
In the previous blog post about Delta Lake you discovered the logic for the writing part. Meantime Delta Lake 2 was released and it's for this brand new version that I'm going to share with you some findings related to the data reading.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Reading flow
In a nutshell, the reading logic consists of creating a Delta Lake instance of HadoopFsRelation that will be later used in Apache Spark planning and execution:
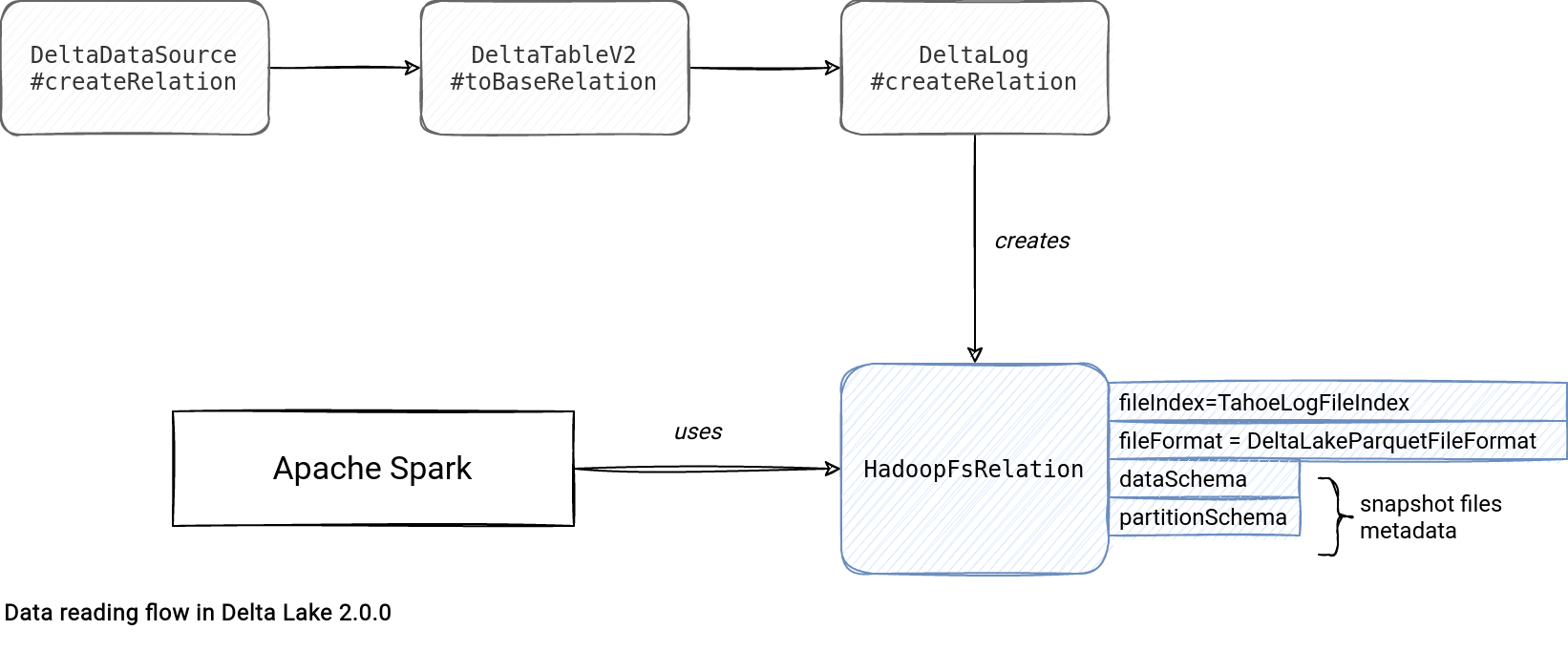
However, there are many other interesting and important things going on during this HadoopFsRelation creation. First, DeltaLog checks the snaphot version to read which by default is the most recent commit. For custom time-travel scenarios, this value can be set to a past commit, like shows this code snippet:
case class DeltaTableV2(
// …
private lazy val timeTravelSpec: Option[DeltaTimeTravelSpec] = {
if (timeTravelOpt.isDefined && timeTravelByPath.isDefined) {
throw DeltaErrors.multipleTimeTravelSyntaxUsed
}
timeTravelOpt.orElse(timeTravelByPath)
}
lazy val snapshot: Snapshot = {
timeTravelSpec.map { spec =>
val (version, accessType) = DeltaTableUtils.resolveTimeTravelVersion(
spark.sessionState.conf, deltaLog, spec)
val source = spec.creationSource.getOrElse("unknown")
recordDeltaEvent(deltaLog, s"delta.timeTravel.$source", data = Map(
"tableVersion" -> deltaLog.snapshot.version,
"queriedVersion" -> version,
"accessType" -> accessType
))
deltaLog.getSnapshotAt(version)
}.getOrElse(
deltaLog.update(stalenessAcceptable = true, checkIfUpdatedSinceTs = Some(creationTimeMs))
)
}
