
Last year I wrote a blog post about a batch layer in streaming-first architectures like Kappa. I presented there a few approaches to synchronize the streaming broker with an object or distributed file systems store, without introducing the duplicates. Some months ago I found another architectural design that I would like to share with you here.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
I inspired this proposal from Marina's answer to Avro Records -> Kafka -> Kafka Connect Sink -> Amazon S3 Storage. Idempotency? problem. The initial idea was to use an Apache Cassandra table to store events from another data store, grouped by event time, and gather these events at regular basics in batches. The following picture summarizes this idea:
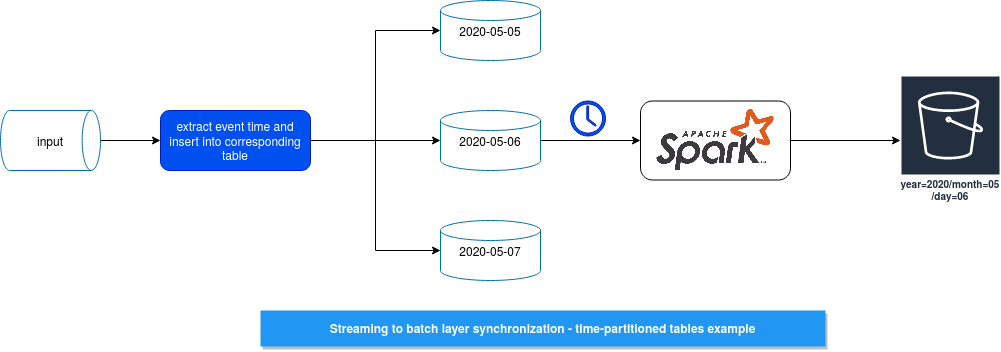
As you can see, we have a consumer that is continuously reading the input from a streaming source. Inside, it implements the logic to:
- extract the event-time and the event id
- group all records with similar even-time
- write the groups into corresponding, event-time-partitioned table
After that, a batch process, represented here by Apache Spark, is triggered by an orchestrator at regular basics. The process takes all records from the table and overwrites the data stored in the event time-partitioned object on S3. The idea is quite simple but there are some points to keep in mind.
First, what to do with late data, ie. what happens if the consumer from the picture encounters the late events for the "2020-05-06" partition? One solution for that could be the storage of the partitioned tables changed in a given day, like:
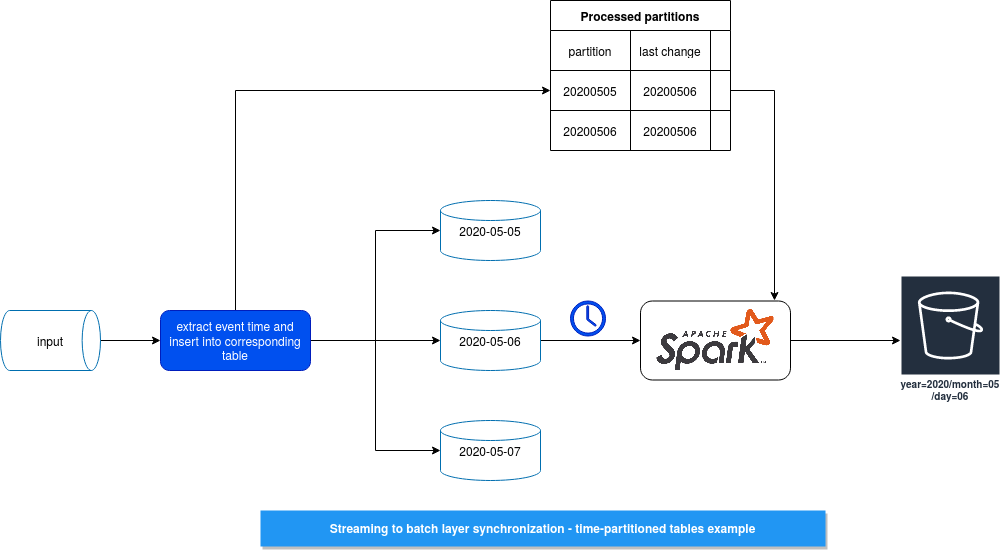
Thanks to this index, the batch process will offload only the tables that changed since the last processing. And it can filter them thanks to the last change column, here represented as a date but it can also be finer-grained and go into minutes granularity.
The problem of the late data seems to be fixed but it's not the single one we should face. This proposal is quite simplistic but because of this simplicity, it's not optimal because every time the whole table is synchronized with the batch layer. Once again, we can overcome this issue and reorganize the storage on the event-time-partitioned tables. We could add a new column called append_time and in every batch execution, retrieve on the new rows from the last execution. The drawback of this approach is the complication of the streaming consumer that now should check what keys that it is going to insert are already in the data store, and insert only the new ones. Otherwise, we would introduce duplicated records and that's something we want to avoid in this approach.
Another drawback of this proposal is its cost. In a simpler design, the consumer would write the records directly to the event time-partitioned storage, without this intermediary storage layer. But it doesn't guarantee the complete deduplication of the records. Of course, the consumer could use an in-memory storage to keep the ids of already synchronized records but very often this store is limited in time (= don't keep all keys forever).
As you can see then, there is no one-size-fits-all solution. If you want to avoid 100% of duplicates, an intermediary buffer like the one presented in the blog post seems to be required, despite the maintenance and cost drawbacks. On the other hand, if you know that your producers won't send you again the same events in the future, maybe a small in-memory state store to keep the duplicated will be enough.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Data deduplication with an intermediate data store here:
Related blog posts:
- Data Engineering Design Patterns: Dynamic Data Overwriter
- Data Engineering Design Patterns: Hybrid continuous consumer
- Get it once, few words on data deduplication patterns in data engineering
A few months ago I found an architecture proposal using an intermediate data store to deal with the duplicates. If you want to discover more details about this concept, everything is explained in the new blog post ? https://t.co/C8CrJLjGPO
— Bartosz Konieczny (@waitingforcode) October 4, 2020