
Welcome to the first Data+AI Summit 2024 retrospective blog post. I'm opening the series with the topic close to my heart at the moment, stream processing!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Effective Lakehouse Streaming with Delta Lake and Friends
After watching last year's "The Hitchhiker's Guide to Delta Lake Streaming", I was impatient to see what Scott Haines prepared this year! And I was not disappointed. Together with Ashok Singamaneni, they gave an excellent overview of building a reliable Bronze Layer with the help of Protobuf, Brickflow, and Spark-Expectations, two last ones being Open Source projects developed at Nike.
Notes from the talk:
- Reliable Streaming concepts backed by Protocol Streams. They guarantee consistent data quality in-flight thanks to gRPC, Protobuf, and Protovalidate. All this brings type-safe data exchange with data validation rules support; good news, the rules can be dynamic, as for example the following rules to validate if the date is not in the future:


- Consistent Data Ingestion - High-Trust Ingestion Networks are possible thanks to Protobuf with Protovalidate. Protobuf via its ecosystem brings various automation facilities. One of them is the code generation, including the one for the data validation. Knowing that the validation rules can be shared across domains, it greatly simplifies data ingestion as the data producers can eliminate most of the data quality issues at writing time.
- Streaming Medallion Architecture - like a Medallion Architecture but because of the streaming, it's like a non-stop Medallion
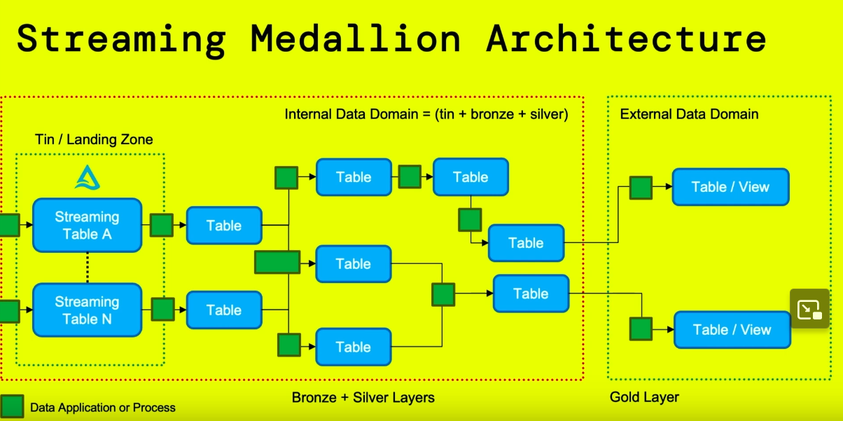
- Tin Layer Pattern - the first layer of the Streaming Medallion Architecture. Its goal is to take data off Apache Kafka and write in Delta Lake; this operation overcomes many issues, especially the ones related to the costly data retention on the Kafka side. The Tin Layer does nothing, it just stores the original records with extra processing time column:

- Tin-to-X Pattern - since the data cannot live in the Tin Layer exclusively, it has to move to the Bronze layer first. Thanks to Protobuf and its binary descriptor that already stores the message schema, and native Protobuf support in Apache Spark, there is no schema definition overhead. You simply need to reference the descriptor in the from_protobuf to get so called lazily generated foundational tables:
