
And it shouldn't be, right? After all, it's "just" about using a Unit Test framework and defining the test cases. Well, that's "just" a theory!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Unit Tests are the first layer of protection against code regressions. However, they're very hard to create and maintain through the project lifecycle. Why? This blog post is here to show some difficult points you might face one day.
Dataset - definition
Jacqueline Bilston summarized the problem greatly in her talk at the previous Data+AI Summit. It's better to have small-scoped tests than big ones covering different scenarios and features. Not only they spot issues earlier but also are easier to maintain. Unfortunately, there are still some issues with this crucial point of Unit Tests.
The first one is how to generate the datasets? The most naïve strategy is to simply extract the data from the system, reduce the volume, and put it as files under the resources directory. Although it works great to bootstrap the project, it can be difficult to manage in the long term because of the following issues:
- Understanding. Knowing what attribute is specifically responsible for a given behavior is hard with files. The files live outside the test scope, so every time they require an open-analyze action.
- Maintenance #1. What if one attribute changes the type and you must update the test cases accordingly? Opening and editing x test files can be very painful.
- Maintenance #2. Another difficult maintenance point is the test association. Even if you create one test file per unit test method, how to identify which ones are used when? Oftentimes you might encounter one big test file that is common for all test methods and therefore, difficult to maintain with any changes.
There is no magic solution but IMO, a better approach than having a lot of JSON, CSV, or binary input files in the tests package, is to generate them from the code with the help of a DSL or the prototype design pattern. The thinking behind the approach is the Pareto rule. Most of the time 80% of the input dataset attributes will remain unchanged and only 20% will have an immediate impact on the tested function. There is no reason to repeat the logic or declare all the attributes every time explicitly. They can be simply pre-filled. Moreover, code like that is easier to evolve. You need to change an attribute or add a new one? No problem, if you do it wrong, the compiler will warn you about an issue! Of course, you can still miss something but at least any evolution is supported not only by you, your colleagues reviewing the PR, but also by the compiler and the IDE! You can find an example of the Prototype pattern used in tests definition below:
class Order:
def __init__(self, id: int = randint(0, 100000), amount: float = 33.33,
user: str = f"user{int(time.time())}", coupon: Optional[str] = None) -> None:
self.id = id
self.amount = amount
self.user = user
self.coupon = coupon
The idea of DSL is even funnier to code! It lets you explore all the syntactic sugar available in each programming language but the topic is way more complex than the Prototype pattern and I prefer to cover it in another blog post.
Dataset - consistency
The consistency is even harder than the previous point. How to ensure that the data you put in your tests corresponds to reality? There is no other choice here than asking the real world data and adding specific interfaces to the test data generators.
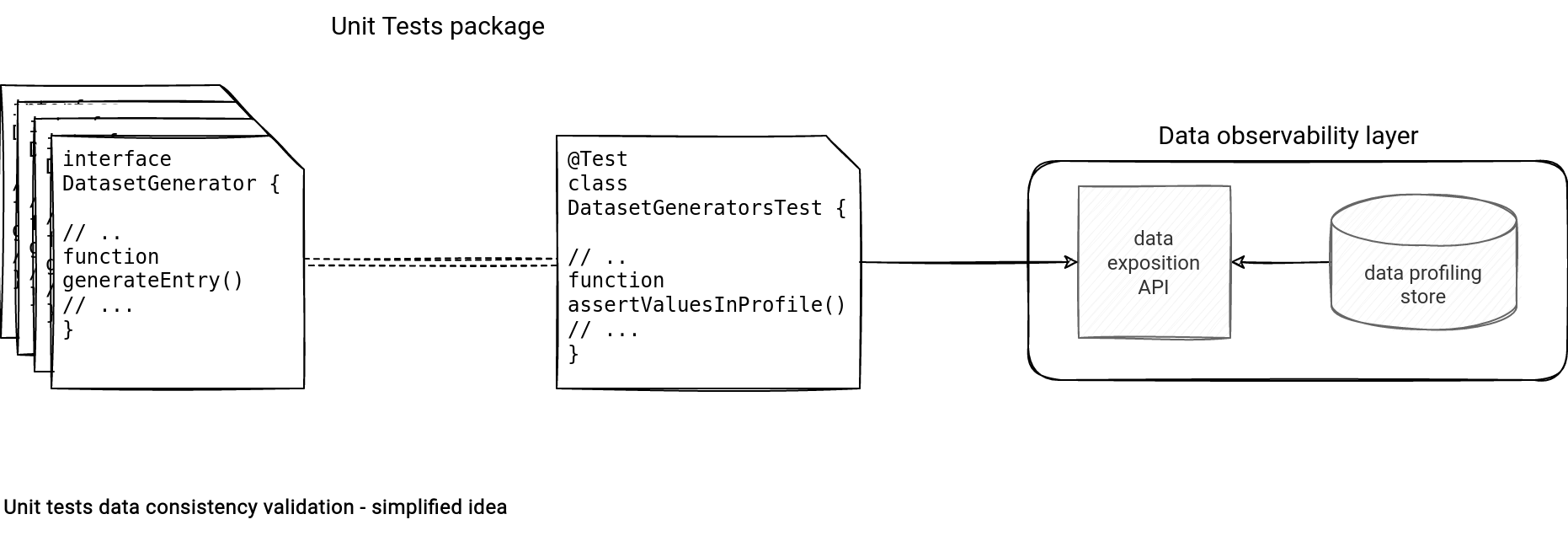
To understand the idea better, let's analyze the 2 main components of the design:
- Data observability layer. It's the place that exposes dataset profiles from an API. The profile data is written to a data store either as a side output of the real world pipelines, or as a result of scheduled data profiling job execution.
