
Modern data platforms make our life easier. They abstract the compute layer with serverless capabilities, provide a built-in data governance framework, and simplify data democratization by hiding complex technical stuff to the end users. But despite this simplification, one thing remains on your - data engineering - end, the tests! In this blog post we're going to discover various testing patterns from the software engineering world, and try to see how to fit them to data engineering needs.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Software engineering test patterns
Let's start by recalling four main testing patterns in software engineering. The most popular one is probably the Test Pyramid that you should read bottom-up as: write a lot of unit tests as they're cheaper to create, maintain and run than integration tests and end-to-end tests.
An alternative to the Pyramid is Test Rectangle where unit and integration tests have the same importance. This pattern is useful when your system is critical (e.g. medical devices, financial system), or inherently complex (e.g. complex microservices environment, or a system depending on many external providers). Having integration tests that operate on higher abstractions than low-level functions detect any serious communication issues between the components.
Finally, there are two quite similar configurations, the Honeycomb, and Testing trophy. Both patterns rely on integration tests with fewer end-to-end and unit tests. The integration test domination makes both patterns suitable for complex microservices or highly integrated system environments. A single difference between them is the static code analysis tests present in The Testing Trophy pattern.
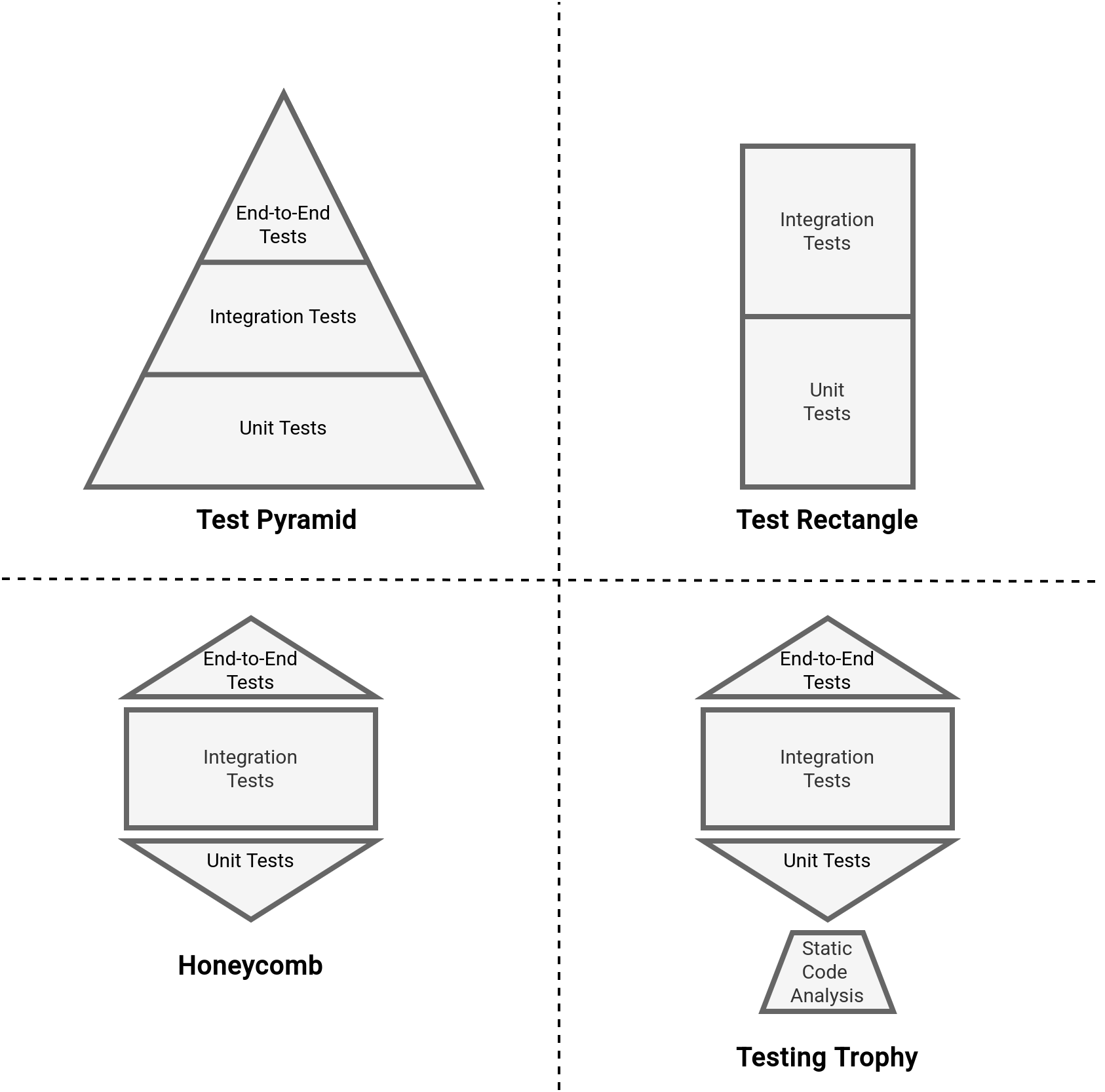
Long story short, you can see that a testing strategy consists of finding a balance between cheaper but possibly more biased unit tests, and more expensive but also more real integration tests. To understand it better, let's discover the genesis behind each of the test patterns:
- Test Pyramid. The idea as is was proposed by Mike Cohn in his book Succeeding with Agile (2009) as a response to the Ice cream cone antipattern where the dominant part of the testing layer were heavy and slow end-to-end tests, often performed manually. To address the slowness and expensiveness issues, Mike proposed the Test Pyramid where the dominant part were fast to run and relatively easy to maintain [compared to the end-to-end tests] unit tests. Besides, the Pyramid got an intermediary layer with the integration tests that are more complex than unit tests but provide more confidence to the testing outcome by automatically validating the interaction between components such as a web service, an external API, and a database.