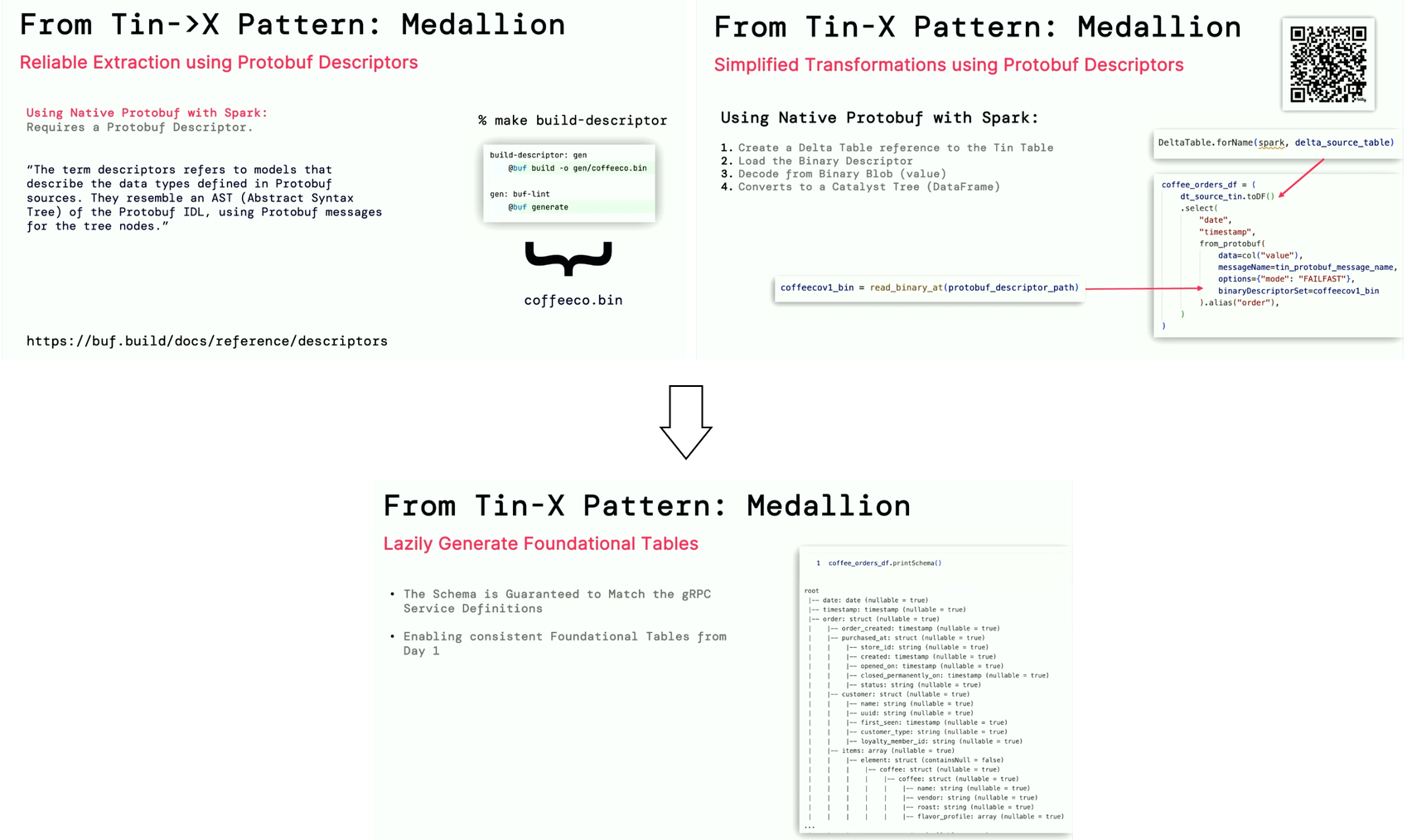
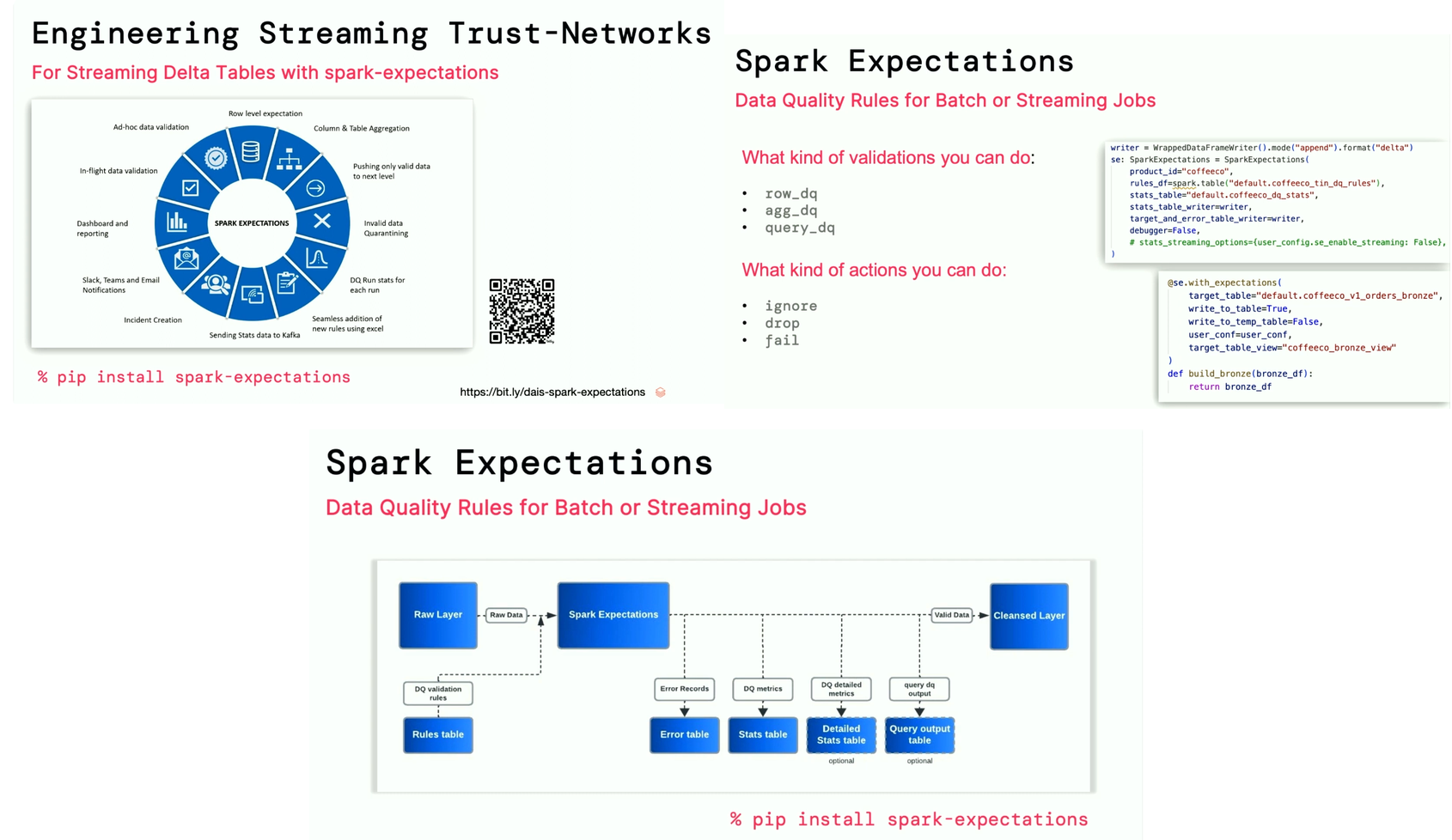
- Streaming Trust-Networks - the next challenge is data quality guarantee on the Silver layer. You can't rely on the Protovalidate since the upper layers in your architecture often store enriched data, eventually combined with other datasets that might not be under Protovalidate control. Thankfully, Ashok and Scott, showed how to guarantee good data quality at this layer with Spark Expectations that natively supports many quality-related aspects, including metrics, error table, or even an external data validation rules table. The library works for streaming and batch, and offers row-, aggregation-, and query-based validators.
- Reliable Workflow Orchestration - data quality was not the single challenge solved with an Open Sourced framework. Databricks' Workflows orchestration was another one. To simplify complex scenarios, Nike team has created Brickflow. It's a Python-based orchestration management library that overcomes the user experience limitations you might have faced while working with YAML or Terraform files to create Databricks Workflows. It brings Apache Airflow experience to the Databricks ecosystem by abstracting in a user-friendly way the Workflows creation.

State Reader API: the New "Statestore" Data Source
I was pretty excited for the next talk given by Craig Lukasik about the State Store Data Source. I have been following the feature from the SPIP, and seeing it running on stage was great!
Notes from the talk:
- Feature available in Databricks Runtime 14.3+ and included in incoming Apache Spark 4
- Two flavors:
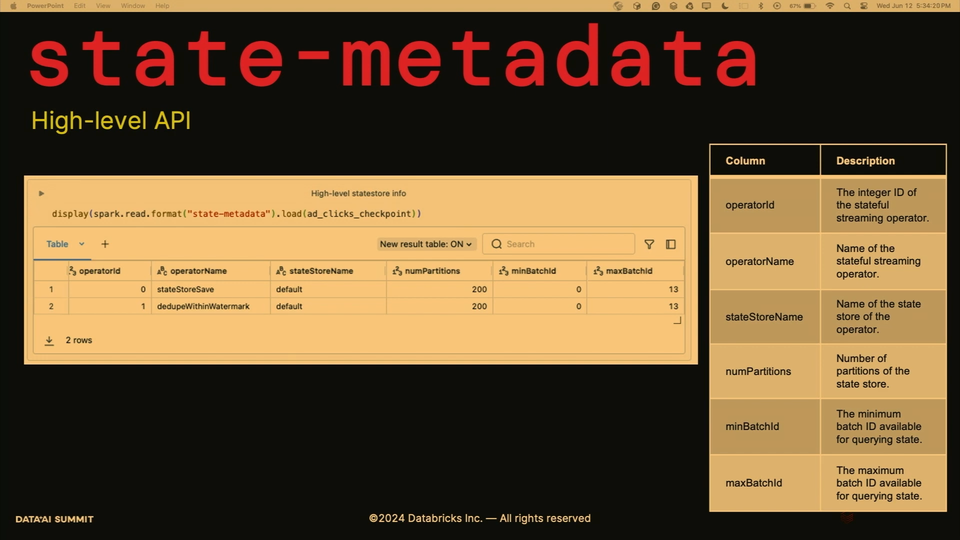
- spark.read.format("state-metadata") returns the metadata about state store, such as partitions, number of batches:
- spark.read.format("statestore") returns the data stored in the state store checkpoint location:
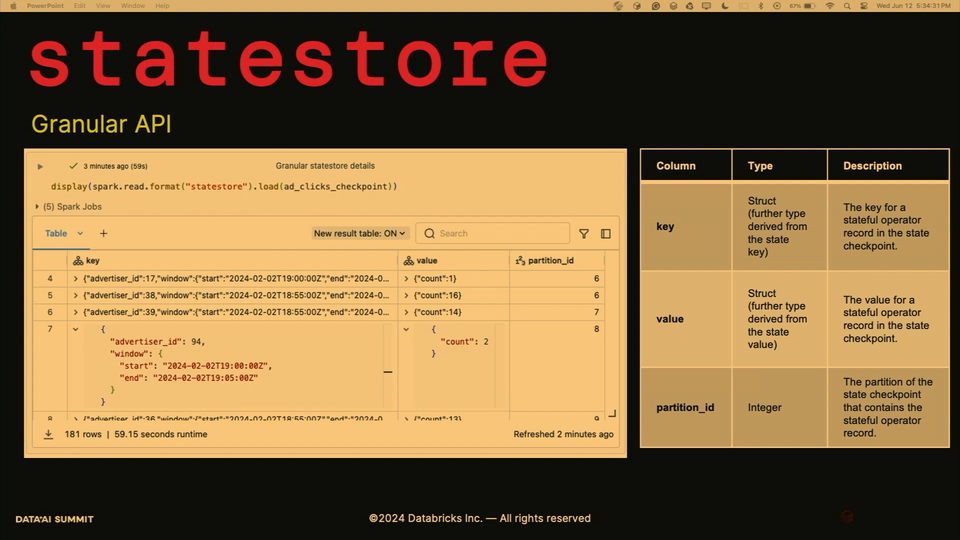
- spark.read.format("state-metadata") returns the metadata about state store, such as partitions, number of batches:
- The new data store is there to simplify development, debugging, and troubleshooting.

