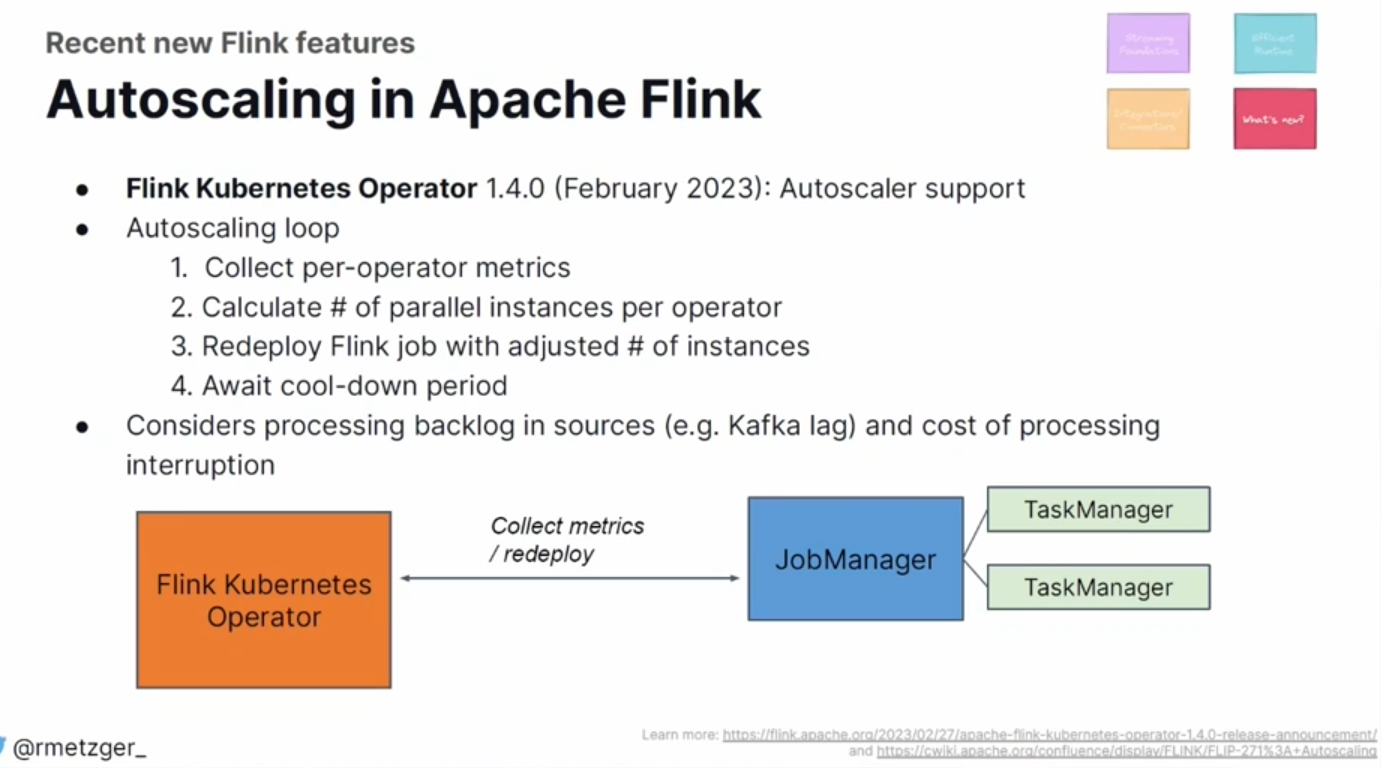
- Auto-scaling. In February Apache Flink got an improved autoscaling support based on real data. In a nutshell, the framework analyzes the backlog and calculates the compute power required to reduce it.
Where is my bottleneck? Performance troubleshooting in Flink by Piotr Nowojski
Another Apache Flink-related talk was about jobs troubleshooting. Piotr Nowojski shared how to fix different job issues. But before giving the list, Piotr highlighted a very important part. Before any action, we should start by identifying the troubleshooting category:

After that, Piotr started his investigation. The first step is to identify the bottleneck and the easiest way to do so is using the UI and Apache Flink color schemes applied to overloaded or poorly performing operators. Summary of that part in the slide below:

Later on the debugging flow looks similar to what you could have done before, including checking the JVM status (CPU usage, GC pauses) or code analysis. Moreover, there is a Flame Graphs integration that gives an even more detailed view of what the code is doing. And if it's not enough, you can always attach the task profiler to the subtask(s) causing problems. In case of multiple threads ran by the task manager, you should find the thread named after the problematic subtask(s) and analyze it.
