
Modern data space is an exciting place with a lot of innovation these last years. The single drawback of that movement are all the new buzz words and the time required to understand and classify them into something we could use in the organization or not. Recently I see more and more "data contracts" in social media. It's also a new term and I'd like to see if and how it revolutionizes the data space.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
At first glance, a data contract was for me a modern world for Schema Registry made popular with Apache Kafka. The registry has schema compatibility and versioning. It also guarantees less risk for failures by controlling the changes the producers can make.
After the first lecture of several blog posts, my understanding changed to "it looks like a Data Catalog put in front of the development lifecycle". Although it looks natural to define the dataset in the first step of any new data source, I've observed that very often this happens at the end of the cycle, or at best simultaneously while writing the data processing code. Still cool stuff being said!
But there is more and I could understand it after reading the blog posts again!
Data contracts takeaways
Data stability. The contract is a public versioned agreement on what the consumers may expect from the data. Data contracts are often compared to the API contracts from the software engineering and here when you agree on something (payload schema, response format, ...), it can change but if you don't follow the update just after, you should still be able to use your API version.
Metadata management. The aforementioned stability comes from the metadata available to the consumers. They know the schema of the data which is a quite standard information, but also some extras, such as dataset refresh periods, privacy configuration, or even the data quality metrics.
Data contracts != data catalogs. In my understanding, data contracts specify what the data catalog should contain regarding the dataset. They're more like templates people agree on in Pull Requests rather than the artifact exposed to the end users. And besides populating an entry in the data catalog, data contracts could also create corresponding resources!
Data contracts != schema registry. As before, a schema registry is more a side-effect of the data contract process. It's the place where you will store the result of the agreement between the producers and consumers, the missing piece in the beginning of the schema specification process.
Visibility. Data contracts look like a way to popularize the data culture in an organization. Where previously you would have a meeting with a bunch of people initially concerned by your dataset, with data contracts the knowledge is open to everyone. The contracts are managed as a code and naturally bring traceability, reproducibility, and operationalization.
You can see it already, the place of data contracts in my vision of datasets is in the beginning of each new data product, as in the schema below:
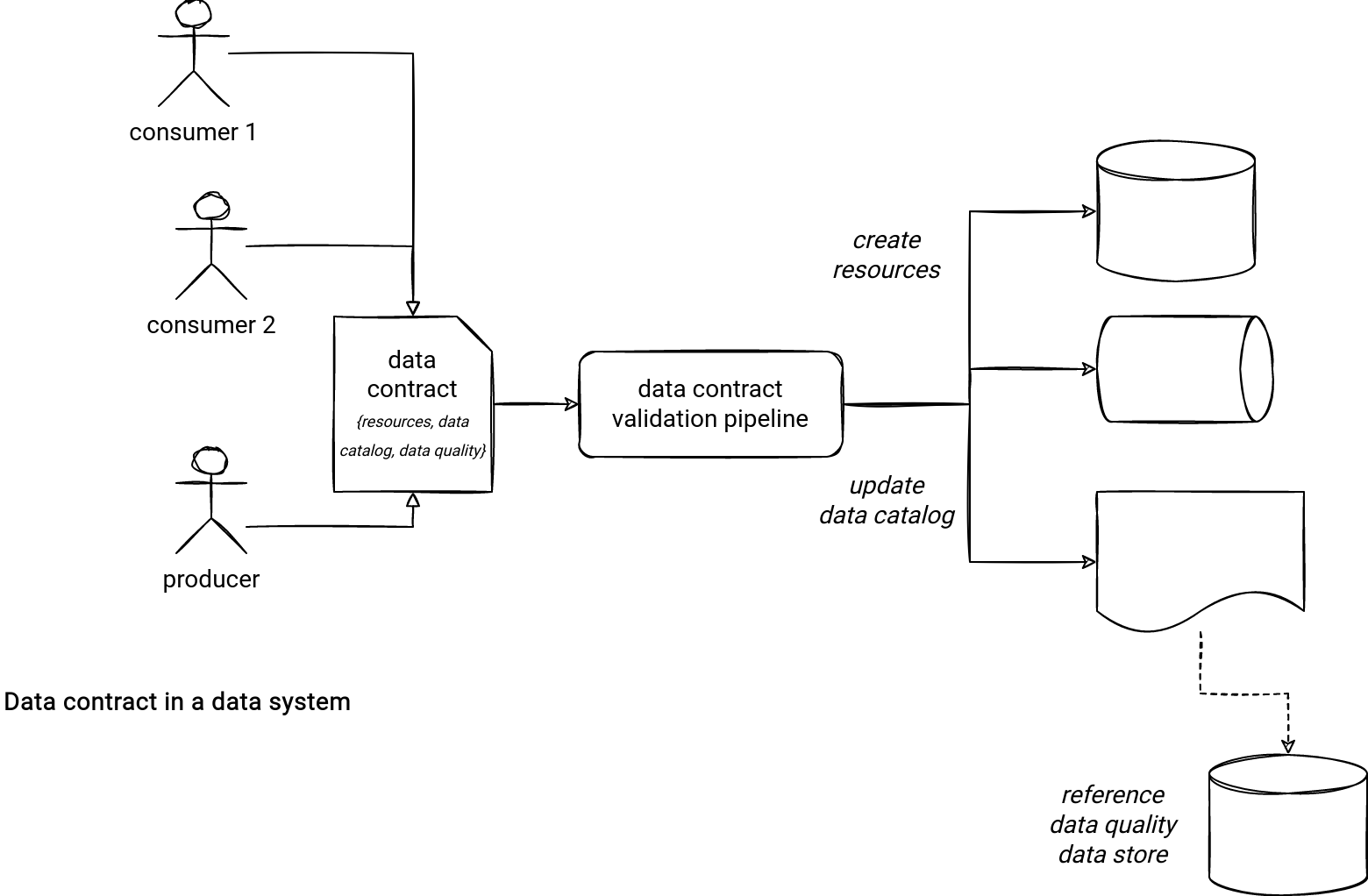
I'm reasoning here in terms of static contracts that are signed by consumers and producers before the first release and before each of the subsequent releases of a given dataset. In the data mesh era and consideration of datasets as data products, it was the first picture in my head. If you see anything else, I'd be glad to learn and enrich the article with your comments!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Data contracts here:
- Data Contracts: The Mesh Glue Data Contracts - ensure robustness in your data mesh architecture 7 Lessons From GoCardless’ Implementation of Data Contracts Is The Modern Data Warehouse Broken? schemata
Related blog posts:
- On tests in data systems
- Alerts, guards, and data engineering
- Agnostic data alerts with ydata-profiling
Data contracts are one of the hot topics of the moment. Since the term was a bit confusing, recently I've spent some time reading its different explanations. The result of my work is the new, quite short but hopefully concise enough, blog post ? https://t.co/IpRLhPO1VZ
— Bartosz Konieczny (@waitingforcode) November 20, 2022