
I don't know whether it's a good sign or not, but I start having some convictions about building data systems. Of course, building an architecture will always be the story of trade-offs but there are some practices that I tend to prefer than the others. And in this article I will share my thoughts on one of them.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
TL; TR: that's only my thoughts about the topic and I don't have the monopolies of knowledge. Take it carefully and do not consider it as a single source of truth.
First and foremost, what do I mean by landing zone and direct writes? To understand the difference, let's take the example of a data pipeline that processes some JSON files and has to write it to a data warehouse storage (structured data). The dataflow is represented in the following diagram:
How can this pipeline be implemented? One approach would write the data directly to the data warehouse solution from the data processing logic and that's something I'm calling here the direct writes. The second one would pass through intermediary storage and the data loading step would be performed by another process managed by an orchestrator. For the purpose of this blog post I called this intermediary storage landing zone. The following picture summarizes these 2 approaches:
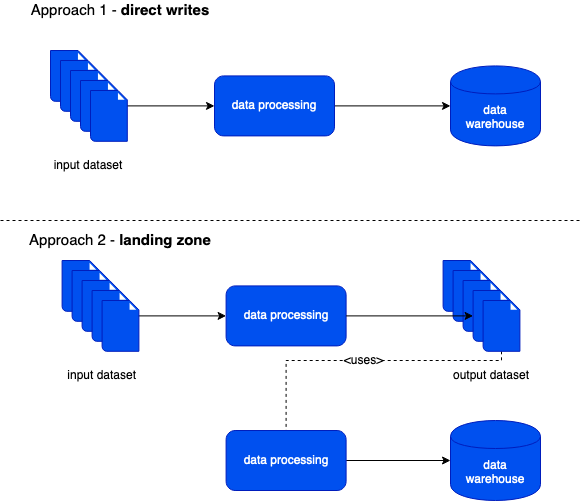
I won't hide it, I like the second one. Why? Due to the following reasons:
- maintenance - let's imagine the case that we received a lot of new records breaking one of the constraints on our data warehouse. It happened on a Friday evening. You go back on Monday and now have to reprocess almost 3 days to have the fresh data once again.
With the compute separated from the load, data generation moves forward and everything you need to do is only to relax the constraint on the data store (supposing you can). The pipelines working on semi-structured formats can be particularly sensitive to this kind of issue. Of course, if you cannot change the constraints, you will have to fix the problem on the processing level and relaunch it, or if you can, just reprocess the files and implement the new rule on the processing side. - better backpressure control - the separation gives also more flexibility in the matter of backpressure. Indeed, we're still materializing the data somewhere but this "somewhere" is a more reliable environment like an object store or distributed file system. Loading the same big batches of data simultaneously to a transactional data store could be much more impactful. When you delegate the loading to an orchestrator, it's up to you to define when each of these big batches should be loaded. The computing environment is less sensitive to this point because with nowadays cloud services, you can dedicate a compute environment for every computation and shut it down just afterward. It's not necessarily the case of a data warehouse or other data store exposed to the rest of your organization. You can imagine a situation where 2 of your important pipelines must be reprocessed. If you can generate them in parallel, in separate clusters, and also load them sequentially to not monopolize all the resources of your data warehouse, you can control the pressure of your data store much easier.
- optimized loading techniques - let's take an example of Apache Spark SQL. If a sink is not natively available, you will probably process your data and write to the sink with a foreachPartition where you will open a connection at the beginning and perform the load. The problem is that for our use case of a data warehouse, this operation won't be parallelized as it could be with a bulk load method exposed by the storage (eg. COPY on Redshift, load on BigQuery). How are both different?
With the bulk load methods, the operation will take all files you generated (let's suppose 200 files generated by every Spark task) and perform the load in parallel - or try to parallelize it as best as it can. If you decide to write the data directly from your processing logic with a kind of foreach loop, you will not parallelize because every writer will create a separate process and probably transaction, so the overhead may be stronger. - flexibility - having a landing zone storage gives a little bit more flexibility for further data use. Even if today you need to load it only to a data warehouse, tomorrow - and for tomorrow I mean several months later - you may need to use this data in other places. Without a landing zone, you will probably need to perform a big dump of your data store which depending on the technology can be easier or harder to achieve. With a landing zone, you can simply take this data at any moment and use it. It can be also useful not only for different business use cases but also for other members of your team. Loading a JSON or CSV file from Pandas can be much easier to perform by a data scientist rather than performing a JDBC connection to a database.
Here I like to think about this landing zone as about a topic in Apache Kafka (Kappa architecture) which is the source for different business use cases. The principle is the same except that the source will be an object store or a distributed file system. - performances - parallelizing files processing is much easier than parallelizing databases or data warehouses. In Apache Spark SQL you have to identify a numerical column on your schema that will be used in the partitioning logic. I wrote about this topic in Partitioning RDBMS data in Spark SQL article. Of course, there is still a danger of lower parallelization due to the not parallelizable compression format, but the parallelization at reading will be still easier to perform on files than on databases.
- data security - here I don't mean the security in terms of data access but in terms of data availability. With the data stored in the landing zone, which IMO has good reliability (less space storage constraints, default replication on cloud providers object stores), losing your data warehouse doesn't mean losing your data. You will be able to enhance the backups and always be able to reload the most up-to-date data without regenerating everything produced after the last performed backup.
- cost efficiency - this point is related to my first example. Let's imagine that your writing processes failed during the weekend. On Monday you will then need to retrigger the failed processing, so you will multiply the processing cost by 2 (supposing you use ephemeral clusters). On the other hand, if you only have to perform the loading, your cost will probably not increase because the operation is performed by the always-running database.
But don't get me wrong, I'm still convinced that the solution should be adapted to the problem and maybe for different use cases, a landing zone will not exist. I just hope that thanks to the list you will maybe discover new pros of using a landing zone that may have a real impact on your architecture design! And I'm really curious about your vision for this problem and will be glad if you share it on the comments below :)
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Data Engineering Design Patterns: Hybrid continuous consumer
- Get it once, few words on data deduplication patterns in data engineering
- Good to know if you merge - reprocessing challenges
Landing zone vs direct loading? In my today's post I listed some points in favor of the former one. What's your point of view for this question? Eager to improve my data systems vision ? https://t.co/KBoVVydFTQ
— Bartosz Konieczny (@waitingforcode) July 19, 2020