
Previously we discovered what happens when you coalesce a dataset. To recall, it doesn't involve shuffle operation. It's then the opposite of a repartition operation which is a first class shuffle citizen.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
A reminder from the previous blog post about coalesce internals in Apache Spark SQL. Repartition and coalesce operations add a Repartition logical node to the plan with one subtle difference in the shuffle flag. In coalesce it's set to false whereas in repartition to true. Depending on the flag, the physical planner either generates a ShuffleExchangeExec or a CoalesceExec. In this blog post we'll focus on the former one, added in the repartition operation.
repartition() to ShuffleExchangeExec
If you check the ShuffleExchangeExec definition, you will see that it has an attribute called shuffleOrigin . It can take one of 3 values: ENSURE_REQUIREMENTS , REPARTITION or REPARTITION_WITH_NUM . In the case of repartition() operation, it's set to REPARTITION_WITH_NUM, meaning that the number of partitions changed because of the user explicit configuration:
object BasicOperators extends Strategy {
def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
// ...
case logical.Repartition(numPartitions, shuffle, child) =>
if (shuffle) {
ShuffleExchangeExec(RoundRobinPartitioning(numPartitions),
planLater(child), REPARTITION_WITH_NUM) :: Nil
} else {
execution.CoalesceExec(numPartitions, planLater(child)) :: Nil
}
// ...
case class ShuffleExchangeExec(
override val outputPartitioning: Partitioning,
child: SparkPlan,
shuffleOrigin: ShuffleOrigin = ENSURE_REQUIREMENTS)
extends ShuffleExchangeLike
To generate shuffle files, Apache Spark uses the last "mapper" task in the DAG before the shuffle stage. The generation relies on another component of ShuffleExchangeExec called shuffleDependency defining the shuffle partitioner and the mapper's RDD:
case class ShuffleExchangeExec
// ...
@transient
lazy val shuffleDependency : ShuffleDependency[Int, InternalRow, InternalRow] = {
ShuffleExchangeExec.prepareShuffleDependency(
inputRDD,
child.output,
outputPartitioning,
serializer,
writeMetrics)
}
@transient override lazy val mapOutputStatisticsFuture: Future[MapOutputStatistics] = {
if (inputRDD.getNumPartitions == 0) {
Future.successful(null)
} else {
sparkContext.submitMapStage(shuffleDependency)
}
}
All the magic behind repartitioning happens inside the method creating the ShuffleDependency. Let's see it in the next section!
Partitioners, determinism, etc.
At the beginning of the prepareShuffleDependency, Apache Spark defines the partitioner that it will use for assigning the input data to the shuffle partitions. In the case of repartition() operation, it will be a HashPartitioner, created from the repartition's partitioning logic which is the round-robin. The logic behind this partitioner is very common to a lot of distributed systems because it uses the modulo division to get the number of shuffle partition:
val part: Partitioner = newPartitioning match {
case RoundRobinPartitioning(numPartitions) => new HashPartitioner(numPartitions)
// …
class HashPartitioner(partitions: Int) extends Partitioner {
require(partitions >= 0, s"Number of partitions ($partitions) cannot be negative.")
def numPartitions: Int = partitions
def getPartition(key: Any): Int = key match {
case null => 0
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
However, the partitioner is not used yet because Apache Spark can add an extra sorting step before! Wait, but why, a sorting step in an apparently random repartition operation? Well, the repartition shouldn't be random. The issue was pointed out in the SPARK-23207. In a nutshell, the issue highlights the use case when an executor's failure could lead to completely inconsistent results with random shuffle operation.
To handle this issue, Apache Spark will add an extra local sorting step at the map's task level. But this extra step has an additional operational cost and if you prefer the performance over the consistency, you can disable it by setting the spark.sql.execution.sortBeforeRepartition configuration entry set to false:
def prepareShuffleDependency(...) {
// ...
val newRdd = if (isRoundRobin && SQLConf.get.sortBeforeRepartition) {
rdd.mapPartitionsInternal { iter =>
// ...
val sorter = UnsafeExternalRowSorter.createWithRecordComparator(
StructType.fromAttributes(outputAttributes),
recordComparatorSupplier,
prefixComparator,
prefixComputer,
pageSize,
// We are comparing binary here, which does not support radix sort.
