
PySpark has been getting interesting improvements making it more Python and user-friendly in each release. However, it's not the single Python-based framework for distributed data processing and people talk more and more often about the alternatives like Dask or Ray. Since both are completely new for me, I'm going to use this blog post to shed some light on them, and why not plan a deeper exploration next year?
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
I'm analyzing Dask and Ray from a data engineering perspective, mainly focusing on the processing part. I'm not a data scientist but am going to do my best in trying to understand the pain points these 2 frameworks help solve in this domain. That being said, the analysis covers high-level aspects only I could understand from the documentation.
Dask in a nutshell
The best definition of Dask I've found so far comes from the Is Dask mature? Why should we trust it? question in the Dask FAQ. Let me quote it before exploring other aspects:
Yes. While Dask itself is relatively new (it began in 2015) it is built by the NumPy, Pandas, Jupyter, Scikit-Learn developer community, which is well trusted.Dask is a relatively thin wrapper on top of these libraries and, as a result, the project can be relatively small and simple. It doesn’t reinvent a whole new system.
At first it sounds familiar to the Apache Beam project which is also a wrapper on top of other data processing frameworks and services (Apache Spark, Dataflow, Apache Flink, ...). But after a deeper analysis, there are some important points that don't reduce Dask into a simple API-based project:
- A scheduler. Dask has its own low-level Python scheduler that is a glue between initial local computing and modern distributed processing on top of commodity hardware clusters.
- A flexible scheduling model. It took some time to understand but fortunately I found a schema made by Matthew Rocklin showing pretty clearly the difference between a stage-based Map/Reduce model and a more unpredictable execution graph you might have in ML workloads:
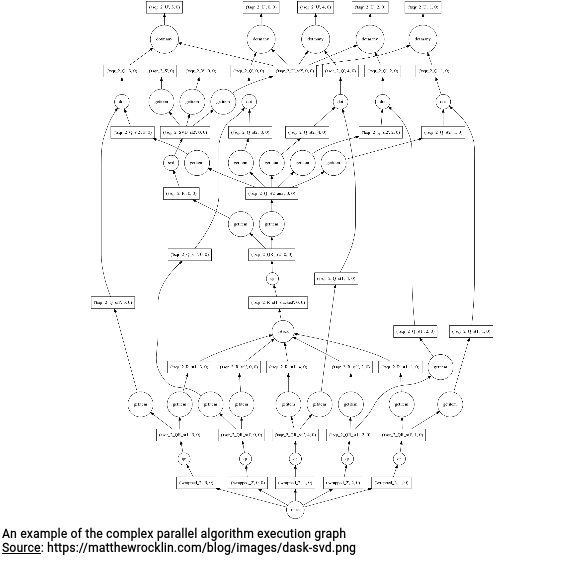
I can't imagine how a Map/Reduce model could schedule such a pipeline whereas it looks relatively easy in Dask - not the pipeline, the code you have to write! - Python ecosystem integration. Since Dask defines itself as a thin wrapper on top of other Python libraries, it naturally has a good integration with the major ones, such as Pandas, NumPy, or Scikit-Learn.
- Collections. This ecosystem integration adds some complexity, though. There are multiple representations of the input data. If you want to leverage the power of NumPy, you'll create Arrays. If on the other hand, you want to keep your Pandas-based way of working, you'll need to initialize DataFrame. As a data engineer, I found it pretty disturbing albeit reasonable, since you might need a different abstraction to solve a different problem.
- Caching and fault-tolerance. They are some concepts you might find familiar from the JVM-based data processing frameworks. The fault-tolerance relies on the idea of replayable execution graphs where a failed node can be reproduced in case of a failure.