When it comes to the checkpointing, as you already know, Apache Flink uses checkpoint barriers injected to the execution graph. Despite its innocent nature, checkpoints can also become a bottleneck. How to identify them? Again, start with the UI. If there is nothing wrong with the general view, dig into each subtask and check its checkpoint statistics.
The final bottleneck issue was related to job recovery. No luck here, there are no metrics for that part in the UI. The starting point should be then debug logs. The remediation actions will probably be related to the state itself. For example, adding more reading threads for RocksDB or playing with the state size could help.

Monitor Fleet in Real-Time Using Stream SQL by Gang Tao
Gang Tao gave another talk about streaming. He showed how to use SQL in this real-time context, recalling some important fundamentals. The first is the difference between the classical batch SQL and the real-time one. Nothing better than the screenshot to summarize it:
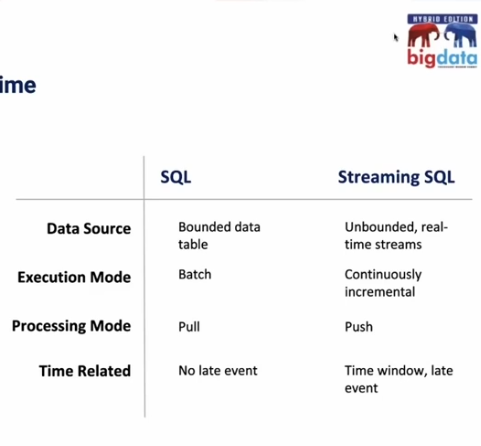
There is also a difference for the latency. A batch SQL measures the latency as the query execution time while a streaming SQL as a gap between the event time and processing time:
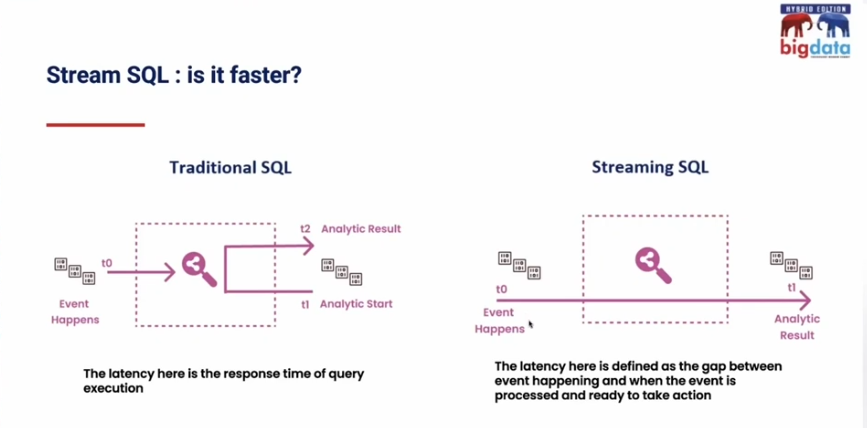
Near-Real-Time streaming applications monitoring and automated maintenance at billions of records/day scale: the architecture allowing us to sleep at night by Giuseppe Lorusso
Giuseppe Lorusso presented a way to monitor streaming applications with Open Source solutions. In a nutshell the architecture looks like that:
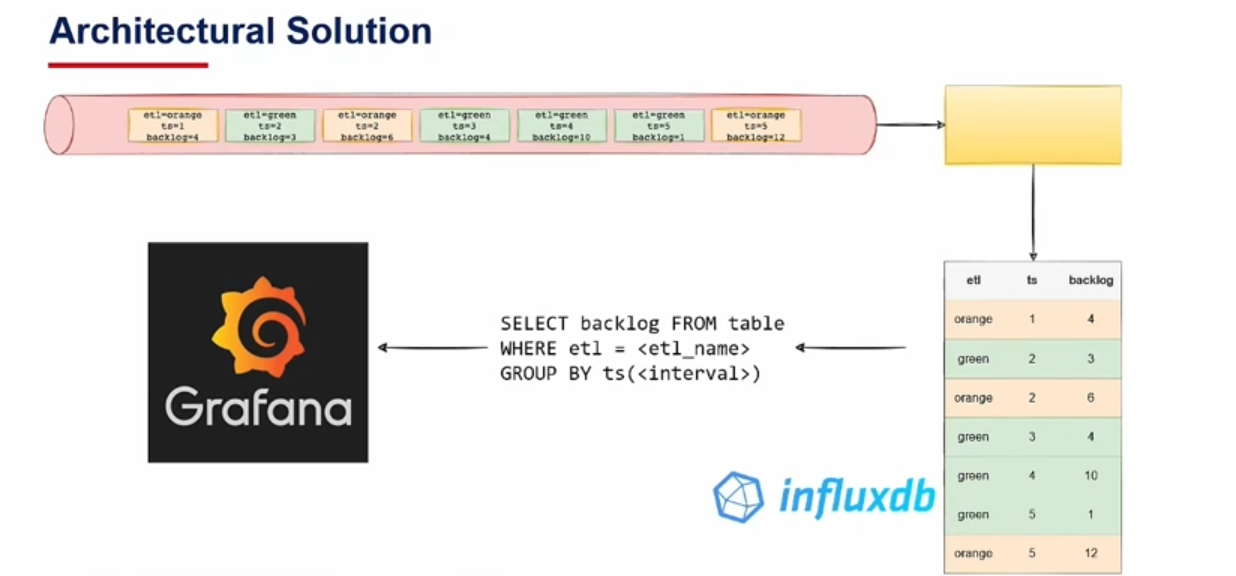
More specifically:
- A streaming job calculates the lag which is the difference between the last processed offset and the last offset available in the Apache Kafka topic.
- The job sends the result to a monitoring topic.