Fast, Cheap and Easy Data Ingestion with AWS Lambda and Delta Lake
After Craig's talk, I was impatiently waiting to see how to integrate a serverless environment with Lambda and Delta Lake. Tyler Croy explained that pretty well. And besides the happy path, he also shared the points to look at while implementing the solution.
Notes from the talk:
- Beware if you use Glue Crawlers for updating and integrating large Delta Lake tables to Glue Catalog. The integration is not well done and instead you should be looking for an alternative solution.
- Tyler used an Aurora export to a Delta Lake table as a baseline for his talk. The architecture looks like:
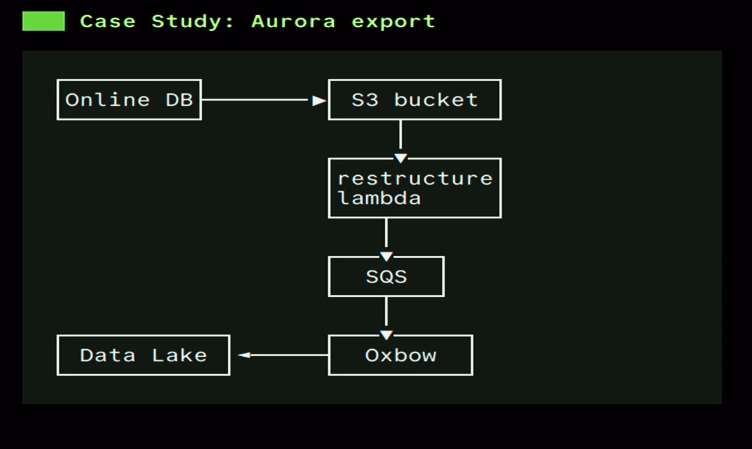 Few words of explanation about the components:
Few words of explanation about the components:
- Online DB is an Amazon Aurora instance. It has been supporting a native export to Apache Parquet for 2 years now (feature announcement).
- S3 bucket is where the export lands. Unfortunately, the outcome is rarely in the shape adapted for being directly imported to a Delta Lake table.
- Restructure Lambda is there to overcome the initial storage limitations, including renaming files and adding partition information to the object key names.
- SQS intercepts any renaming effect. Remember to configure it with the Dead-Letter Queue so that you don't lose events even in case of an error in the pipeline.
- Oxbow is an Open Source project with AWS Lambdas facilities to manage Delta Lake tables. For the use case covered in the talk, the Lambda simply appends new data files to a Delta table. It's worth noting it doesn't operate at the data level at all, i.e. it doesn't interact with the Parquet files' content. Instead, it operates at the metadata, i.e. commit log level.
- Operating on the commit logs doesn't mean low volume. A Delta table can grow really huge, especially in this append-only environment where each record counts. Other caveats are:
- high concurrency - Aurora doesn't guarantee any export consistency. Because of that your serverless architecture can process thousands of small files as well two big ones. Consequently, you may have lock contention and the Lambda can time-out.
- SQS delivery time and Lambda execution time aligned - if both are not aligned, SQS can give the currently processed message to a different Lambda instance.
Databricks Streaming: Project Lightspeed Goes Hyperspeed
The Project Lightspeed has been on my radar since the day 1. When I saw that it will be going Hyperspeed, I couldn't miss the opportunity to see what it involved. Ryan Nienhuis and Praveen Gattu did a great work on explaining the term and showing the impact it will have on streaming pipelines on Databricks!
Notes from the talk:
- Regarding the Project Lightspeed, Ryan started by recalling the features developed in the past two years. They include:
 But it was just the beginning. Databricks streaming team is working on a lot of exciting features that will bring the latency even lower (among others).
But it was just the beginning. Databricks streaming team is working on a lot of exciting features that will bring the latency even lower (among others). - Ryan and Praveen presented 4 use cases that the team has been working on recently:
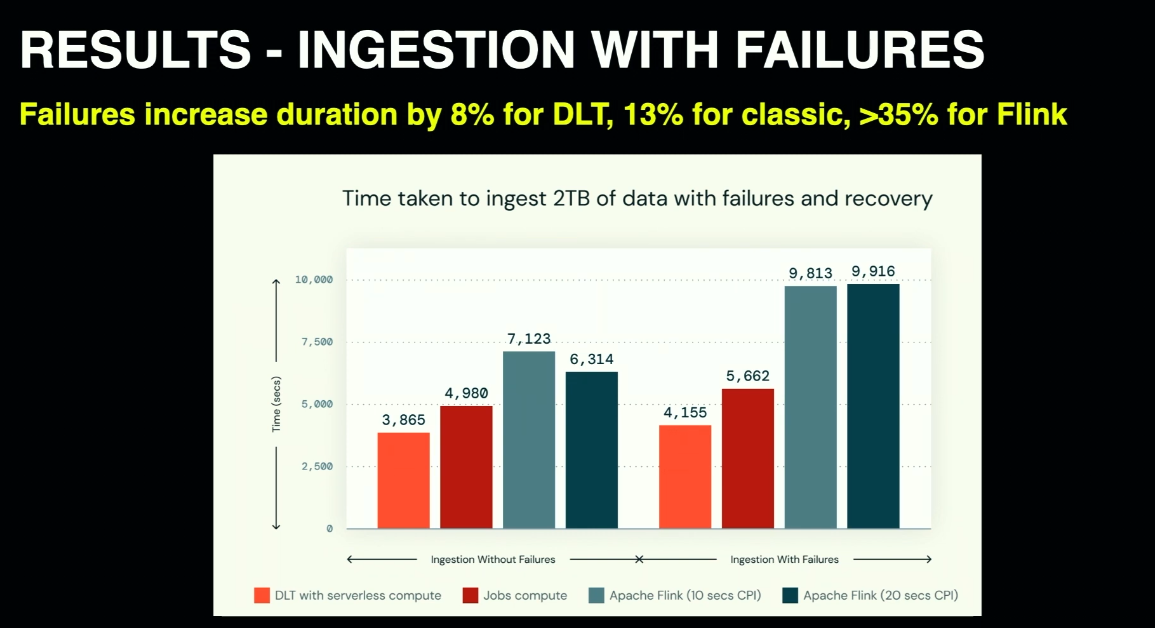
- Data ingestion into lakehouse, aka Streaming ETL. Delta Live Tables serverless shine here and perform better, especially when it comes to the scenario with failures, than Apache Spark Structured Streaming and Apache Flink jobs.
