
In the previous blog post we discovered the SortShuffleWriter. However, the SortShuffleManager's first choice is BypassMergeSortShuffleWriter, presented in this article.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This second blog of shuffle writers Spark shuffle writers series is organized as follows. It starts by presenting which conditions have to be met to use the BypassMergeSortShuffleWriter. Later, it shows 3 main steps of the writing process.
BypassMergeSortShuffleWriter - when?
The use of the BypassMergeSortShuffleWriter depends on the shuffle handle class called BypassMergeSortShuffleHandle, created when:
- shuffle operation doesn't involve the map-side aggregation - this conditions seems to hold only for the RDD API since the ShuffleExchangeExec creates the shuffle dependency with mapSideCombine attribute left to default (false). Only several of the PairRDDFunctions transformations sets this attribute to true and, hence, invalidates the use of BypassMergeSortShuffleWriter.
- and, the number of shuffle partitions is lower or equal to spark.shuffle.sort.bypassMergeThreshold - you will see that later but this writer opens separate serializers and streams for all shuffle partitions simultaneously and having them too much would negatively impact the performance. The default value for the threshold is equal to the default number of shuffle partitions (200).
Writing steps - setup
The algorithm generating shuffle files executes in 3 distinct steps within a single write method, though! The first of them is the setup where it creates an instance of the used ShuffleMapOutputWriter. Even though, it's usually used after processing all input records, BypassMergeSortShuffleWriter defines it at the beginning to skip the processing in case of an empty input:
final class BypassMergeSortShuffleWriter<K, V> extends ShuffleWriter<K, V> {
// ...
public void write(Iterator<Product2<K, V>> records) throws IOException {
assert (partitionWriters == null);
ShuffleMapOutputWriter mapOutputWriter = shuffleExecutorComponents
.createMapOutputWriter(shuffleId, mapId, numPartitions);
try {
if (!records.hasNext()) {
partitionLengths = mapOutputWriter.commitAllPartitions();
mapStatus = MapStatus$.MODULE$.apply(
blockManager.shuffleServerId(), partitionLengths, mapId);
return;
}
This optimization skips not only the processing but also the initialization of the partition writers and file segments. Those are the "simultaneous streams and files" mentioned in the previous section, created for every shuffle partition:
public void write(Iterator<Product2<K, V>> records) throws IOException {
assert (partitionWriters == null);
ShuffleMapOutputWriter mapOutputWriter = shuffleExecutorComponents
.createMapOutputWriter(shuffleId, mapId, numPartitions);
try {
if (!records.hasNext()) {
// ...
return;
}
partitionWriters = new DiskBlockObjectWriter[numPartitions];
partitionWriterSegments = new FileSegment[numPartitions];
for (int i = 0; i < numPartitions; i++) {
final Tuple2<TempShuffleBlockId, File> tempShuffleBlockIdPlusFile =
blockManager.diskBlockManager().createTempShuffleBlock();
final File file = tempShuffleBlockIdPlusFile._2();
final BlockId blockId = tempShuffleBlockIdPlusFile._1();
partitionWriters[i] =
blockManager.getDiskWriter(blockId, file, serInstance, fileBufferSize, writeMetrics);
}
Just before the writer's next step, you will find a comment highlight the fact of a potentially costly I/O. It also explains a bit better why Apache Spark uses this writer only for a relatively small number of shuffle partitions:
// Creating the file to write to and creating a disk writer both involve interacting with
// the disk, and can take a long time in aggregate when we open many files, so should be
// included in the shuffle write time.
writeMetrics.incWriteTime(System.nanoTime() - openStartTime);
Writing steps - iteration
In the next step, the BypassMergeSortShuffleWriter iterates over all input records and writes each of them to the corresponding shuffle file:
while (records.hasNext()) {
final Product2<K, V> record = records.next();
final K key = record._1();
partitionWriters[partitioner.getPartition(key)].write(key, record._2());
}
Upon completing this iteration, all remaining buffered records are flushed to the opened files:
for (int i = 0; i < numPartitions; i++) {
try (DiskBlockObjectWriter writer = partitionWriters[i]) {
partitionWriterSegments[i] = writer.commitAndGet();
}
}
Writing steps - commit
So far we've seen how Apache Spark distirubes the input records to the shuffle partitions files. However, its work doesn't stop here! In the final step, the writer concatenates all these files into a single file that will be exposed to the reducer tasks. Once again, it uses here a for loop iterating over all shuffle partitions. For each of them, the writer gets 2 elements, the shuffle-based file and the LocalDiskShufflePartitionWriter instance from the ShuffleMapOutputWriter; created at the beginning of the write operation:
@Override
public void write(Iterator<Product2<K, V>> records) throws IOException {
// ...