The Snapshot class represents a state of the Delta table at a specific version and it's used by TahoeLogFileIndex from the createRelation method to provide the list of files to read. Additionally, the Snapshot instance has the metadata information referenced by the HadoodFsRelation data and partition schema and used by the function detecting the Delta Lake table file format. As of the time of writing, the single supported format is DeltaParquetFileFormat.
Log file index
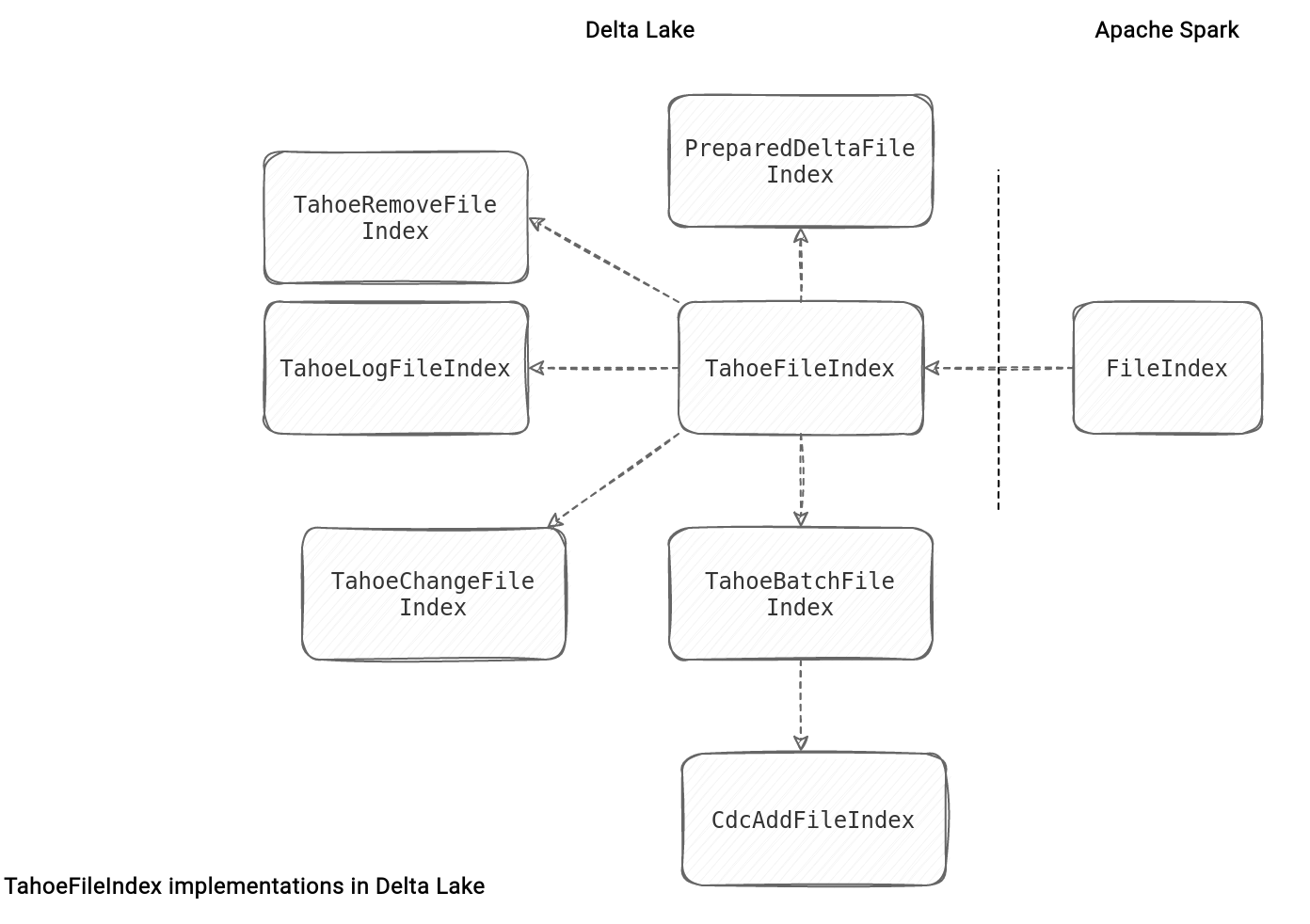
After the general introduction it's a great moment to see the presented concepts in depth. To start, the famous log file index represented by the TahoeLogFileIndex. It implements the TahoeFileIndex abstract class that itself implements Apache Spark's FileIndex interface.
The TahoeLogFileIndex has multiple attributes that helps define its purpose in Delta Lake:
- table version - for now used only for debugging purposes. Its default and single implementation uses the snapshot version.
- snapshot to scan - the snapshot associated to the index, used for file listing purposes and table version.
- all files - all files associated with the snapshot that might be returned if the reader doesn't specify any predicate.
- all files matching the partition predicate - as above but after applying the partition predicate on the snapshot files.
- size in bytes - size of table files in bytes. It's useful for Apache Spark's Cost-Based Optimizer.
- partition schema - schema of the partition columns. It seems not be used but must be defined as the TahoeFileIndex implements Apache Spark's FileIndex interface.
TahoeLogFileIndex is only one of many implementations of the basic abstract class, the TahoeFileIndex. The others are used for other scenarios, such as:
- Change Data Capture. This feature uses TahoeChangeFileIndex for changed files, CdcAddFileIndex for added files, and TahoeRemoveFileIndex for removed files in the capture feed.