- A new consumer reads the topic and pushes the metrics to an InfluxDB table used as a backend for Grafana.
Grafana alerts on 2 different situations:
- Slow processing - the processing time is higher than a threshold for several consecutive minutes.
- Broken processing - there is no processing time data in the dashboard.
Data lineage
Column-level lineage is coming to the rescue by Paweł Leszczyński and Maciej Obuchowski
The first talk about the data lineage on my list was given by Paweł Leszczyński and Maciej Obuchowski, with a pretty original format of a Jupyter notebook!
In the introduction Paweł mentioned a data mess that is a side-effect of implementing data mesh without the data lineage. Data lineage which from this standpoint is important not only to solve problems when they arise but also to avoid them!
In a nutshell, OpenLineage is a dependency that injects some code trying to extract the metadata from the data processing layer such as a SQL query or an Apache Spark job. The extraction result goes later to one of the supported data lineage backends (Amundsen, Marquez, ...).
After the introduction, Paweł and Maciej moved to the demo. First, Paweł showed how to use OpenLineage for an Apache Spark job with no extra code! It was only a matter of adding new dependency and configuring the lineage transport (HTTP, console, Apache Kafka among the supported ones):
Later, Maciej proved that there is not a lot of work to do for the SQL queries integration with OpenLineage. As for Spark, it was only a question of bringing an extra library and calling it on top of the executed query:
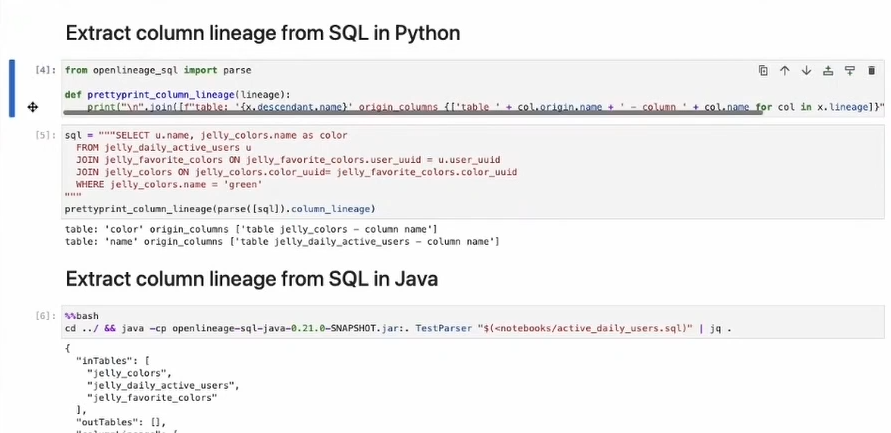
Both demos showed the column-level lineage which is one of many features of OpenLineage!
An open standard for data lineage by Ross Turk
Another OpenLineage talk was given by Ross Turk. Unlike the one about column-level lineage, this one covered the data lineage topic more broadly.