- DatasetGenerator interface. The idea of having an interface is to scan all the created entities during the profile validation stage in the assertValuesInProfile() test that will call the data observability endpoint to validate the tested values against the data distribution profiles.
You can find a simple implementation of that idea just below:
In my example I'm using Pytest fixture from a conftest.py file that is executed after all unit tests. I'm of course mocking the data profiling validation method but it's there to show the validation idea only:
def validate_item_against_data_profiling_endpoint(item) -> bool:
return False
@pytest.fixture(scope="session", autouse=True)
def my_session_finish(request):
def _end():
items_to_validate = DataGeneratorWrapper().get_items()
has_error = False
print(f'items_to_validate={items_to_validate}')
for item_to_validate in items_to_validate:
if not validate_item_against_data_profiling_endpoint(item_to_validate):
print(f'Error while validating {item_to_validate}')
has_error = True
if has_error:
raise Exception("Test are inconsistent with the data profile")
request.addfinalizer(_end)
The data is manually put by the error creation method whenever a new item to validate is created:
class Singleton(type):
_instances = {}
def __call__(cls, *args, **kwargs):
if cls not in cls._instances:
cls._instances[cls] = super(Singleton, cls).__call__(*args, **kwargs)
return cls._instances[cls]
class DataGeneratorWrapper(metaclass=Singleton):
def __init__(self):
self.container = []
def add_item(self, item: Any):
print(f'adding {item}')
self.container.append(item)
print(self.container)
def get_items(self):
return self.container
class OrderDataGenerator:
@staticmethod
def generate_order(id: int, amount: float = 100.55, user: str = "user 1", coupon=None) -> Order:
generated_order = Order(
id=id, amount=amount, user=user, coupon=coupon
)
DataGeneratorWrapper().add_item(generated_order)
return generated_order
def test_if_id_is_negative():
order = OrderDataGenerator.generate_order(id=-1)
assert order.id == -1, "Negative id should be allowed"
def test_if_id_is_positive():
order = OrderDataGenerator.generate_order(id=1)
assert order.id == 1, "Positive id should be allowed"
Dataset - schema
The third difficulty in writing unit tests for dynamically evolving datasets is the schema management. More exactly, it's the question on how to ensure that the schema of the input data is still accurate? Similarly to the dataset consistency, we can also rely here on an external component called Schema Registry. Although a lot of you associate it with Apache Kafka and Apache Avro, the solution works for other stacks as well, a little less evolved though. How?
Let me first give you an overly simplified Schema Registry definition. To put it short, it's a queryable place where you store the schema definitions and eventually, can define the schema evolution enforcement rules (it's a very demanded nice-to-have requirement). So it's an Apache Kafka Schema Registry component but also a...Git repo where you can consider a new schema at each released tag.
The schema check can be implemented at any place, in the CI pipeline, as a pre-commit Git hook, or as a unit test. In my example I'm cloning data-generator repository and comparing the latest tag with the schema tag supported by the application:
# It imitates a config directory
SCHEMA_VERSION = "v0.1.0"
from git import Repo
from schema.schema_holder import SCHEMA_VERSION
def test_if_schema_tag_is_the_same_as_on_production():
schema_repostiroy_repo = Repo.clone_from("https://github.com/bartosz25/data-generator.git", "/tmp/repo")
tags = sorted(schema_repostiroy_repo.tags, key=lambda t: t.commit.committed_datetime)
latest_tag = tags[-1]
assert str(latest_tag) == SCHEMA_VERSION, "a new schema was released, please update the application code"
In this blog post I shared with you the fears I have each time I write the Unit Tests. Indeed, defining them helps make the code better, more reliable, and easier to maintain, but if the tests don't reflect reality, their protection against unexpected issues will be weaker.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- On tests in data systems
- Alerts, guards, and data engineering
- Agnostic data alerts with ydata-profiling
Unit tests are the foundation of the test pyramid. They're relatively easy to define due to the lack of dependencies. However, the maintenance might be challenging. Especially in a dynamically changing data context ? https://t.co/cTxfeod50d
— Bartosz Konieczny (@waitingforcode) October 9, 2022