Before I pass to Ray, I must share one sentence that caught my attention in the Dask marketing space:
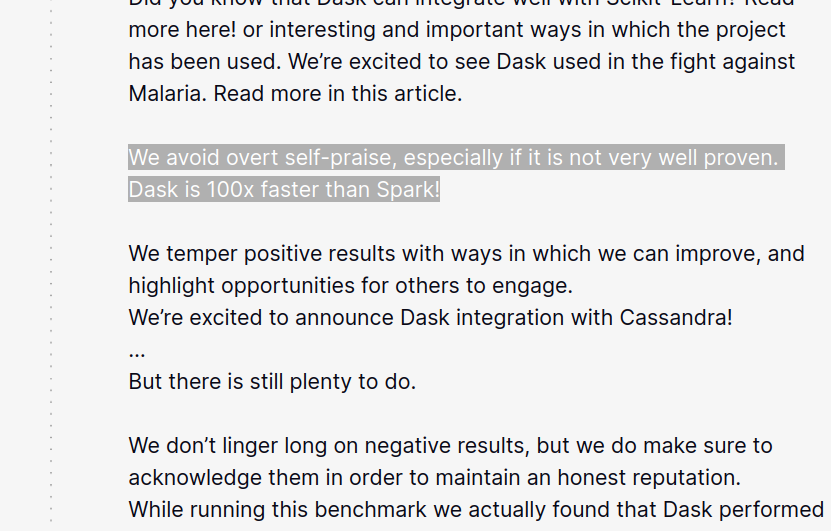
And that's totally the feeling I had while reading the documentation. If you check out the section comparing Dask and Spark, you will see there is nothing like "we're the best". It's a very pragmatic vision of two tools that will outperform in 2 different domains (ML workloads vs. data engineering workloads).
Ray in a nutshell
Ray has a lot of similarities with Dask, including:
- An unified API. Ray also comes with a single API that applies to the whole lifecycle of a ML project, from the data preparation to the data serving stage.
- A scheduler for the complex algorithms. Ray also addresses the Map/Reduce models limitations and comes with its own scheduler adapted to the complex algorithms as the one you saw in the previous section.
- An actor model. Ray uses the actor model in the stateful pipelines. The framework fully manages the synchronization so that you don't need to manage the actors location in the code.
- A Global Control State storage. It's a distributed data store built on top of Apache Arrow managing the shared functions, objects and tasks used by the cluster.
- C++ for performance. Ray has 2 types of workers. The first using Python API is high-level and user-facing whereas the second one called CoreWorker is low-level and mainly responsible for the internal execution. The CoreWorker manages the gRPC communication and is implemented in C++ to provide high performance for any API using it. There is a schema from Ray 1.x Architecture explaining this dependency:
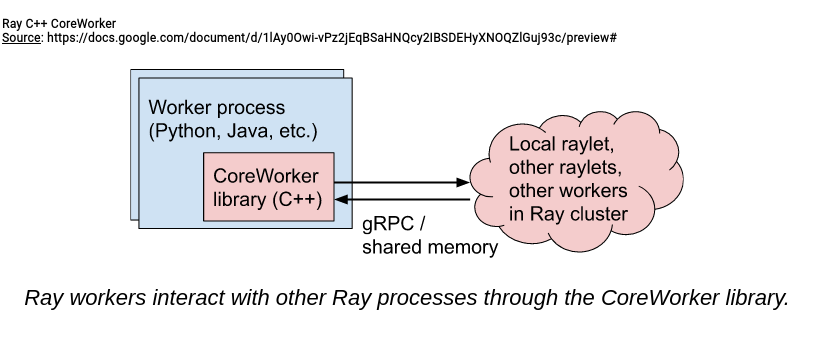
- Bazel. This C++ module inside a Python project is probably one of the reasons for using Bazel as the build tool.
And PySpark?
PySpark has been improving a lot in the last releases to better fit into this Python data landscape. There is an ongoing Project Zen initiative to make PySpark more Pythonic with the support for Pandas DataFrames, easier onboarding, or type hints.
Despite this ongoing effort, I can now better understand the difference between PySpark, Dask, and Ray. While I would start with PySpark for any pure data processing workload, I would think about using Dask or Ray for a more data science-specific use case. Again, I'm not a data science expert but my feeling is that there are some use cases where a PySpark implementation will be way more complex (if not, impossible to write!) than a Dask's or Ray's one. That being said, it's not necessarily PySpark but more the Map/Reduce model that seems to be less adapted to the complex ML algorithms.
Dask and Ray communities do a great job on comparing things. Comparison to Spark explains the differences between Dask and Apache Spark. There is also a great Github issue focusing on the Dask and Ray. So if you're still hungry after reading this short blog post, these links are a great way to discover more!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Python alternatives to PySpark here:
Related blog posts:
- On tests in data systems
- Alerts, guards, and data engineering
- Agnostic data alerts with ydata-profiling
Is PySpark the single Python framework for data processing? No. There are 2 others that I covered in the new blog post. To read about Dask and Ray in nutshell, it's that way ? https://t.co/cPd3aX2n7t
— Bartosz Konieczny (@waitingforcode) November 6, 2022