- Streaming micro-batch. Here, Delta Lake exposes the TahoeBatchFileIndex.
- Delta Lake table scan. The PreparedDeltaFileIndex used here is particularly useful for the CBO at the logical plan to know the data volume to read during the scan.
- In-place operations. Delta Lake lists the files impacted by the delete or update action as a part of the TahoeBatchFileIndex.
DeltaScan
Delta Lake also has a logical optimization rule to prepare the best scan over the files. It's called PrepareDeltaScan and works as a 4-steps algorithm:
- ScanGenerator initialization. The interface is implemented by the Snapshot and DataSkippingReader.
- Get or update the DeltaScan associated with the given part of the execution plan. In this step the optimization rule uses the ScanGenerator to get the list of files relevant to the reader query. That's where it'll call the ScanGenerator's filesForScan(projection: Seq[Attribute], filters: Seq[Expression]) to get the list of files to scan after applying the filters on top of the files. It might happen that not all filters get applied. If it happens, DeltaScan instance will keep them in the unusedFilters attribute.
- Build an instance of PreparedDeltaFileIndex from the previously created DeltaScan, referenced by the index in the preparedScan attribute:
case class PreparedDeltaFileIndex( override val spark: SparkSession, override val deltaLog: DeltaLog, override val path: Path, preparedScan: DeltaScan, override val partitionSchema: StructType, versionScanned: Option[Long]) extends TahoeFileIndex(spark, deltaLog, path) - Replace the index in the initial plan by the PreparedDeltaFileIndex instance created before. If the filters involve generated columns, the rule will convert them to partition filters and add as a part of the Filter node wrapping the initial plan.