First, Ross explained 3 different approaches that you can use in a data lineage implementation:
- Pipeline observation. Here the tool integrates with the data orchestrator and as soon as the pipeline runs, it updates the internal lineage repository. It provides a real-time semantic but is often reduced to the data orchestration layer and won't apply to the datasets created elsewhere.
- SQL parsing. It's not real-time but provides the information for other dataset creation places, such as ad-hoc queries.
- Source code analysis. The approach analyzes the code, looks for the queries, and prepares the lineage before the job execution.
There is no one-size-fits-all solution able to capture all scenarios. Ross calls it a patchwork where the combination of the presented approaches gives a more complete overview of the lineage.
In the next part, Ross shares some important information about OpenLineage itself:
- OpenLineage uses a push model where the analyzed lineage data goes to an OpenLineage backend.
- OpenLineage integrates with other data components, such as orchestrators, processing frameworks, or metadata services

- OpenLineage is not only about tracking the datasets. It covers much more!

DataOps
Applying consumer-driven contract testing to safely compose data products in a data mesh by Arif Wider
Arif Wider gave an interesting talk about data products and data mesh. He started with some data mesh reminder and an interesting data product definition:
Data product is the smallest independently deployable unit that you use in a data mesh architecture to basically compose anything else of. It's the smallest building block to create solutions.
The composition is made possible with the input and output ports, as shows the following slide:
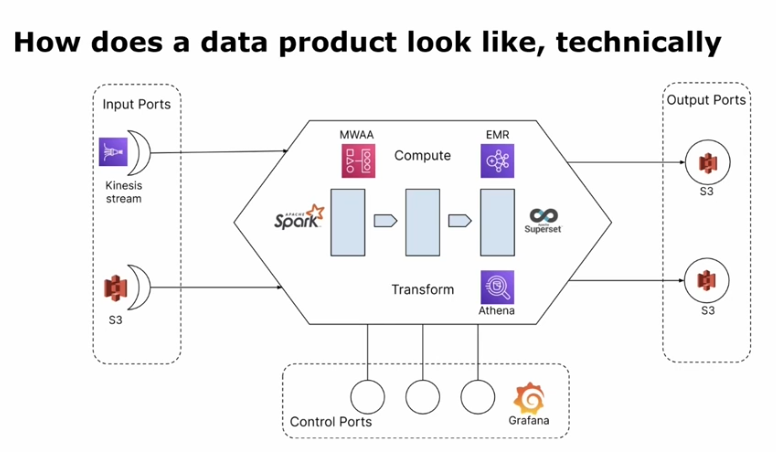
Direct data exposition also brings some data quality risk and the contracts are here to mitigate them. Generally, a contract is about the assumptions and expectations. Data mesh promotes SLO and SLA as the contracts because they make things more explicit.
Additionally, there is a complementary way to reduce the risk with consumer-driven contracts. The idea comes from the software engineering and was initially shared in the The Practical Test Pyramid blog post. How does it apply to data products? Arif answered that in these 2 slides:
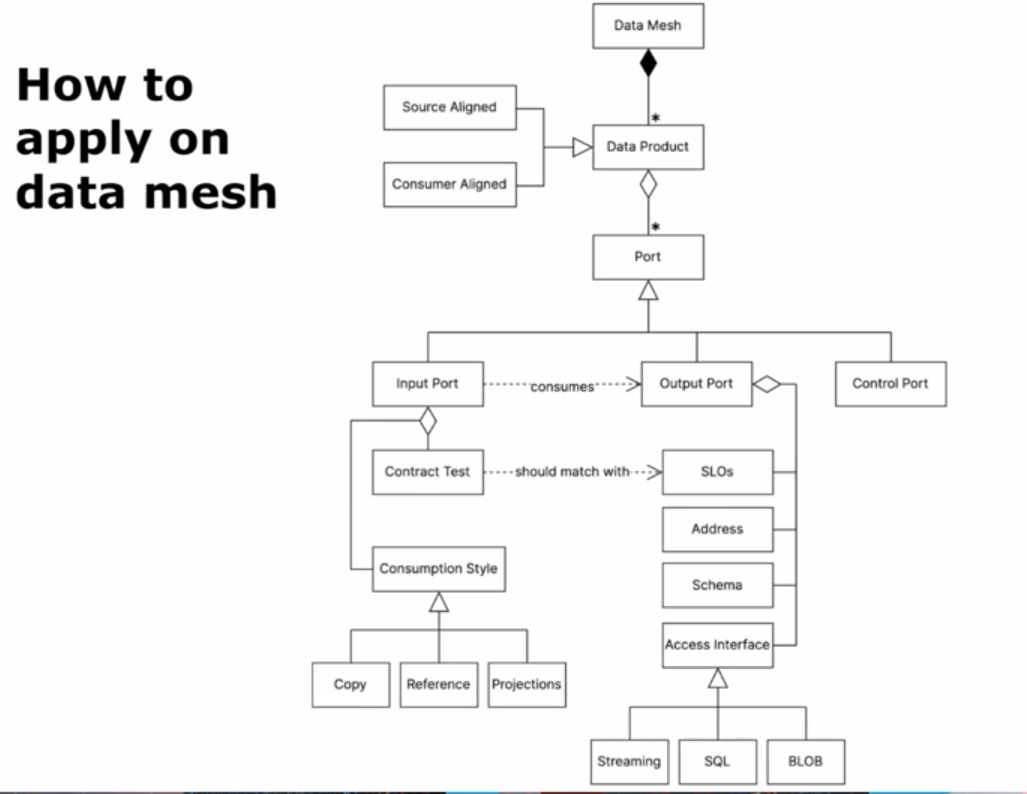
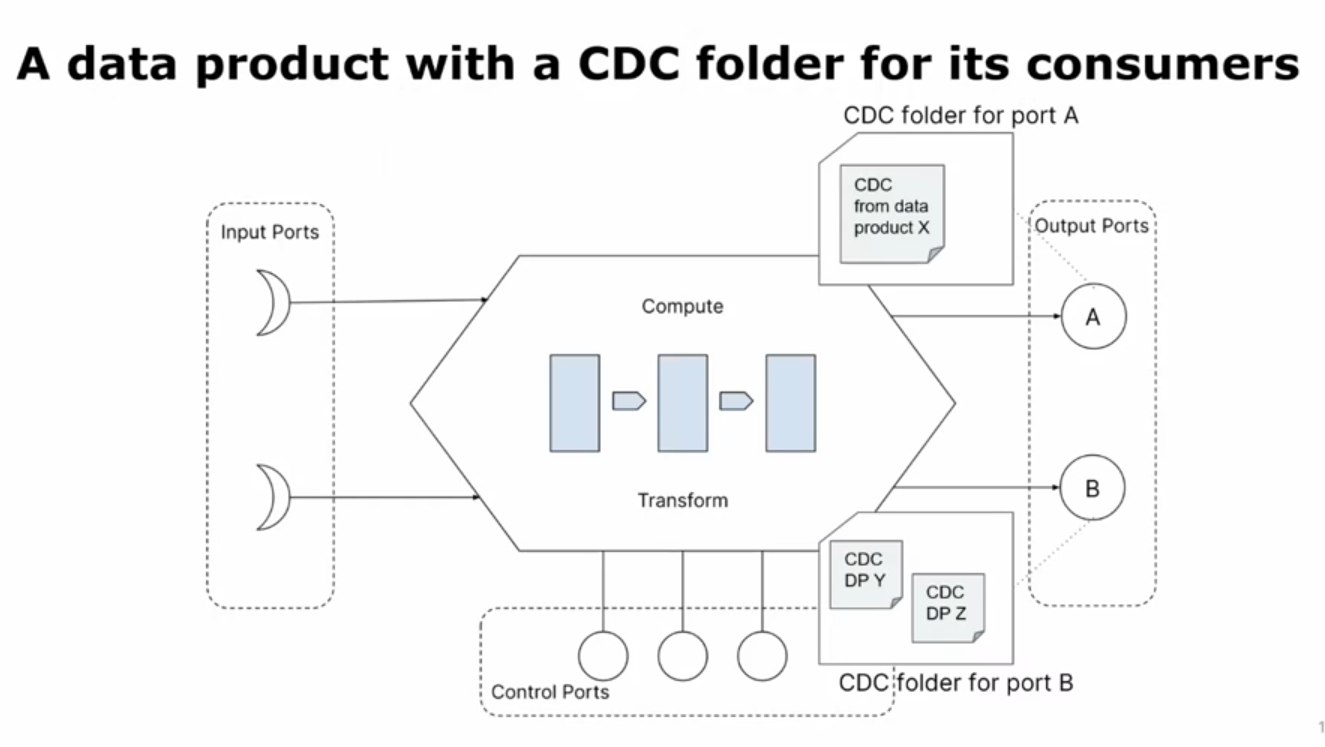
The idea is to associate tests with the output ports but the tricky part is the responsibility shift. Usually the producers apply tests, such as unit or integration tests at the code level. Here, the tests creation is the responsibility of the consumers (aka other data products)! They put their expectations and assumptions about the consumed data product in some place and expect the output ports meeting them. On the second slide you can see an example with the test classes stored in folders associated with each output port.