Stream pipelining feature is one of the DLT accelerators. It improves the execution time by scheduling up to 5 next micro-batches as soon as a slot becomes available. All this with the respect for ordering and stateful pipelines. - Operational use cases was another streaming category presented in the talk. Since they're often latency-sensible problems, Databricks will get some huge latency improvements for them with the real-time mode. With no code changes you will be able to have millisecond-based latency, yet again including stateful jobs! The feature will be available in Private Preview in H2 2024. The benchmark results for Kafka-to-Kafka benchmark looks promising:
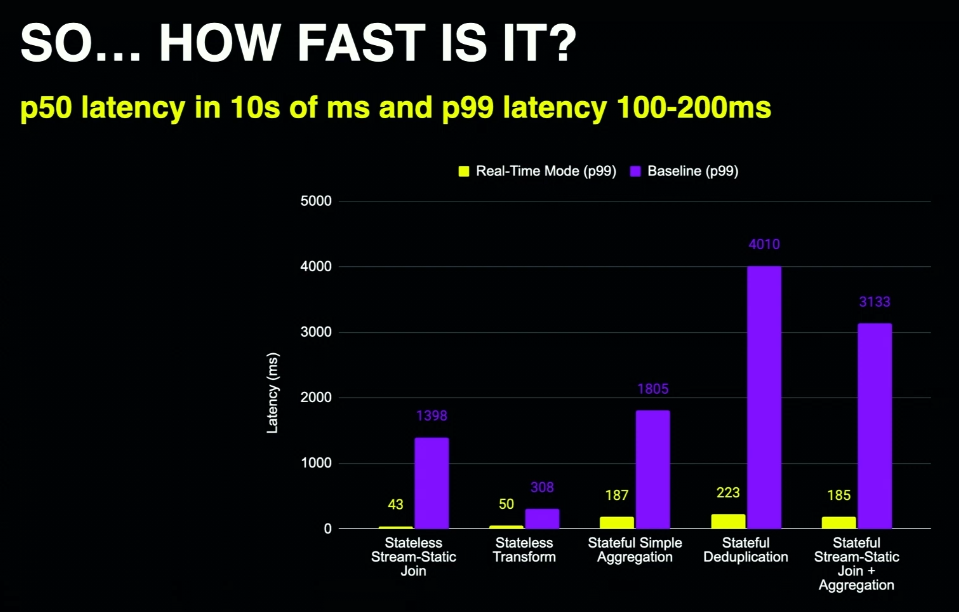
At this occasion, Ryan also recalls why p99 measure is important for latency-sensitive jobs as it represents the consistent latency of your processing layer. - Custom sources and sinks in PySpark. This feature will be also included in Apache Spark 4 and will let you, as a data engineer, to define custom sources and sinks in Python instead of writing hacky solutions.
- The final feature was a new API for arbitrary stateful processing, the transformWithState. Praveen recalled some of the limitations of the current solution relying on the (flat)MapGroupsWithState function:
 To mitigate them, Databricks and Apache Spark community were working on a new API, the transformWithState:
To mitigate them, Databricks and Apache Spark community were working on a new API, the transformWithState:
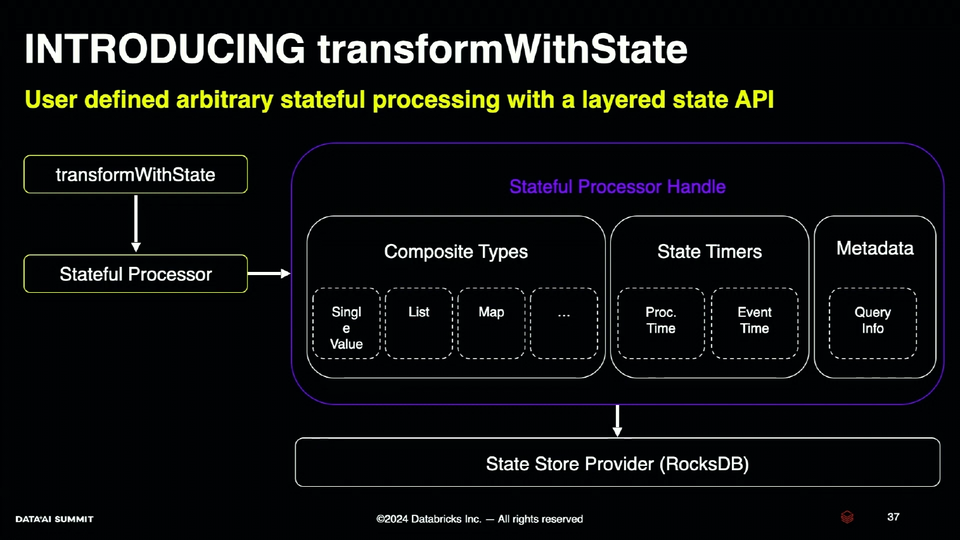
The new API brings the following:- flexible timers, with the possibility to set multiple times for a state group
- composite data types, such as ValueState, ListState, MapState. It gives more flexibility in the data modeling, and bring some optimizations, such as read-free append operation to the lists.
- operator chaining - combining multiple transformWithState is now possible inside a single streaming query
- ...and there are even more to come, including fine-grained state TTL, state initialization, schema evolution.
- Data ingestion into lakehouse, aka Streaming ETL. Delta Live Tables serverless shine here and perform better, especially when it comes to the scenario with failures, than Apache Spark Structured Streaming and Apache Flink jobs.
Processing a Trillion Rows Per Day with Delta Lake at Adobe
After Ashok's and Scott's talk about Protobuf, I didn't expect to see any JSON in my list. However, Yeshwanth Vijayakumar proved me wrong, and he was right! Even though JSON is often considered as an archaic solution when it comes to the data ingestion format, it's still there and its flexibility may be useful for various scenarios. It's the case of Adobe's multi-tenant architecture that Yeshwanth presented.
