
Poor quality of data comes out in different forms. The incomplete datasets, inconsistent schemas, the same attribute represented in multiple formats are only some of the characteristics. Another point that I would like to address in this post, are duplicates.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Before showing you some approaches to deal with duplicates, a few words of explanation. Duplicates are bad because:
- volume of data - in your processing logic you will always have much more data to process which will often translate by slower processing
- application's logic - you will need to handle duplicates, so complexify your data processing logic. If it's inevitable and your processing is a group by key-based, think about local deduplication to avoid multiple shuffles. I wrote more about it in Local deduplication or dropDuplicates? article.
- poor business insight - if you can deduplicate your data, you've still a chance to generate meaningful data to your business users. If it's not the case and you are unable to say what property should be processed, well, let's say that it will be much harder (to not say impossible)
But it doesn't mean that you cannot use your dataset. You do, but it will come with a higher cost than if you would work on a clean dataset. In the 5 sections below I will explain different techniques to keep your dataset as clean as possible for the case of reprocessing; even though having a perfect dataset without duplicates may be hard to achieve depending on the use case and the storage.
Dataset versioning
The first approach uses the principle of immutability. The idea is that we write every dataset only once and if we need to regenerate it, we generate a completely new dataset in a different location.
Let's take an example of files that we generate daily. If we need to regenerate the dataset for the given day, we'll do it in a different directory, for example with a directory representing the version of our dataset:
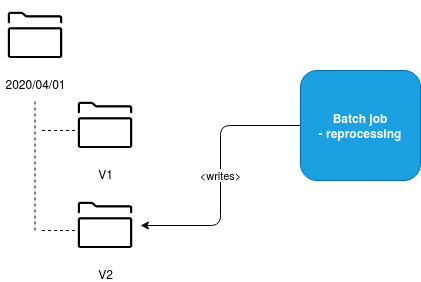
In consequence, all the consumers of this application must be aware of the exposition logic. This exposition logic can be based on the biggest version number or a manifest file storing the dataset in use. And this is a big drawback of this approach because the downstream processing isn't any more a simple "take & process" logic.
To overcome this issue, we can use a system of aliases, very similar to the one present in Elasticsearch indexes. For the case of our files, we should be able to create a redirection for the clients, like in the following schema with the help of a proxy or a shared dependency:
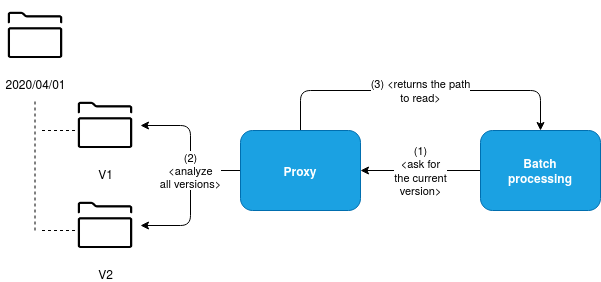
Once again, this extra proxy layer has its costs and drawbacks. After all, it's another layer of indirection that complexifies the data processing logic because instead of using a simple API of your storage, you will need to call an HTTP endpoint or add a dependency, which is not natively implemented in data processing frameworks. In other words, to use this solution, you'll have to add a preprocessing part in your code to retrieve the right place to read from. Hopefully, it can be done only once with a shared dependency inside your organization.
Among the good points of this solution is the lack of physical removal. If for any reason removing the data is slow or costly, you can simply skip it and expose the new dataset.
Partitioning
The second strategy consists of using partitioned storage. Once again, if we process the data on a daily basis, we can write it to the directories partitioned by day. Alongside the data processing framework features like save modes in Spark SQL, you can create a job that will automatically manage the duplicates by removing the old dataset and generate the new one instead.
This strategy will be much or less easy to implement, depending on the data storage used in your system. It will work pretty easily with file systems/object stores, a little bit much harder with tables where you will need to implement a kind of time-series tables to simulate the partitioning feature. You can see an example of it in the following schema where hourly-based jobs write some data into a daily table:
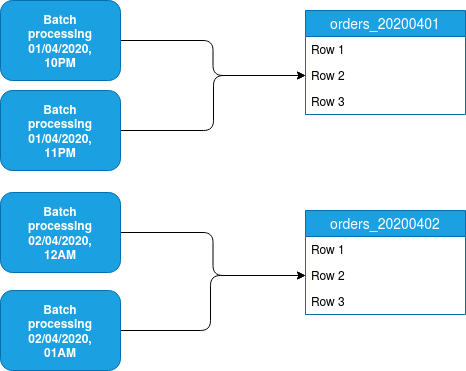
Of course, here too we retrieve some drawbacks. The partition unit is a kind of "all-or-nothing" storage, so if you need to reprocess the data, you will always need to do it for all time ranges included in the given partition. On the flip side, you get an easy way to reprocess the data without any human intervention (except the one of relaunching the pipeline).