DataOps in action with Nessie, Iceberg and Great Expectations by Antonio Murgia
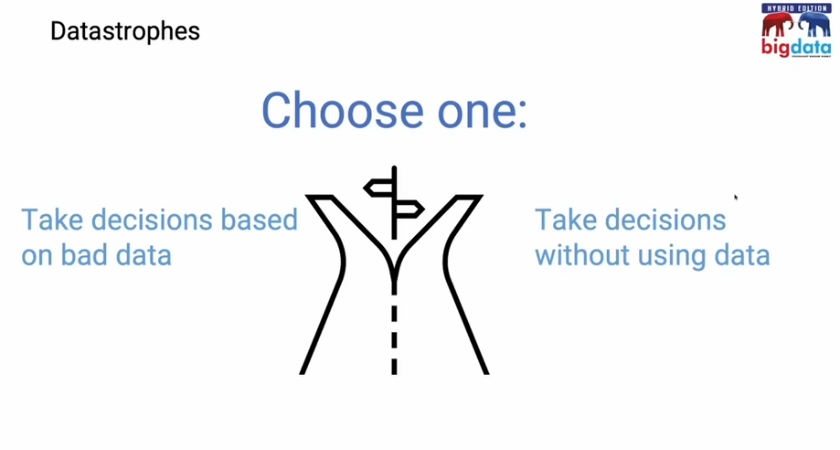
In his presentation Antonio Murgia demonstrated how to leverage Git for data tools, in this case Nessie, to avoid datastrophes:
To avoid that issue, Antonio introduced a Write-Audit-Publish Pattern. The idea is to avoid deploying the data that doesn't meet the requirements. It turns out to be quite challenging to do implement on top of the object stores because of the following issues:

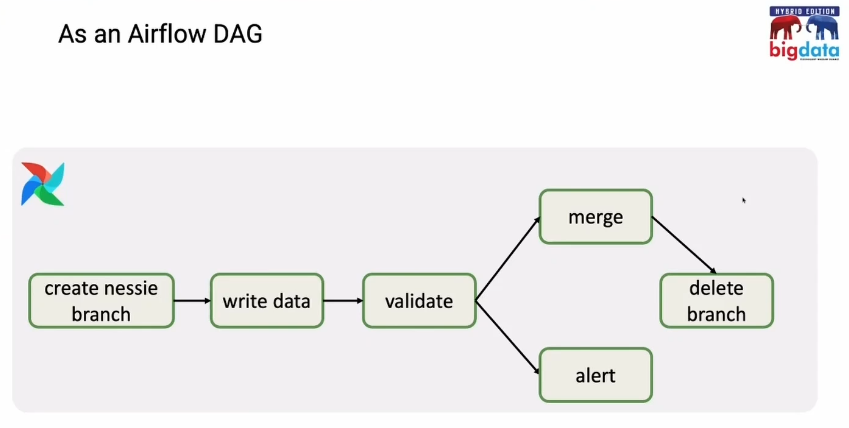
However, thanks to the Git-for-data-lake tools like Nessie, the pattern can work a bit better. Below is an implementation of the Apache Airflow DAG shared by Antonio:
In the end Antonio also mentioned an Apache Iceberg implementation of the pattern prepared by Samuel Redai.
Terraforming hardened Azure Databricks environments
In the last talk of my DataOps section, Filip Rzyszkiewicz shared some lessons learned for securing a Databricks setup on Azure:
- Networking. By default the traffic is going through public IPs, including the communication between the control and workers, and users and workspace. This setup is not very secure and a more secure alternative using private IPs exists.