Sounds abstract? Let's analyze these 4 steps in a concrete example applying a partition filter is_even = true:
- The ScanGenerator corresponds to a Snapshot class of that type:
Snapshot( path=file:/tmp/acid-file-formats/003_reading/delta_lake/_delta_log, version=1, logSegment=LogSegment(file:/tmp/acid-file-formats/003_reading/delta_lake/_delta_log,1, WrappedArray( DeprecatedRawLocalFileStatus{ path=file:/tmp/acid-file-formats/003_reading/delta_lake/_delta_log/00000000000000000000.json}, DeprecatedRawLocalFileStatus{path=file:/tmp/acid-file-formats/003_reading/delta_lake/_delta_log/00000000000000000001.json))As you can see, the table had 2 commits. - DeltaScan creation from the filtering action applied on the files by the ScanGenerator. The outcome looks like that:
preparedScan = {DeltaScan@17519} filtersUsedForSkipping = {ExpressionSet@17533} size = 2 0 = {IsNotNull@17546} isnotnull(is_even#532) 1 = {EqualTo@17547} (is_even#532 = true) allFilters = {ExpressionSet@17532} size = 2 0 = {IsNotNull@17546} isnotnull(is_even#532) 1 = {EqualTo@17547} (is_even#532 = true) version = 1 files = {WrappedArray$ofRef@17522} size = 2 0 = {AddFile@17539} AddFile(is_even=true/part-00000-77ecedf0-0b0a-4b08-a09a-1e4daccd0f1a.c000.snappy.parquet,Map(is_even -> true)) 1 = {AddFile@17540} AddFile(is_even=true/part-00000-19414711-8c6e-44d6-9777-7f93cac4eaa0.c000.snappy.parquet,Map(is_even -> true)) total = {DataSize@17523} DataSize(Some(3426),None,Some(4)) partition = {DataSize@17524} DataSize(Some(1720),None,Some(2)) scanned = {DataSize@17524} DataSize(Some(1720),None,Some(2)) scannedSnapshot = {Snapshot@16417} Snapshot(...) partitionFilters = {ExpressionSet@17525} size = 2 dataFilters = {ExpressionSet@17526} size = 0 unusedFilters = {ExpressionSet@17527} size = 0 projection = {AttributeSet@17528} size = 3 scanDurationMs = 5224 dataSkippingType = {Enumeration$Val@17529} partitionFilteringOnlyV1As you can notice, the scan generator applied the partition filter on the Snapshot files and returned only the ones matching the is_even = true predicate. - The index references the DeltaScan, so provides the direct access to the data to read during the data query execution (so far we can talk about metadata query execution since Delta Lake was operating on the log information and not the data files.
- The table doesn't have generated columns, so the plan gets the new index without the Filter(...) wrapper. It looks like that:
relation = {HadoopFsRelation@17536} parquet location = {PreparedDeltaFileIndex@17497} Delta[version=1, file:/tmp/acid-file-formats/003_reading/delta_lake] partitionSchema = {StructType@17532} size = 1 dataSchema = {StructType@17533} size = 3 bucketSpec = {None$@8365} None fileFormat = {DeltaParquetFileFormat@17534} Parquet options = {Map$EmptyMap$@17535} size = 0 sparkSession = {SparkSession@12615} org.apache.spark.sql.SparkSession@5e05f3eb x$1 = {Tuple2@17544} (StructType(StructField(id,IntegerType,true), StructField(multiplication_result,IntegerType,true), StructField(is_even,BooleanType,true)),Map(is_even -> StructField(is_even,BooleanType,true))) schema = {StructType@17545} size = 3 overlappedPartCols = {Map$Map1@17546} size = 1
An important difference between the PreparedDeltaFileIndex and TahoeLogFileIndex comes from the sizeInBytes field which, due to the files pre-scanning, is more accurate for PreparedDeltaFileIndex. In consequence, Apache Spark knows better the data to process and can better optimize the physical execution plan:
case class TahoeLogFileIndex(
override val spark: SparkSession,
override val deltaLog: DeltaLog,
override val path: Path,
snapshotAtAnalysis: Snapshot,
partitionFilters: Seq[Expression] = Nil,
isTimeTravelQuery: Boolean = false) //
override val sizeInBytes: Long = deltaLog.snapshot.sizeInBytes
case class PreparedDeltaFileIndex(
override val spark: SparkSession,
override val deltaLog: DeltaLog,
override val path: Path,
preparedScan: DeltaScan,
override val partitionSchema: StructType,
versionScanned: Option[Long]) // ...