partitionLengths = writePartitionedData(mapOutputWriter);
private long[] writePartitionedData(ShuffleMapOutputWriter mapOutputWriter) throws IOException {
// ...
for (int i = 0; i < numPartitions; i++) {
final File file = partitionWriterSegments[i].file();
ShufflePartitionWriter writer = mapOutputWriter.getPartitionWriter(i);
After getting these 2 instances, the writer puts the content of each shuffle file to the combined final file. And it does it in 2 different ways, depending on the value of spark.file.transferTo property. If enabled - it's the default configuration - Apache Spark will use Java FileChannel's transferTo method to copy the content of the shuffle partitioned file. According to the Javadoc, it optimizes the operation by transferring the bytes directly from the filesystem cache:
* This method is potentially much more efficient than a simple loop
* that reads from this channel and writes to the target channel. Many
* operating systems can transfer bytes directly from the filesystem cache
* to the target channel without actually copying them.
If disabled, the writer will fallback to this behavior, where in represents the shuffle file and out the corresponding combined writer:
var count = 0L
val buf = new Array[Byte](8192)
var n = 0
while (n != -1) {
n = in.read(buf)
if (n != -1) {
out.write(buf, 0, n)
count += n
}
}
count
You noticed it, I spoke about "the combined writer" whereas in the for loop, Apache Spark initializes one ShufflePartitionWriter per shuffle partition. And actually that's correct. The ShufflePartitionWriter instances are created from ShuffleMapOutputWriter's getPartitionWriter method as LocalDiskShufflePartitionWriter:
@Override
public ShufflePartitionWriter getPartitionWriter(int reducePartitionId) throws IOException {
if (reducePartitionId <= lastPartitionId) {
throw new IllegalArgumentException("Partitions should be requested in increasing order.");
}
lastPartitionId = reducePartitionId;
if (outputTempFile == null) {
outputTempFile = Utils.tempFileWith(outputFile);
}
if (outputFileChannel != null) {
currChannelPosition = outputFileChannel.position();
} else {
currChannelPosition = 0L;
}
return new LocalDiskShufflePartitionWriter(reducePartitionId);
}
The LocalDiskShufflePartitionWriter initializes a per shuffle partitionPartitionWriterStream class. However, it doesn't create a separate output stream for every partition, it wouldn't make sense. Instead, it uses the output stream of the LocalDiskShuffleMapOutputWriter (ShuffleMapOutputWriter):
public class LocalDiskShuffleMapOutputWriter implements ShuffleMapOutputWriter {
// ...
private BufferedOutputStream outputBufferedFileStream;
// ...
private class PartitionWriterStream extends OutputStream {
// ...
@Override
public void write(int b) throws IOException {
verifyNotClosed();
outputBufferedFileStream.write(b);
count++;
}
@Override
public void write(byte[] buf, int pos, int length) throws IOException {
verifyNotClosed();
outputBufferedFileStream.write(buf, pos, length);
count += length;
}
// ...
}
Why then it has to be a different class? When the writer copies all bytes to the combined file, it calls the close method of the PartitionWriterStream which updates the statistics for this partition's size:
public class LocalDiskShuffleMapOutputWriter implements ShuffleMapOutputWriter {
private static final Logger log =
LoggerFactory.getLogger(LocalDiskShuffleMapOutputWriter.class);
private final long[] partitionLengths;
// ...
@Override
public void close() {
isClosed = true;
partitionLengths[partitionId] = count;
bytesWrittenToMergedFile += count;
}
And these statistics are very important because the BypassMergeSortShuffleWriter not only creates the combined file for all shuffle partitions generated in the given map task, but also creates a corresponding index file. This index file contains the offsets for every shuffle partition and thanks to it, the reducer can directly fetch the records it has to process.
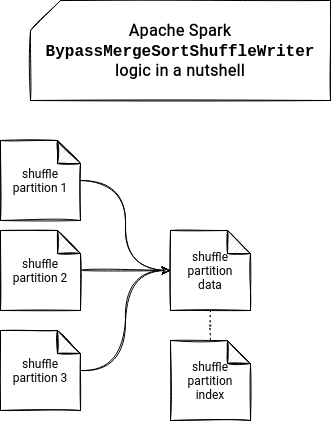
If you want to see this shuffle writer in action, you can watch the video below. Next time you will discover the last shuffle writer called UnsafeShuffleWriter.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Shuffle in PySpark
- Radix and Tim sort
- Shuffle configuration demystified - part 2
- Shuffle configuration demystified - part 1
- Shuffle reading in Apache Spark SQL - wrapping iterators and beyond
Shuffle writers in #ApacheSpark, part 2. Today it's time to discover BypassMergeSortShuffleWriter ? https://t.co/1OOMHkPZpI
— Bartosz Konieczny (@waitingforcode) June 12, 2021