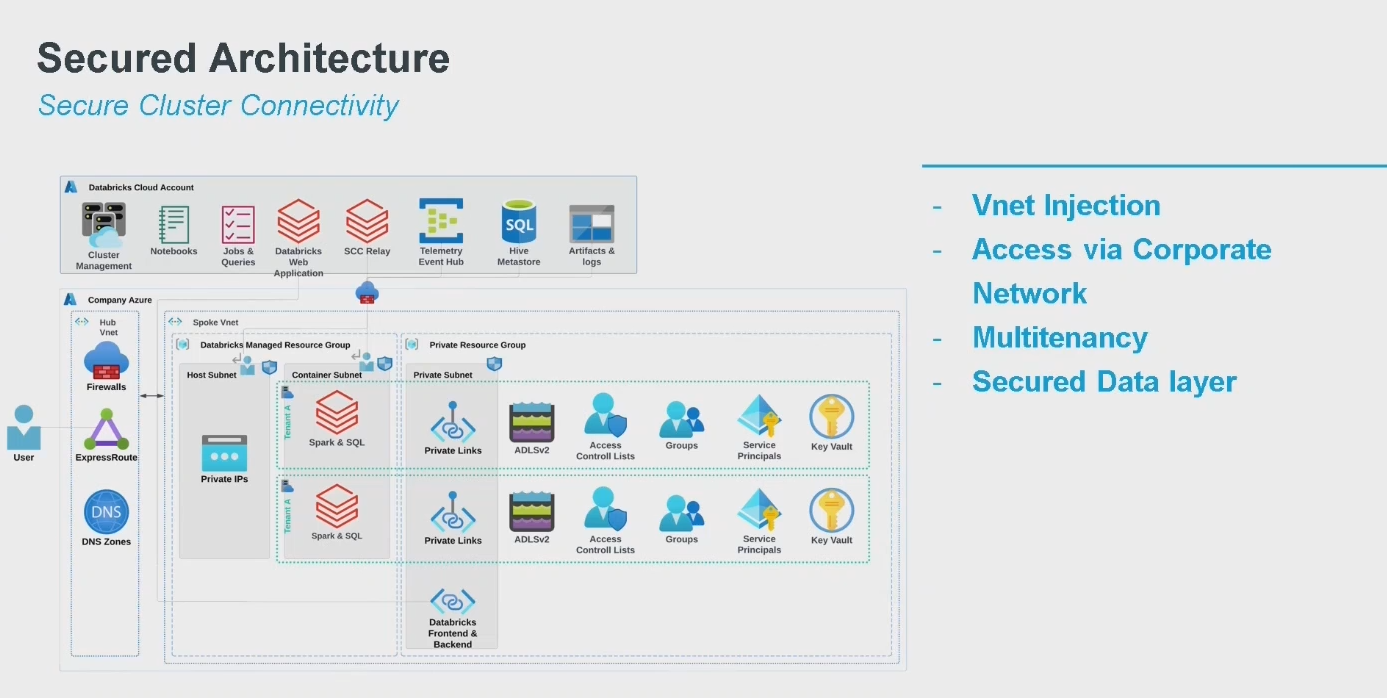 Exceptions on the firewall rule will be probably needed to reach other Azure services required to run your Databricks instances.
Exceptions on the firewall rule will be probably needed to reach other Azure services required to run your Databricks instances.
- Metastore. By default it's deployed on a control plane and requires an extra exception on the firewall rules to reach it. Databricks helps fine tune this part with IP filtering but you can also use an alternative metastore, such as an Azure Database to reduce the number of public IPs.
- Active Directory integration. If you are not using Unity Catalog and would like to integrate Databricks with Azure AD, it happens through public IPs. Even with the security cluster connectivity enabled, you still expose the Databricks workspace from public IPs and should reduce the accessibility to the Azure Active Directory service tag.
- Cluster policies to define clear boundaries between users. The goal is not to slow down the users with restrictive global rules. Instead, the cluster policies give some flexibility and possibility to configure the instances for individual users.
Even though I couldn't watch all the sessions in real-time, I'm quite happy to have this online access and take some notes after-the-fact. Hopefully you enjoyed them too and who knows, maybe see you some day at a conference or meetup?
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- On tests in data systems
- Alerts, guards, and data engineering
- Agnostic data alerts with ydata-profiling
Last month I gave my first talk after a 3-years break at Big Data Technology Warsaw Summit. Besides, I also wrote a follow-up blog post with summaries of other presentations (lot of streaming, data lineage) ? https://t.co/dQqHbuZMjF
— Bartosz Konieczny (@waitingforcode) April 21, 2023