Notes from the talk:
- The first challenge Adobe's pipeline faces is data reconciliation. Multiple tenants and multiple data sources must be converted to a single format called Experience Data Model. It wouldn't be difficult if they all share the schema but it's not the case. Even worse, the schema evolves and within the same tenant, depending on the data source, can be different! All this at scale of 1-2 trillion of row changes every day.
- The architecture relies on a hot store for fresh data that should be available and processed further:
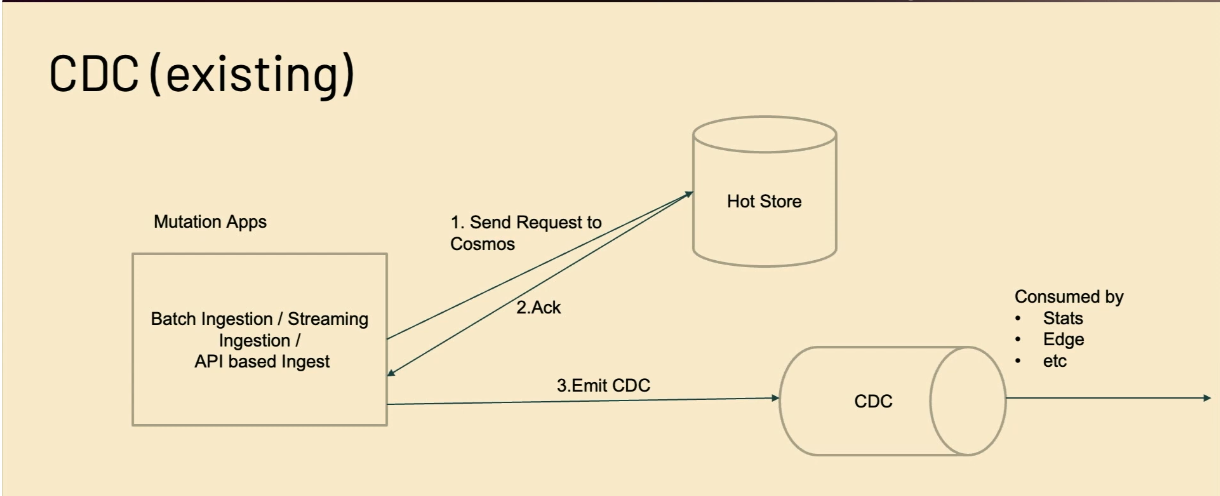
- Unfortunately, the hot store-based approach doesn't scale well with the batch workloads; Delta Lake is there to work with those batch workloads that are more demanding in resources than their streaming counterparts.
- CDC Dumper is a long-running Structured Streaming job that takes an input event and stores it to a staging Delta table. The table is append-only and partitioned by 15 minutes. It's like a buffer area to overcome any longer and costlier retention issues with Apache Kafka.
On top of the staging table are running multiple Spark processors that bring the staging data to the final tenant tables. The overall workflow is present below: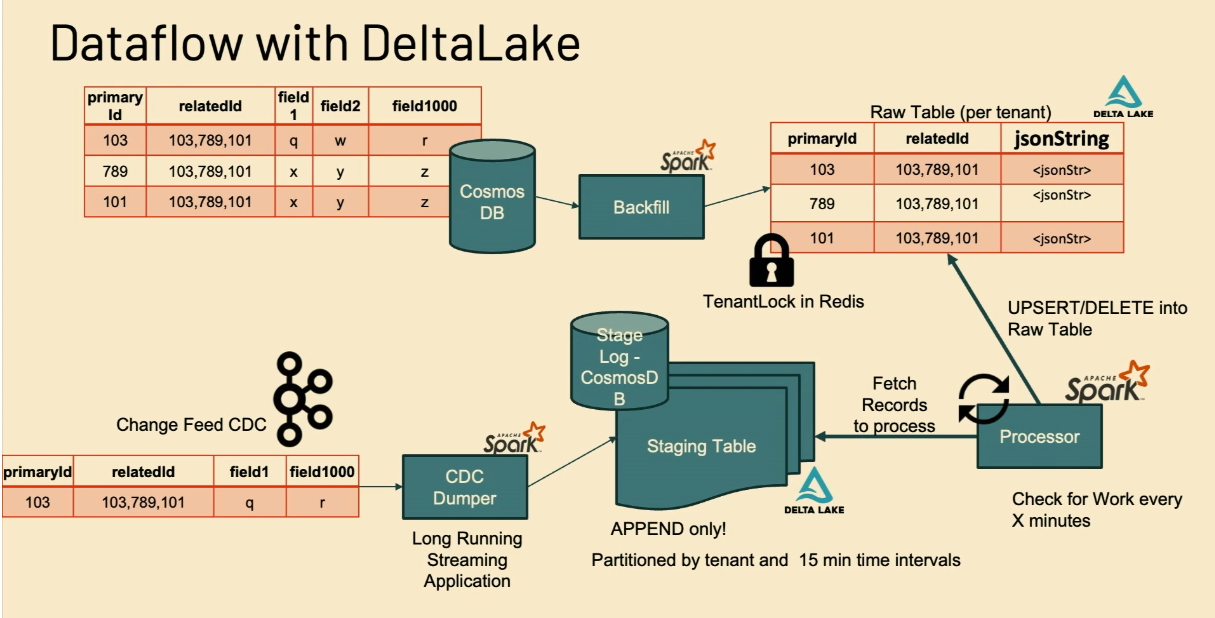
- Yeshwanth also dedicated one slide to the staging tables themselves. They bring several advantages to the architecture, including the aforementioned buffering, but also data quality assertions capabilities and conflict-less inserts, as they are configured in the append-only mode.