- Test Rectangle. The concept evolved from the Test Pyramid in the microservices era. The systems were becoming more and more complex due to the interactions added between the microservices; from that moment, they were communicating not only with some external APIs or databases but also internally, between them. This kind of interaction was not possible to test with unit tests, at least not with the same confidence as it was given by integration tests. And for that confidence reason the pyramid transformed into a rectangle where both unit and integration tests have the same importance.
- Honeycomb. The Honeycomb pattern addresses the same complexity in the microservices world as the Test Rectangle. Put differently, it focuses on testing the interaction between various components for a particular microservice.
- Testing trophy. Although it looks similar to the Honeycomb pattern, the genesis doesn't come from the microservices. At the time (2021) his author, Kent C. Dodds, was working as a fronted engineer and realized that the best ROI on the written tests gave the integration tests: It doesn't matter if your component <A /> renders component <B /> with props c and d if component <B /> actually breaks if prop e is not supplied. So while having some unit tests to verify these pieces work in isolation isn't a bad thing, it doesn't do you any good if you don't also verify that they work together properly. And you'll find that by testing that they work together properly, you often don't need to bother testing them in isolation. (https://kentcdodds.com/blog/write-tests). The frontend also made another change compared to the Honeycomb pattern; the Testing Trophy model has a static code analysis component to improve the code quality.
Ice cream cone antipattern
In 2024 Piotr Stawirej gave a great talk on testing in software engineering. One of his points was to consider the Ice cream cone as a pattern but only for legacy software without proper testing strategy. You can find the presentation summary in the Infoshare 2024 retrospective.
What is a unit?
Unfortunately, at this moment we only know different configurations for a testing layer. But before we can choose one, we need to answer one important question - how to define units? Defining a unit is not simple. Some people consider it as a function or class, others think in terms of a unit of work, while others might have a completely different definition... To define the unit, let me quote Denis Doomen who gave a great talk at Infoshare 2024 about testing, and who also shared two - in my opinion - great definitions for a unit:

As you can see, nobody here talks about technical terms. The definition applies more to the scope that guarantees safe evolution of the code base. The safety is here measured as a guarantee to avoid regressions after deploying the modified code on production. Therefore, a valid unit is a function, class, but it can also be a more complex data processing logic.
Knowing that a unit can be something more than just a function, there is another point to understand. What to do with the dependencies? Most of the functions, classes, or more advanced logic, depend on other functions, classes, or logic. To answer this dilemma, in his blogs, Martin Fowler defines unit tests as solitary and sociable. The solitary ones work in isolation, i.e. the dependencies are provided with an expected content, for example via mocks. On another side, sociable tests work with live elements, i.e. there is no need to artificially create the content of the parameter functions or classes.
Whether a solitary and sociable test is still a unit test and not an integration test, the decision boils down to your unit definition. In our data engineering space, if you consider your complete data processing logic as a unit, you don't need to mock the filtering or mapping logic composing the job itself. After all, you want to validate the particular unit for real. Even though it makes you think about integration tests.
Integration vs. unit tests?
BTW, regarding the integration tests. Assuming a functional unit, such as a data processing job, can define a unit of work to be covered with a unit test, what to do with integration tests in your tests layer? Once again, the question is not new and some historical context will help us answer it. Martin Fowler recalls their origin in the Integration Tests article:

As you can learn here, integration tests addressed an issue of correctness between the code developed by different engineers (modern micro-services, does it ring the bell?). The integration tests, unlike the unit tests, are more high-level. It means they don't need the same detailed input parameters, e.g. a tested function might require a string parameter while for the integration test the same function would be part of a greater tested unit that might expect a different set of more high level attributes, such as a configuration file for a data processing job.