override def sizeInBytes: Long =
preparedScan.scanned.bytesCompressed
.getOrElse(spark.sessionState.conf.defaultSizeInBytes)
The DeltaScan rule won't run if the stats-based data skipping is disabled (spark.databricks.delta.stats.skipping). When it happens, the logical plan will contain the TahoeLogFileIndex...:
*(1) ColumnarToRow +- FileScan parquet [id#530,multiplication_result#531,is_even#532] Batched: true, DataFilters: [], Format: Parquet, Location: TahoeLogFileIndex(1 paths)[file:/tmp/acid-file-formats/003_reading/delta_lake], PartitionFilters: [isnotnull(is_even#532), (is_even#532 = true)], PushedFilters: [], ReadSchema: struct<id:int,multiplication_result:int>
...instead of the PreparedDeltaFileIndex:
== Physical Plan == *(1) ColumnarToRow +- FileScan parquet [id#530,multiplication_result#531,is_even#532] Batched: true, DataFilters: [], Format: Parquet, Location: PreparedDeltaFileIndex(1 paths)[file:/tmp/acid-file-formats/003_reading/delta_lake], PartitionFilters: [isnotnull(is_even#532), (is_even#532 = true)], PushedFilters: [], ReadSchema: struct<id:int,multiplication_result:int>
In-place operations
Data reading doesn't only involve SELECT statements. It's also one of the steps in in-place operations. Even though these actions rely on data skipping to identify the files storing the rows impacted by the operation, it's only the beginning stage. After this one, Delta Lake must read the rows from the identified files and apply the in-place operation on top of them:
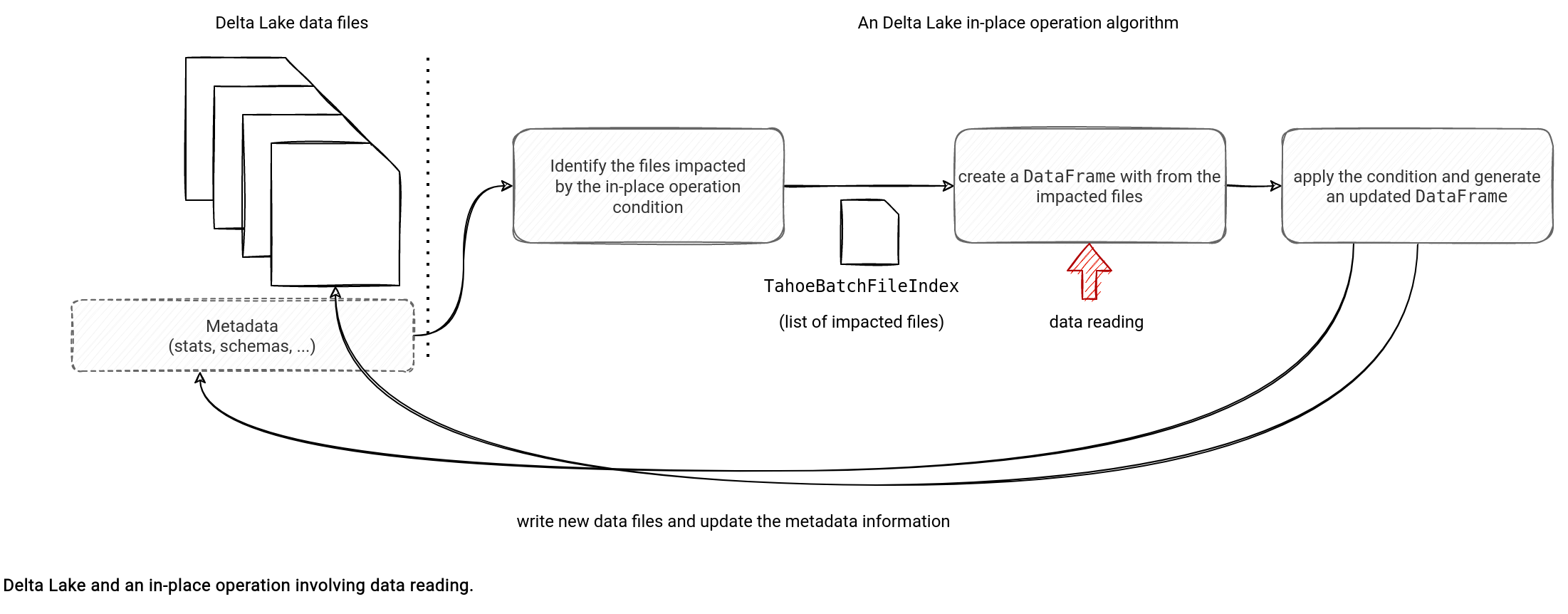
Let's analyze this workflow for an update which runs as an UpdateCommand under-the-hood:
- Files identification happens in the UpdateCommand#performUpdate via the filterFiles method of the OptimisticTransaction class. The method uses partition and data filters to skip irrelevant files.
- Once the impacted files are discovered, UpdateCommand performs the update in the rewriteFiles method. It starts by creating a new HadoopFsRelation referencing the log file index with the impacted files:
case class UpdateCommand( // ... private def rewriteFiles( // ... val baseRelation = buildBaseRelation( spark, txn, "update", rootPath, inputLeafFiles, nameToAddFileMap) val newTarget = DeltaTableUtils.replaceFileIndex(target, baseRelation.location) val targetDf = Dataset.ofRows(spark, newTarget) // ... val updatedDataFrame = UpdateCommand.withUpdatedColumns( target, updateExpressions, condition, targetDf .filter(numTouchedRowsUdf()) .withColumn(UpdateCommand.CONDITION_COLUMN_NAME, new Column(condition)), UpdateCommand.shouldOutputCdc(txn)) - Finally, the data writing step calls the writeFiles method that rewrites the impacted files with the updated rows:
case class UpdateCommand( // ... private def rewriteFiles( // ... txn.writeFiles(updatedDataFrame) } }
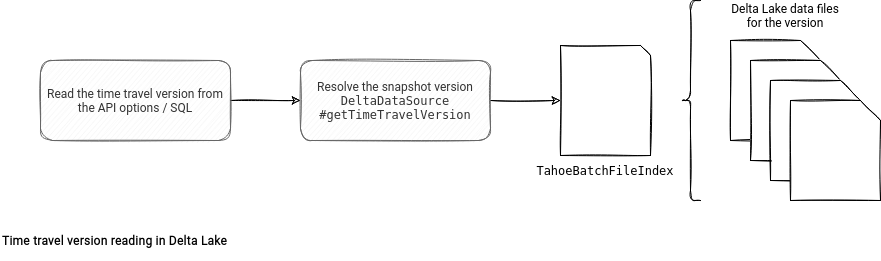
Time-travel
Time-travel is the feature to easily read past data from a Delta Lake table. It doesn't follow the classical path of getting the most recent data to the consumer, so how does it impact the reading flow? Only a little! The whole magic comes from the already mentioned Snapshot class referenced in the TahoeFileIndex:
case class TahoeLogFileIndex(
override val spark: SparkSession,
override val deltaLog: DeltaLog,
override val path: Path,
snapshotAtAnalysis: Snapshot,
partitionFilters: Seq[Expression] = Nil,
isTimeTravelQuery: Boolean = false)
extends TahoeFileIndex(spark, deltaLog, path) {
// ...
override def tableVersion: Long = {
if (isTimeTravelQuery) snapshotAtAnalysis.version else deltaLog.snapshot.version
}
protected def getSnapshotToScan: Snapshot = {
if (isTimeTravelQuery) snapshotAtAnalysis else deltaLog.update(stalenessAcceptable = true)
}
As you might notice, if the reader needs to time travel, the index responsible among others for listing data files, uses the explicitly set Snapshot. Otherwise, it directly uses the most recent committed version. Time travel is just like relaunching the reading on already processed data in the future that involves getting the same data files in exactly the same way, so from the resolved Snapshot.