- Besides the staging table with the data, there is a stage log table with the ingestion progres recorded for each tenant. It's much more efficient than querying multiple factors for a bigger staging table. Writing to this stage log occurs at the same time as for staging thanks to a Two-Phase Commit protocol relying on the Delta Lake idempotent writers:

- Another interesting thing Yeshwanth and his team are doing is the global history table which is an augmented version of a regular Delta Lake table that simplifies querying and tracking per tenant:
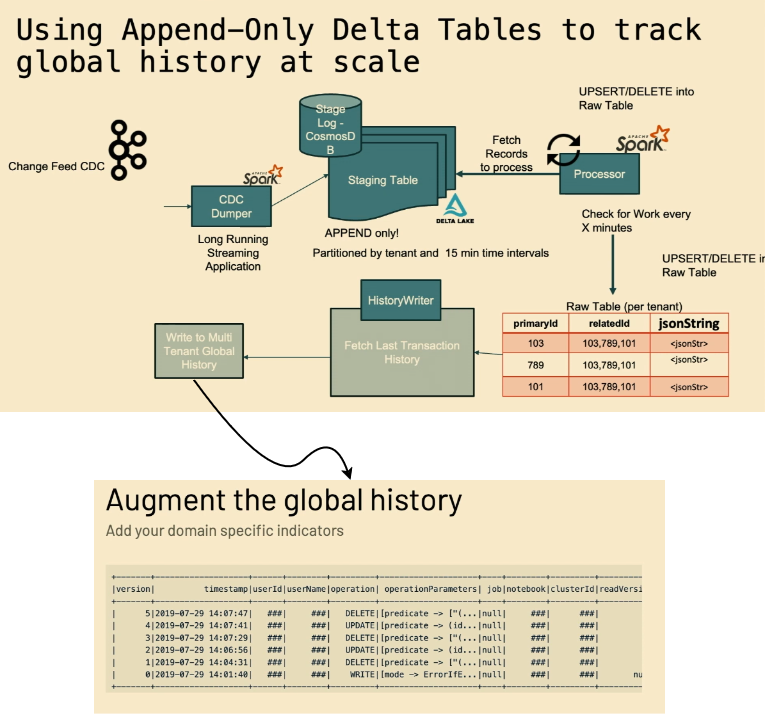
- There is also a Redis-based concurrency control mechanism that overcomes two challenges:

How Boeing Uses Streaming Data to Enhance the Flight Deck and OCC
I chose this talk out of pure curiosity to see the impact of streaming on the aviation industry. I was expecting some kind of low-level communication protocols and not easy to grasp stuff, but was positively surprised in the end! Will Jenden proved that it's possible to bring data intelligence with Apache Spark Structured Streaming even to that challenging environment as aviation!
Notes from the talk:
- An interesting term is the Reduce Taxi-Out (RETO) that defines operating with a single engine just before taking-off. It helps reduce the fuel consumption. The project Will was working on was a business intelligence tool for pilots to support them in making decision whether using RETO or not.
- The technical pipeline consists of combining real-time aircraft positions data with more static aeronautical data referential dataset and thanks to the arbitrary stateful processing, produce aggregated events:
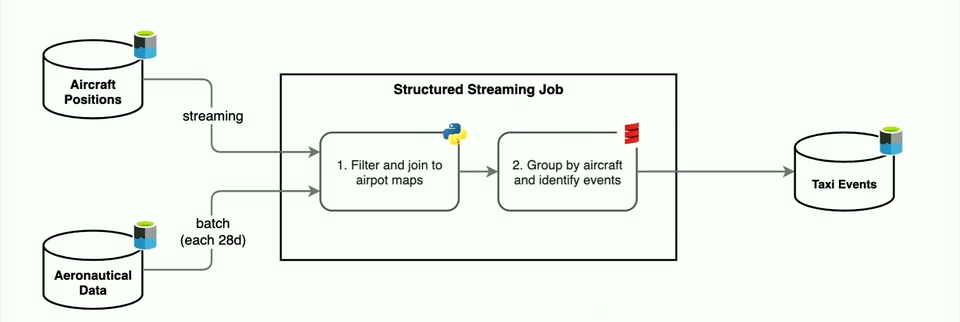
- In the end, an aggregated Taxi Event looks like in the screenshot below:

And the pilot can take more informed decision thanks to the UI retrieving the events from an API:
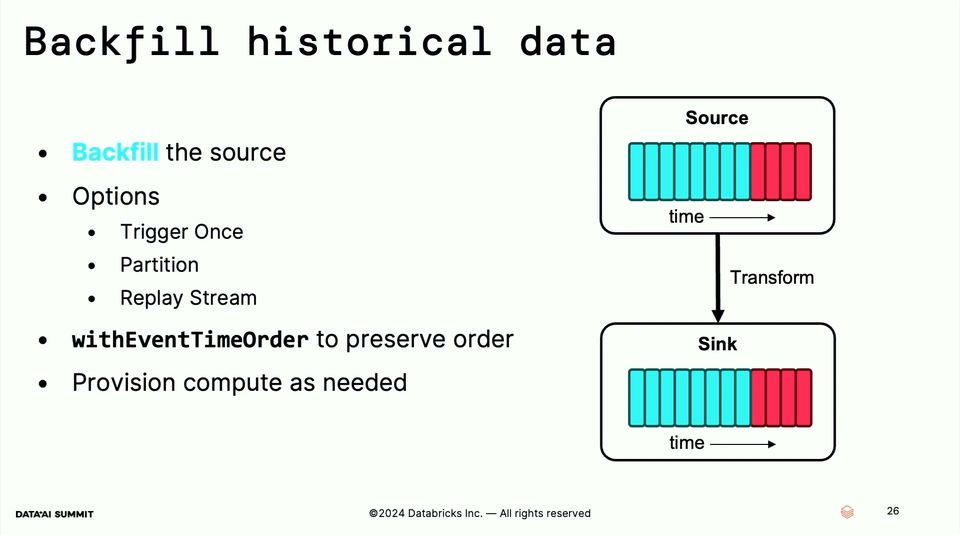
- If you think that was that simple, you are wrong. Historical data was also important to discover the seasonality and improve the algorithm. There are 3 possibilities:
- Trigger Once - expensive as whole, the dataset must fit into your cluster.
- Partitioned backfilling - not that easy to use day aggregates as the flights can start one day and end in the another.
- Replay stream - the problem here is the order. By backfilling past data, they would be put after the most recent data, or even literally ignored because of the watermark. To preserve order regardless when you wrote the commits, you can use the withEventTimeOrder option:
How to Use Delta Sharing for Streaming Data
That's another intriguing talk, as for me Delta Sharing has always been batch-friendly! Thankfully, I didn't miss the chance to learn from Matt Slack that it was a wrong assumption.
Notes from the talk:
- Matt started by explaining where Delta Sharing fits best when it comes to stream processing. His slide explains it better than my words:

It's worth noting that the achievable latency applies to the datasets located in the same region and on the same cloud provider. It will be slower otherwise. - How does Delta Sharing work in the context of Structured Streaming? Most steps are similar to the batch reading but there are some specific to the continuous character of streaming. First, the client needs to ask for a new version continuously and eventually make progress. The progress, hence the most recent processed version, is later persisted to the checkpoint location, exactly as would be the metadata of other data sources.
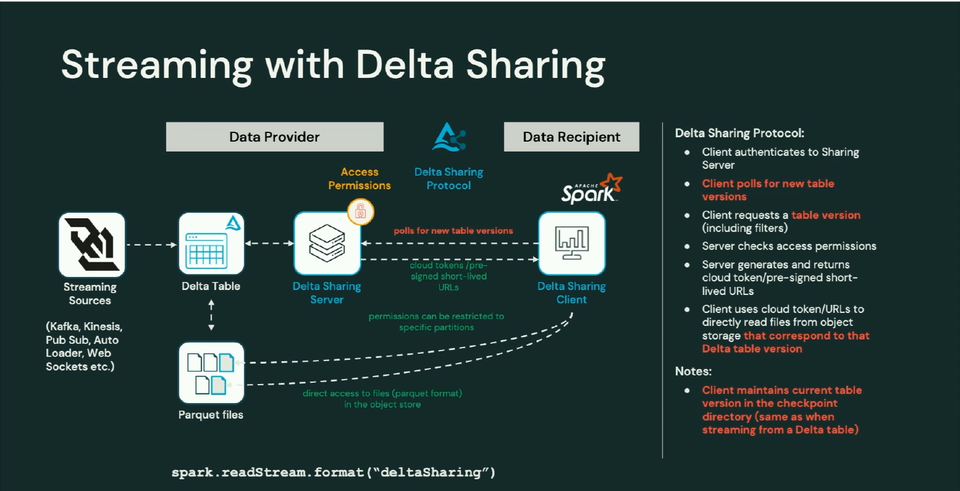
- An important point to remember is that Delta Sharing server is a shared resource and consequently, streaming clients have a built-in throttling mechanism; it's not the single factor impacting the latency:

Incremental Change Data Capture: A Data-Informed Journey
This year I picked two Change Data Capture (CDC) talks. I was a bit worried since the CDC has been there for a while but thankfully, it was not the case! In the first talk, Christina Taylor presented her journey throughout various CDC implementations on top of AWS and Databricks.
