
If Delta Lake implemented the commits only, I could stop exploring this transactional part after the previous article. But as for RDBMS, Delta Lake implements other ACID-related concepts. One of these are isolation levels.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Reminder
Before going further, a quick reminder about the isolation levels. In a nutshell, they define how other users see the active transaction, hence, how they see the data written by this transaction.
Weak levels make the data available sooner but with the risk of dirty reads or lost updates. Why can they happen? Well, a transaction is there to guarantee an integrity of the data processed in the query. Therefore, if there is something extra needed to guarantee the consistency, there is an inherent risk of failure for the transaction. And because of that:
- Dirty reads refers to the data written by a failed transaction but already read by the consumer with a weak isolation level.
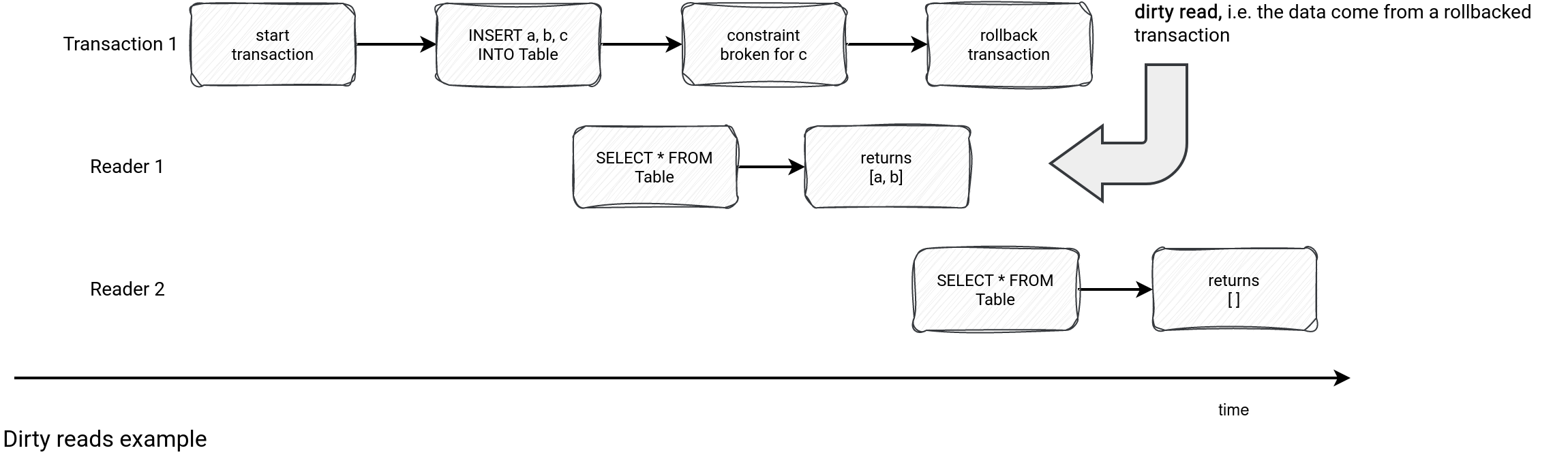
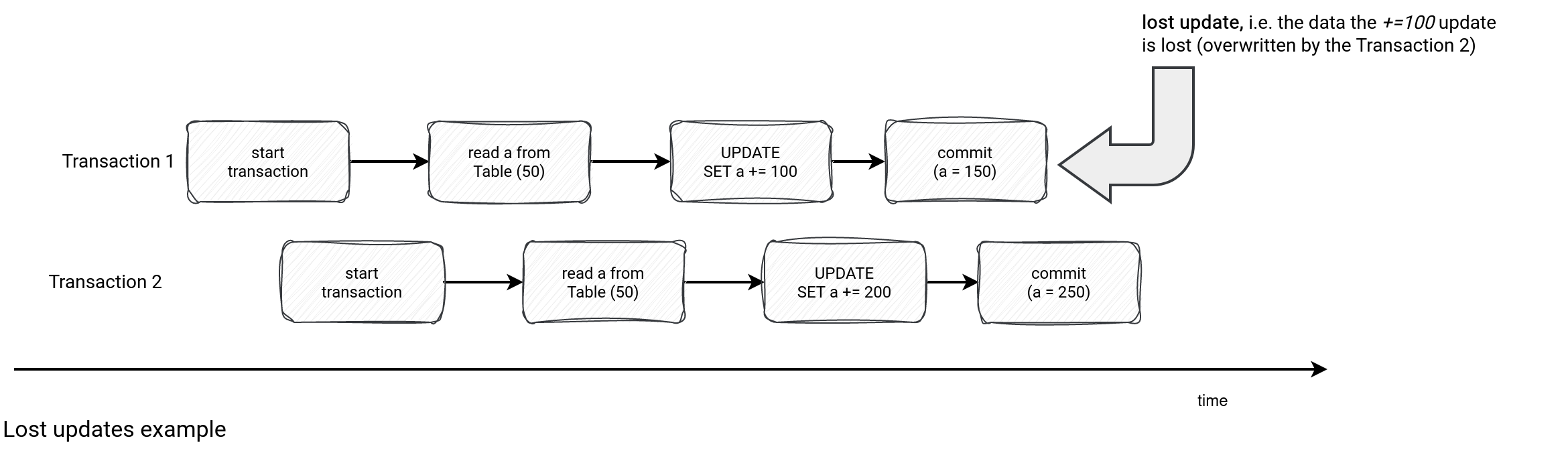
- Lost updates refers to the same data updated by two concurrent writers where the second writer overrides the first update. Instead, the second update should start after the first and operate on the updated data.
Stronger isolation levels prevent these issues but with the trade-off of the performance. They require an additional coordination level that controls the concurrency of the operations.
Setting the isolation level in Delta Lake
Isolation level is individually set for each table with the delta.isolationLevel property:
sparkSession.sql(
s"""
|CREATE TABLE ${tableName} (id bigint) USING delta
| TBLPROPERTIES ('delta.isolationLevel' = 'Serializable')
|""".stripMargin)
There are 3 isolation levels in Delta Lake code base but only the first one from the list below, are available for the table settings:
- Serializable. That's the strictest one.
- WriteSerializable. That's the default one.
- SnapshotIsolation. That's the one used by the readers but not only. In the next section you'll see that sometimes the write transactions can downgrade to this level to avoid meaningfulles conflicts and failures.
Using anything else will lead to a failure:
Exception in thread "main" java.lang.IllegalArgumentException: requirement failed: delta.isolationLevel must be Serializable
at scala.Predef$.require(Predef.scala:281)
at org.apache.spark.sql.delta.DeltaConfig.validate(DeltaConfig.scala:59)
at org.apache.spark.sql.delta.DeltaConfig.apply(DeltaConfig.scala:70)
at org.apache.spark.sql.delta.DeltaConfigsBase.$anonfun$validateConfigurations$1(DeltaConfig.scala:163)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:286)
There is currently an open Merge Request to enable the WriteSerializable level in the vanilla Delta Lake. Other levels seem to be available on the Databricks version only. You can see this when you compare the documentation about conflicts:
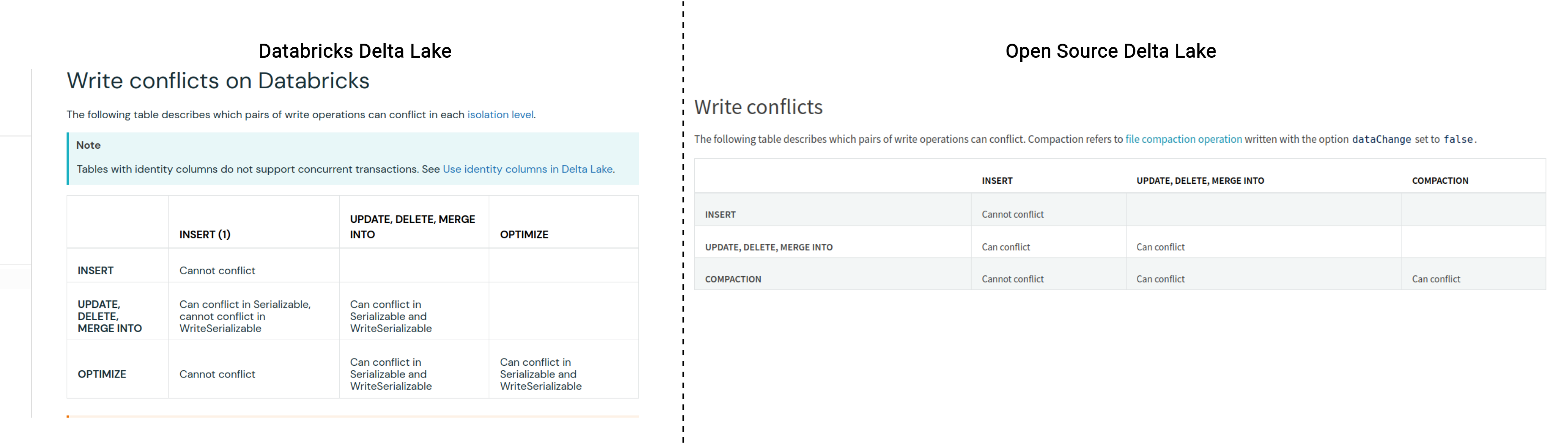
Serializable vs. WriteSerializable