Data versioning
This approach is a little bit different than the one from the first section. Here we consider the storage of a single dataset, that still can be partitioned, but globally is considered as a single unit:
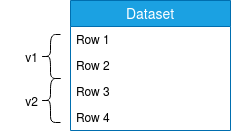
The idea is to use a more and more popular strategy nowadays based on the time travel feature that allows us to read the dataset in a specific version, apply some changes on it and maybe overwrite everything before relaunching the processing:
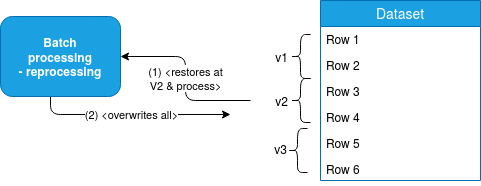
I described an example of this approach in Output invalidation pattern with time travel article.
This kind of data versioning works also on more classical databases (RDBMS) and data warehouses where you can rollback to the last valid version of your dataset with CREATE TABLE AS... statement:
CREATE TABLE orders_valid_10042020 AS SELECT * FROM orders_valid_20022020 WHERE change_date < '2020-03-01';
In the query above, I'm creating a new table storing all valid orders after identifying the invalidity period (after 01/03/2020). But as you can see, here we'll also have the problem of data exposition which can be easily addressed by using a view. The drawback is that using a VIEW for a single table is a kind of hack with an unnecessary level of indirection. But if you accept this trade-off, it should be fine.
Idempotent logic and storage
Another solution to avoid/reduce the duplicates uses idempotency. What's the goal? First, your business logic should tend to generate the same output for the same input and the same code base. The unicity of the output means here that if the first execution of your pipeline generated JSON lines for one processed entry, then the second execution should also generate 2 of them, maybe with different properties inside. Code idempotence should then work with storage idempotence, for example by using key-based storage:
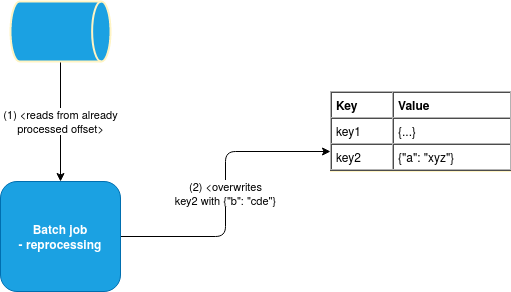
or the same names, for example in case of generated files:
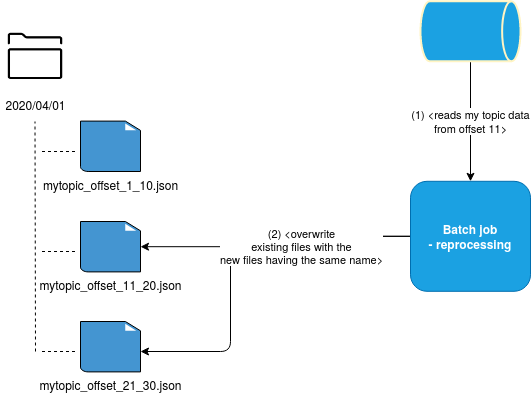
Unfortunately, it's not always possible for the idempotence of the business logic, especially if you need to fix a regression that will change the generated outcome by returning much more or much fewer records. But despite that, it's always important to keep this approach in mind and rely on the storage properties to reduce the risk of duplicates in case of reprocessing.
Clean before write approach
Finally, the last strategy we can apply uses delete before write approach. Apache Spark Structured Streaming file sink is a great example of that. Every time a new micro-batch query executes, this sink generates a metadata file where Spark writes all the files created in the last query. Now, if you reprocess such a pipeline, you can simply read the file, delete all created entries, and relaunch the processing, like in the schema below:
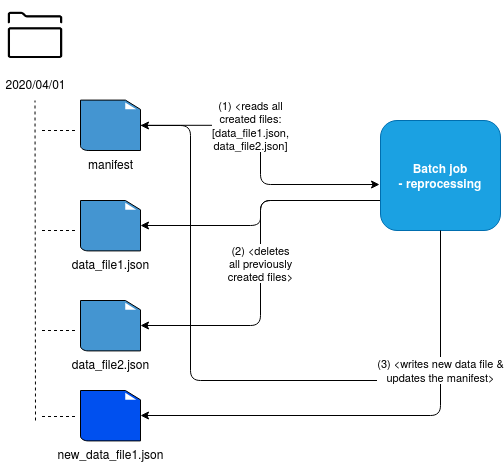
Keeping away from the duplicates is not an easy task. Depending on your data storage, business logic, it will be much more or less harder to implement. However, I hope that thanks to the approaches described in this article, this task will be much easier to achieve :)
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Data Engineering Design Patterns: Hybrid continuous consumer
- Get it once, few words on data deduplication patterns in data engineering
- Good to know if you merge - reprocessing challenges
I've never drawn so much ? In the new post, I presented different storage and processing techniques to deal with duplicates in case of data reprocessing https://t.co/CqE0eQLmbS
— Bartosz Konieczny (@waitingforcode) June 13, 2020