Notes from the talk:
- Version 0 was based on Database Migration Service and Databricks Autoloader. It was not the final version because of hard deployment, DMS limitations like for metadata changes such as renames, involuntary restarts due to the frozen migration jobs.
- Version 1 was based on Debezium and Delta Live Tables. This approach was not final either due to the following gotchas: deployment complexity, transaction lock (long running transactions were often blocking the replication slot), unnecessary captures (the targeted outcome was the final state of a row and not necessarily all the updates it has been through).
- Version 2 that mitigates the issues is an Apache Spark job with lakehouse federation on top of Unity Catalog.

How DLT Stretched CDC Capabilities and Kept ETL Limber at Hinge Health
A different Databricks-based solution for the Change Data Capture was presented by Alex Owen and Veeranagouda Mukkanagoudar.
Notes from the talk:
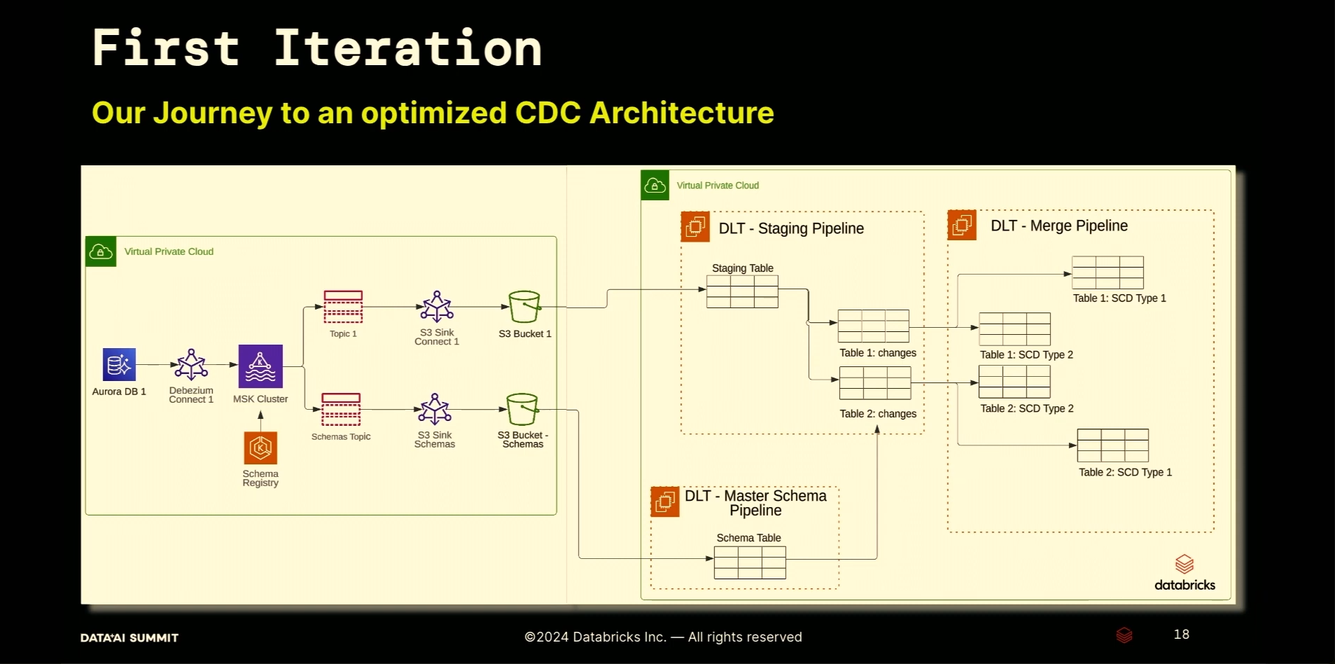
- The first version relied on an architecture combining Open Source world with the Databricks ecosystem. More specifically, Debezium were streaming changes from an Amazon Aurora database to the lakehouse living in Databricks.
- Pros of using Databricks mentioned by Veeranagouda were: a single platform for all data use cases (analytics, ML), support for streaming and batch, and more importantly, parameterized pipelines (a single pipeline definition that covers 35 data pipelines)
- Challenges with the version 1 were:
- Architectural complexity - there was one common staging table for all tables to replicate. Besides, the data was landing on S3 with an initial goal to reuse it for other use cases. The problem is, they never came.
- Reliability - due to the complexity, it was hard to debug and for example find a missing row in one of the tables.
- Cluster utilization - some tables were really small and having dedicates pipelines for them was not optimal due to the increased driver creation overhead.
- Cost - each table had its dedicated pipeline which greatly impacted the cost.
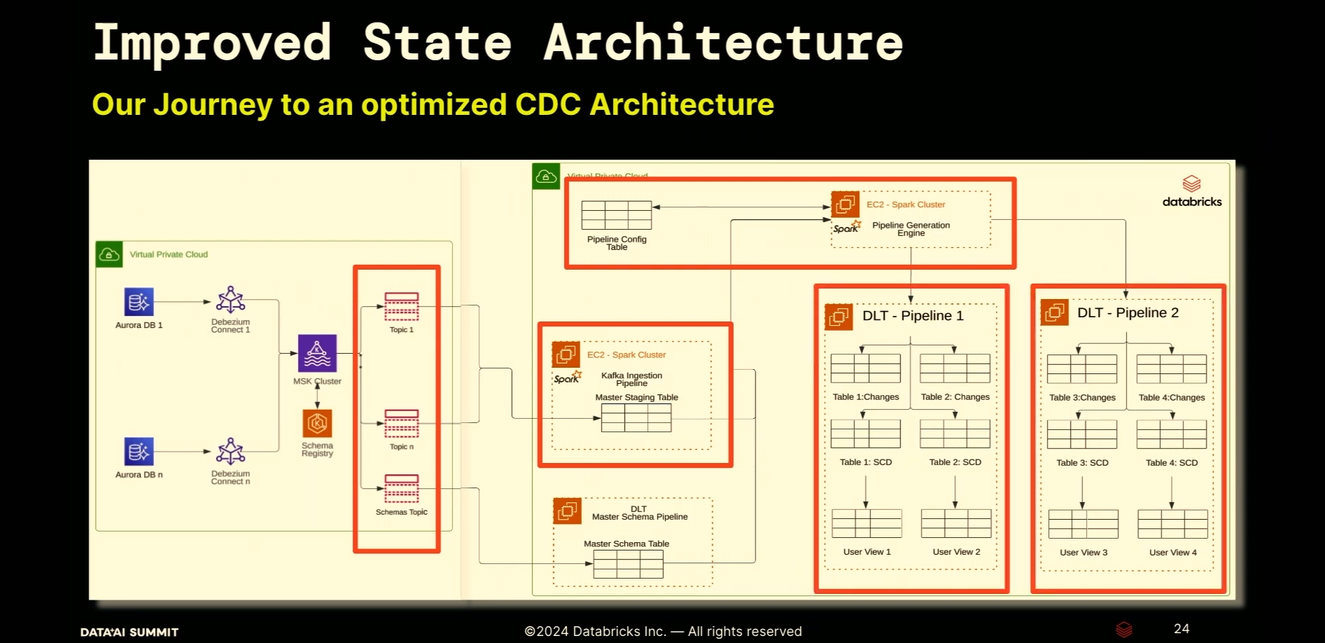
- The issues of the Version 1 were addressed in the next iteration, the Version 2:
- Architectural complexity - Delta Live Tables are reading now the data directly from Apache Kafka.