However, both serializable levels are present in the code base and they define a different behavior. Theoretically, let's see what is the difference if they were implemented. To understand it, let's deep dive into the code, and more exactly, into the ConflictChecker#checkForAddedFilesThatShouldHaveBeenReadByCurrentTxn. The function starts with this mapping:
val addedFilesToCheckForConflicts = isolationLevel match {
case WriteSerializable if !currentTransactionInfo.metadataChanged =>
winningCommitSummary.changedDataAddedFiles // don't conflict with blind appends
case Serializable | WriteSerializable =>
winningCommitSummary.changedDataAddedFiles ++ winningCommitSummary.blindAppendAddedFiles
case SnapshotIsolation =>
Seq.empty
}
In a human friendly language you can see both serializable isolation levels detect conflicts by analyzing all files modified in the transaction about to be committed. Additionally, they also include the blind appends, so the files created from a simple INSERT INTO statements. However, this is only true for the WriteSerializable level if the pending transaction contains any metadata changes. Otherwise, the blind appends are ignored. Why this distinction? It comes from the streaming updates problem as explained by Prakhar Jain in this commit:
Now any transaction which has non-file actions goes through conflict detection against blind append unlike before. This may lead to failure of such transactions.
This was intentionally done to stop METADATA / other non-file-action transactions to follow conflict detection. But as a side effect, Streaming Updates (which have SetTransaction action) also started following this flow and started failing.
