
More and more often in my daily contact with the data world I hear this word "modern". And I couldn't get it. I was doing cloud data engineering with Apache Spark/Apache Beam, so it wasn't modern at all? No idea while I'm writing this introduction. But I hope to know more about this term by the end of the article!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Definition
That was my first concern. How to define this modern data stack? Some of the already written articles linked in the "Read more" section under the article helped me get the keywords describing this modernization of our world:
- Traditional Data Stack. Probably the best way to understand any new concept is to get what problems it solves. It turns out that the Modern Data Stack addresses well-known issues of the Traditional Data Stack, such as the lack of flexibility and hard adaptation to the changes. It targets the on-premise architectures and classical storage-compute coupled data warehouses. Modern Data Stack brings then more flexibility and simplicity.
- Data governance. This topic was often neglected for horizontal data processing benefits. I'm not saying it didn't exist in the on-premise Hadoop era, but the data processing concern was more important. Well, it still is important but because of its simplification with managed cloud services and flexible resource management, the data teams can put now some effort into making the data discoverable and secure. Modern Data Stack considers the data governance aspect as an intrinsic part of any data system.
- Everything as a Code. An important lever of the flexibility is the code-first character. In a Modern Data Stack, you track everything in your Version Control System, even the infrastructure or your SQL queries!
- ELT. One of big drawbacks of the ELT in the Traditional Data Stack was the coupling between the storage and compute layer in the data warehouse. Since the Modern Data Stack favors flexible solutions such as BigQuery or Snowflake in that layer, a part of the ETL pipelines can migrate towards ELT approach.
- Data operationalization. The data doesn't need to live inside your internal data system. Except for any legal rules, it can integrate into the existing specialized marketing, financial, or advertising tools to help your business teams make better data-driven decisions. Modern Data Stack is not only about ELT shift but also Reverse ETL.
- Data Mesh. Although it's not a pure Modern Data Stack attribute, I found it quoted in many places. Assuming that the Data Mesh considers data a product and favors better data usage within the organization. Modern Data Stack, thanks to this lower architecture entry cost, makes the data as a product in a domain-oriented architecture.
- Data engineering out-of-the-box. The simplicity is often brought not only by the cloud flexibility but also by the tools that require more configuration than coding. For example, a data ingestion passthrough job only requires defining the data source, the data destination, and the synchronization schedule. Modern Data Stack reduces engineering effort and makes the data available since the day 1 in the beginning data teams.
- Not only for analytics. Many articles mention data analytics as the main finality of the Modern Data Stack. They also quote many data analytics-oriented tools (dbt, Snowflake, BigQuery, Redshift, Synapse, ...), which strengthens that idea. However, the solution is not only for analytics! Sure, it brings the data closer to the business members but also provides several Machine Learning components, such as feature store or augmented analytics.
- Data quality. Another concept promoted to the top level of the data systems is data quality. Discoverable data processed in time may not be enough to meet the demand of your users, who must trust your data before using it. There is nothing better to trust the data than to control it and be proactive in case of any issues. Modern Data Stack assigns big importance to the data quality from day 1.
Without quoting any technology, an implementation of the Modern Data Stack could look like that:
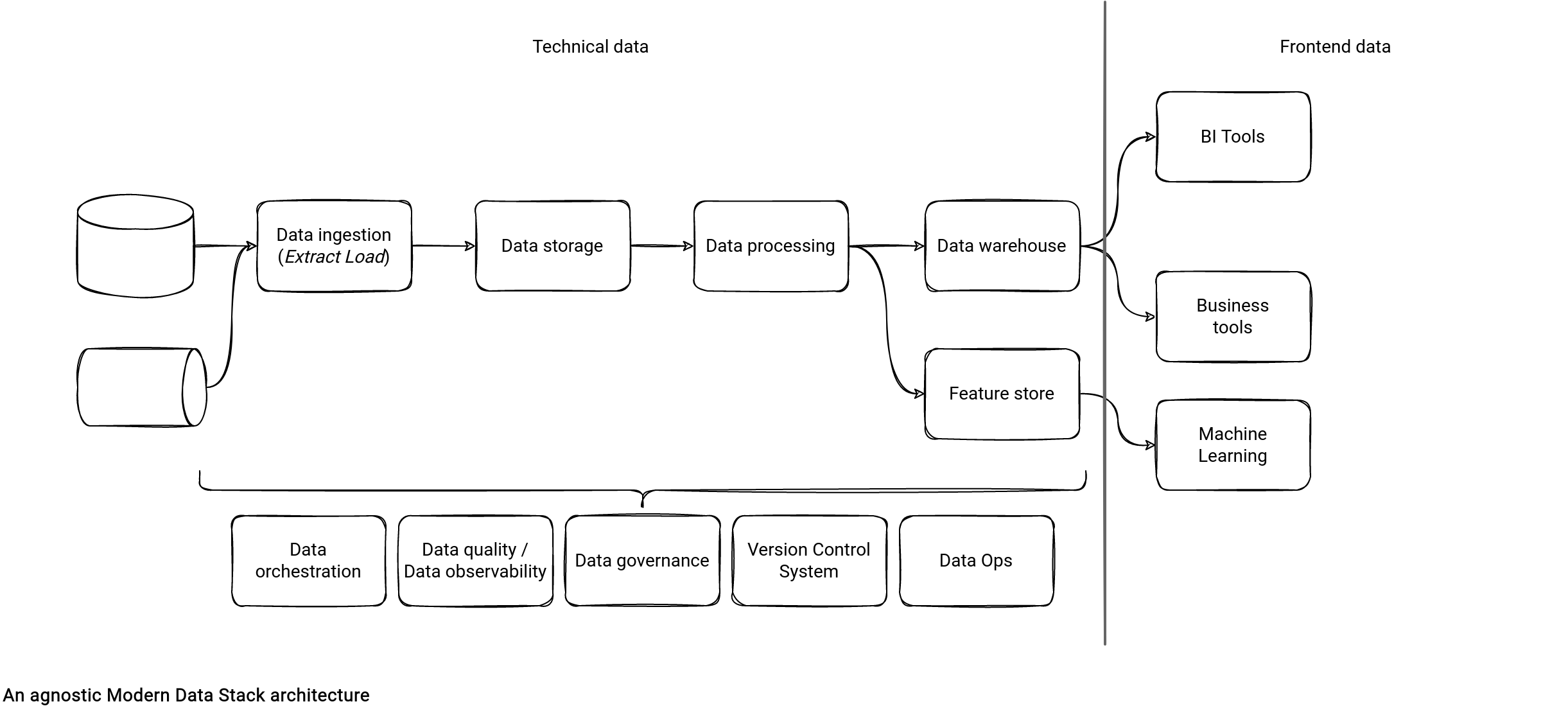