- Reliability - multiple staging tables were replaced by one Master Staging Table partitioned by table name and date. The date partitioning simplified cleanup operations due to the data retention a lot.
- Cluster utilization - even though there are still multiple DLT jobs, they are all managed by a single driver instance. Besides, the DLT jobs were templated and created dynamically thanks to the Schema Table you saw before:
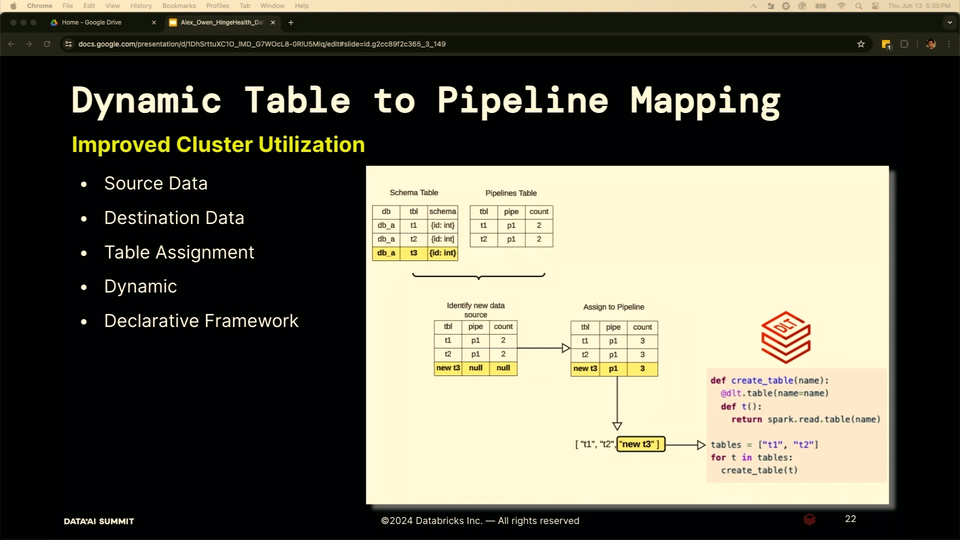
- Cost - removing S3 also helped reduce the cost as this layer was pretty expensive at querying.
Building Metrics Store with Incremental Processing
Slightly related to the Change Data Capture theme was also the last talk from my list. Hang Li shared what challenges she faced at Instacart while building a metrics store from incremental processing.
Notes from the talk:
- Hang identified three main challenges for building a business metrics system:
- Consistency - how to ensure lack of data duplication and guarantee a single source of truth?
- Scalability - how to mitigate the issue with static lookback windows that are used to compute the metrics. It increases the volume of data to process, thus the compute needs.
- Reliability - how to guarantee a better monitoring and code quality.
- Besides the challenges, Hang also shared the solutions:
- Consistency - a centralized Metrics Store system is the response to the problems here. It guarantees a single entrypoint for the metrics commonly used by other consumers.
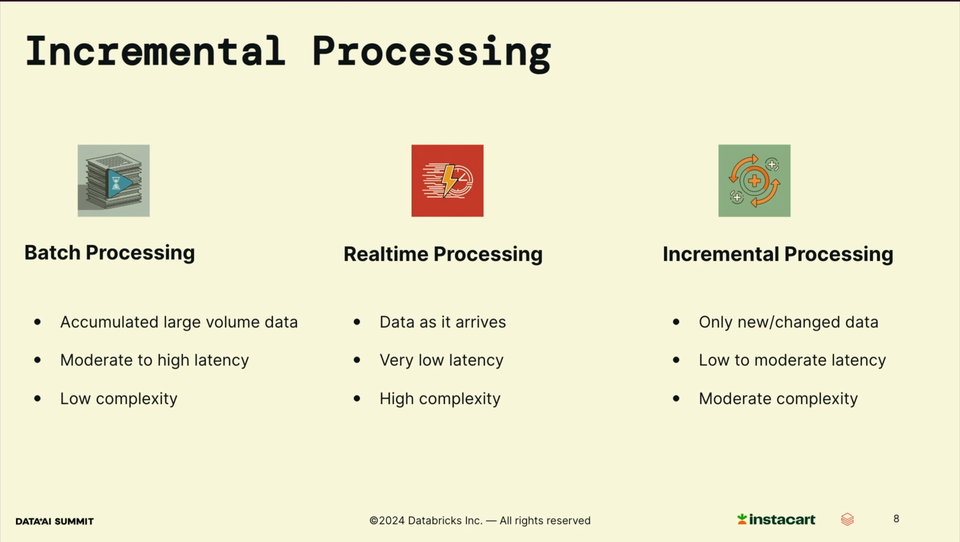
- Scalability - batch processing was clearly an issue here. A solution is incremental processing which lives between real-time and batch processing. Technically, the implementation may come from an Apache Spark Structured Streaming job, which is ideal for simple transformations. For more challenging ones, Change Data Feed seems better suited as it brings some benefits for stateful processing, such as identifying the windows to reprocess.

- Reliability - unit tests and appropriate monitoring layer were both solutions to the issues from this part.
That's all for the first retrospective. Thanks for reading. I know it was pretty long compared to what you can read usually here, but I'd say, that's the cost of wisdom 🤓 Stay tuned for the next retrospective, this time about Apache Spark!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- DAIS 2024: Unit tests - configuration and declaration
- DAIS 2024: Orchestrating and scoping assertions in Apache Spark Structured Streaming
- Data+AI Summit 2024 - Retrospective - Apache Spark
- DAIS 2024: Testing framework from the Dataflow model for Apache Spark Structured Streaming
- Data+AI Summit 2023, retrospective part 2