Downgrading isolation level
But the isolation level resolution is not that simple. Delta Lake can decide at a runtime to downgrade the isolation level! The magic happens in OptimisticTransactionImpl#getIsolationLevelToUse:
protected def getIsolationLevelToUse(preparedActions: Seq[Action], op: DeltaOperations.Operation): IsolationLevel = {
val isolationLevelToUse = if (canDowngradeToSnapshotIsolation(preparedActions, op)) {
SnapshotIsolation
} else {
getDefaultIsolationLevel()
}
isolationLevelToUse
}
Under some conditions the initial isolation level can be changed to the SnapshotIsolation. When? If the data files modified within the transaction don't contain the data changes and:
- The first condition is about the transaction content. If it's only about the metadata, the level cannot be relaxed:
if (hasNonFileActions) { // if Non-file-actions are present (e.g. METADATA etc.), then don't downgrade the isolation // level to SnapshotIsolation. return false } - The second condition is about the initial transaction level. The Serializable level can downgrade only if it doesn't contain any data files changed, hence if it concerns an operation like OPTIMIZE or Auto-compaction. The WriteSerializable is also conditioned by that but it requires the committed operation not to change the data additionally. Regarding the latter condition, any operation executed against a Delta Lake table has a changesData flag. It's set to false by default but for some operations, it changes to true. Among them you'll find: streaming updates, partition deletes, truncate, merge, update, replace table, restore table to a previous version, or clone a table:
val allowFallbackToSnapshotIsolation = defaultIsolationLevel match { case Serializable => noDataChanged case WriteSerializable => noDataChanged && !op.changesData case _ => false // This case should never happen } allowFallbackToSnapshotIsolation
An isolation level downgraded to the snapshot isolation skips some of the conflict detection methods, as for example detection of the concurrently written files:
protected def checkForAddedFilesThatShouldHaveBeenReadByCurrentTxn(): Unit = {
recordTime("checked-appends") {
// Fail if new files have been added that the txn should have read.
val addedFilesToCheckForConflicts = isolationLevel match {
case WriteSerializable if !currentTransactionInfo.metadataChanged =>
winningCommitSummary.changedDataAddedFiles // don't conflict with blind appends
case Serializable | WriteSerializable =>
winningCommitSummary.changedDataAddedFiles ++ winningCommitSummary.blindAppendAddedFiles
case SnapshotIsolation =>
Seq.empty
}
Examples
The examples for the isolation level overlap the ones from the commits. Therefore, this time you'll find 3 short demos. Two first ones are for the supported isolation levels at the table creation. The first example should create the table correctly...
sparkSession.sql(
s"""
|CREATE TABLE ${tableName} (id bigint) USING delta
| TBLPROPERTIES ('delta.isolationLevel' = 'Serializable')
|""".stripMargin)
(0 to 100).toDF("id").writeTo(tableName).using("delta").createOrReplace()
...while the latter should fail:
sparkSession.sql(
s"""
|CREATE TABLE ${tableName} (id bigint) USING delta
| TBLPROPERTIES ('delta.isolationLevel' = 'WriteSerializable')
|""".stripMargin)
(0 to 100).toDF("id").writeTo(tableName).using("delta").createOrReplace()
The last code snippet demonstrates the isolation level downgrade. Here, the process executing the OPTIMIZE operation changes the level to the snapshot isolation, as I explained in the previous section:
sparkSession.sql(
s"""
|CREATE TABLE ${tableName} (id bigint) USING delta
| TBLPROPERTIES ('delta.isolationLevel' = 'Serializable')
|""".stripMargin)
(0 to 100).toDF("id").writeTo(tableName).using("delta").createOrReplace()
val deltaTable = DeltaTable.forName(tableName)
val barrier = new CountDownLatch(2)
new Thread(() => {
try {
println("Starting the 'OPTIMIZE'")
deltaTable.optimize().executeCompaction()
} finally {
barrier.countDown()
}
}).start()
new Thread(() => {
try {
while (barrier.getCount != 1) {}
// Soon after the OPTIMIZE, let's start the writing
println("Starting the 'update 100'")
(0 to 100).toDF("id").write.format("delta").insertInto(tableName)
} finally {
barrier.countDown()
}
}).start()
barrier.await()
I'm closing the transactional chapter of Delta Lake exploration, at least for now. Initially I wanted to cover the checkpoint but it's under a serious refactoring for the incoming release. So I prefer to keep it for Delta Lake 3.0.0!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Commit log decorator with userMetadata property
- Truncating a Delta Lake table, aka metadata-only operations
- Idempotent writer
If Delta Lake implemented the commits only, I could stop exploring this transactional part after the previous article. But as for RDBMS, #DeltaLake implements other ACID-related concepts, such as isolation levels ? https://t.co/OilPib06dK
— Bartosz Konieczny (@waitingforcode) September 4, 2023