"My" architecture can differ from the others you can find in other blog posts. I didn't put the data warehouse as a single central data repository because it can make sense using a data lake or a lakehouse (data type constraint, data processing strategy, ...). For sure, it's only my vision and you could freely replace the "Data storage" layer by "Data warehouse" to limit its transformation scope to the ELT paradigm. But I decided not to do that and preferred to keep the implementation open.
Am I too old?
Oh, yes, I am! This year I'm going to turn 35 👴 I do my best to keep myself up-to-date with the tech news and work with up-to-date technologies and smarter people than me. Sure, I'm missing something, like ACID file formats I'm trying to catch on this year, but I didn't feel old reading the promise of a Modern Data Stack.
Do not get this wrong because it brings new tools to easily manage the obscure data system parts, such as observability, quality, and governance. But I've a feeling that the main principle relies on easily scalable, pay-as-you-go, preferably managed, resources. And the cloud has provided them for a while already. Maybe the Modern Data Stack is a term to clearly separate the pre- and post-cloud evolution era?
Even for the core architecture, the MDS remains based on the classical idea of moving the data from one point to another with the goal to make it usable by end-users. Indeed, it identifies some tasks with new terms, such as the Reverse ETL or Customer Data Platform, but they are not new. I bet you've already pushed the data to a 3rd party system via an API or have created a user profile table in your data system. The single difference I can see is that you'll find them identified as a service offerings. So you can just use it and delegate the maintenance part to other companies.
This leads me to another point, the marketing. The MDS also impacts this field. After reading dozens of blog posts to discover the topic, I had a feeling that only the ELT-based systems are modern. In theory, there is nothing wrong with this data store-based transformations logic. But we should remain pragmatic and not consider it as a model or condition for being "modern". It's impossible to implement everything with SQL, UDFs, or store all kinds of data in the data warehouse.
But this marketing part also has some positive impact. It promotes data observability, quality, and governance, as the top-level components of a viable data system. Again, you've certainly implemented them in the previous projects, but their implementation was maybe less important than writing a new ETL/ELT pipeline. This time it should be different as they will be implemented as a part of this pipeline, not something aside. And this reminds me of the battle of adding unit tests to the software projects. In the beginning, some people considered them an addition that can be done after delivering the feature, maybe in 1 or 2 sprints (sometimes it might not happen at all if the task was of a low priority). Today, it's one of the non-breakable rules to pass the code from dev to production environment. Hopefully, the same will happen with the observability, quality, and governance!
Although this second section sounds less enthusiastic, do not take it as a criticism. Modern Data Stack brings some difficult parts of a data architecture to the light and proposes as-a-service solutions for them. It also marks a clear distinction between the era of the on-premise and cloud data systems. Maybe it lacks a more important Machine Learning focus, or it's too into ELT, but it's only the outcome of my interpretation. I'll be happy to read your thoughts on this topic in the comments under the article!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Modern data stack. Am I too old? here:
- What's So Modern About the Modern Data Stack? What defines the modern data stack and why you should care The Modern Data Stack (updated for 2021) Will the Real "Modern Data Stack" Please Stand Up? What Is The Modern Data Stack And Why You Need to Migrate to the It Categories
Related blog posts:
- On tests in data systems
- Alerts, guards, and data engineering
- Agnostic data alerts with ydata-profiling
The second blog post planned for the previous weekend is about the modern data stack. I'm trying to understand the concept and its differences with the cloud revolution better. If you have any input, feel free to share in the comments under the article ? https://t.co/SNVbtktEv0
— Bartosz Konieczny (@waitingforcode) June 27, 2022