// See more details in SPARK-28699.
false)
sorter.sort(iter.asInstanceOf[Iterator[UnsafeRow]])
}
} else {
rdd
}
After this step, Apache Spark will define the shuffle data generation map task. Two different things can happen now. If the shuffle writer doesn't buffer the data in memory or the underlying objects are immutable, then Apache Spark will use a MutablePair to minimize object allocation. Otherwise, the map task iterator will return a basic Scala tuple. It's also the place where the defined partitioner will compute the shuffle partition number:
def prepareShuffleDependency(...) {
// ...
val rddWithPartitionIds: RDD[Product2[Int, InternalRow]] = {
val isOrderSensitive = isRoundRobin && !SQLConf.get.sortBeforeRepartition
if (needToCopyObjectsBeforeShuffle(part)) {
newRdd.mapPartitionsWithIndexInternal((_, iter) => {
val getPartitionKey = getPartitionKeyExtractor()
iter.map { row => (part.getPartition(getPartitionKey(row)), row.copy()) }
}, isOrderSensitive = isOrderSensitive)
} else {
newRdd.mapPartitionsWithIndexInternal((_, iter) => {
val getPartitionKey = getPartitionKeyExtractor()
val mutablePair = new MutablePair[Int, InternalRow]()
iter.map { row => mutablePair.update(part.getPartition(getPartitionKey(row)), row) }
}, isOrderSensitive = isOrderSensitive)
}
val dependency =
new ShuffleDependency[Int, InternalRow, InternalRow](
rddWithPartitionIds,
new PartitionIdPassthrough(part.numPartitions),
serializer,
shuffleWriterProcessor = createShuffleWriteProcessor(writeMetrics))
dependency
Just after that, the map task will write shuffle files so that the reducer can fetch them to continue the processing in the next stage. The whole operation is summarized in the following picture:
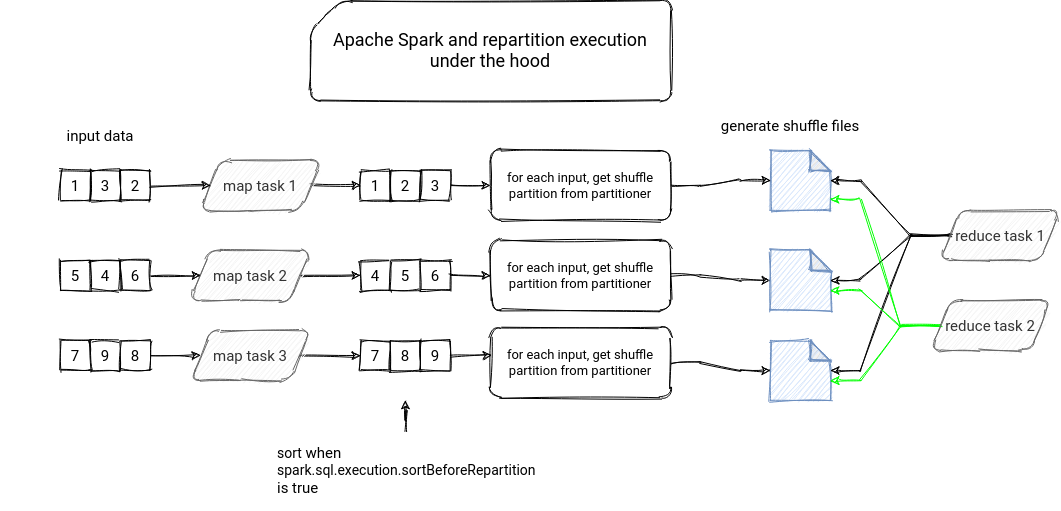
Repartitioning is then another operation you can use to redistribute the data in your processing. However, keep in mind that it involves shuffle, which, thanks to the HashPartitioner, should guarantee a pretty even data distribution.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Under-the-hood: repartition here:
Related blog posts:
Repartition is a shuffle operation but do you know it also sorts data locally? You will find this and a few other details in the new blog post ? https://t.co/9VPhl8v48t
— Bartosz Konieczny (@waitingforcode) May 29, 2021