How does Delta Lake know the query involves time travel? For the API-based access, the DeltaDataSource#getTimeTravelVersion method checks the presence of the time travel options (timestampAsOf, versionAsOf) and depending on the outcome, eventually creates an instance of DeltaTimeTravelSpec. This instance holds the demanded time travel version and goes to the TahoeFileIndex. You can find this flow summarized in the schema below:
Reading options
Besides the features presented before, Delta Lake also has several options reserved to the data readers. You'll find among them:
- spark.databricks.delta.checkLatestSchemaOnRead. Delta Lake always exposes the most recent schema by default. The checkLatestSchemaOnRead configuration runs a schema compatibility check to ensure that even the modified schema is still valid (e.g. in streaming scenarios). If it's not the case, you'll get an DeltaAnalysisException exception with the "The schema of your Delta table has changed in an incompatible way since your DataFrame or DeltaTable object was created." message.
- spark.databricks.delta.stats.skipping. This entry can disable data skipping, so the usage of statistics to skip irrelevant data files to the query. It's a performance-sensitive configuration enabled by default, so disabling it might not be the best idea.
- spark.databricks.delta.properties.defaults.minReaderVersion. It defines the default minimum version of readers for the created tables. Delta Lake uses this number to track down the features supported by each reader and writer. The list is available in the Table protocol versioning documentation page:
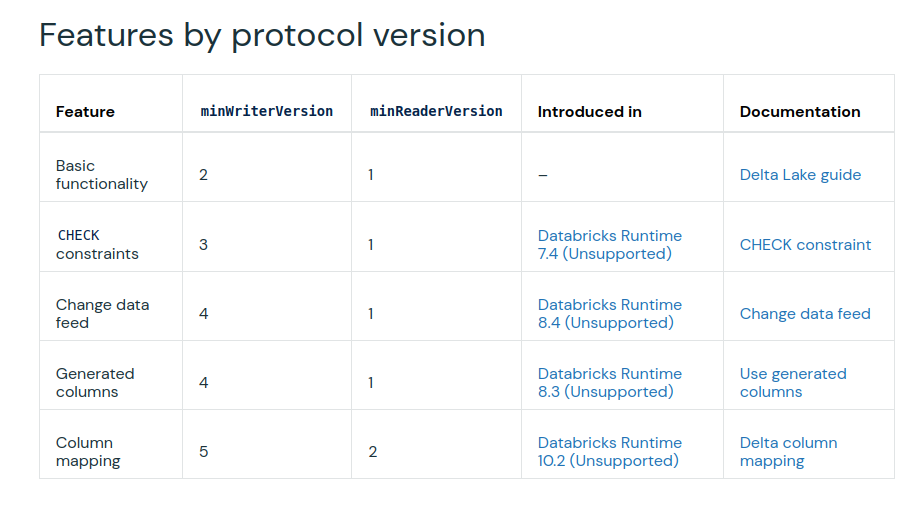
I haven't presented all the reading features in this article. I'm aware it's missing the transaction isolation and Change Data Feed but these are 2 features that I'm going to cover in dedicated blog posts. But before I need to explore the reading part in Apache Iceberg and Apache Hudi!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Commit log decorator with userMetadata property
- Truncating a Delta Lake table, aka metadata-only operations
- Idempotent writer
The next topic of the table formats series is data reading. I've just published the first part describing data reading features in #DeltaLake ? https://t.co/4YTKykzCgq
— Bartosz Konieczny (@waitingforcode) September 18, 2022