Besides the history, Martin Fowler also introduces another concept about integration test. He organizes them into narrow integration tests and broad integration tests. You can consider the narrow ones as the tests interacting with real external services, such as APIs, databases, cloud services. On the other hand, the broad integration tests are similar to the solitary unit tests introduced previously. So they run against mocks of these external services to focus on a specific behavior of your tested code.
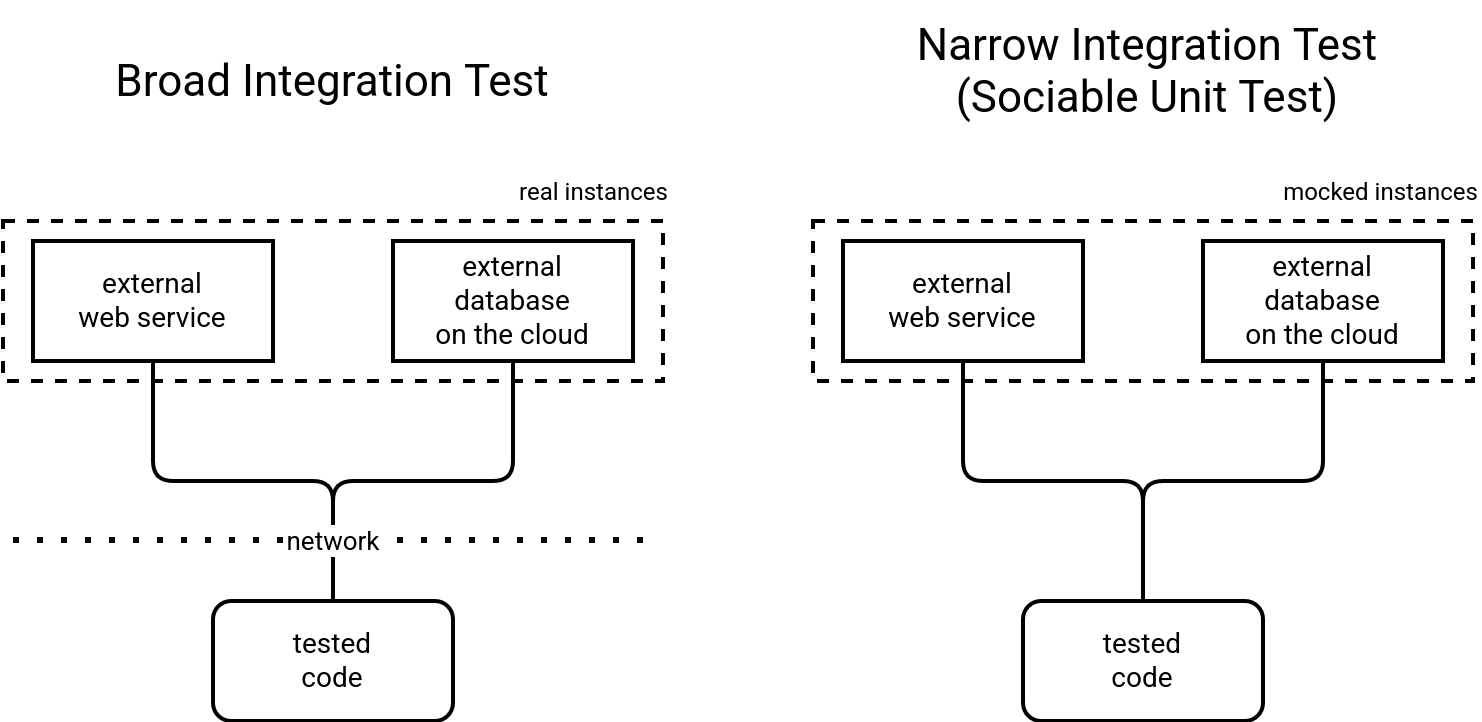
Therefore, if you assume the "tested code" from the schema above as our unit of work, the narrow integration tests can be considered as sociable unit tests. We can then conclude that the main difference between the unit and integration tests is the interaction with external services that for the integration tests will always be real instances. To make things more clear, Martin Fowler proposes to speak about system tests or end-to-end tests instead of broad integration tests. After all, they rely on the same real instances as broad integration tests.
Data engineering and unit test
Having written all this, we should now have a good foundation to see what it means to have unit tests in the data engineering projects. To understand it better, let's take a typical data engineering job represented in the next picture:
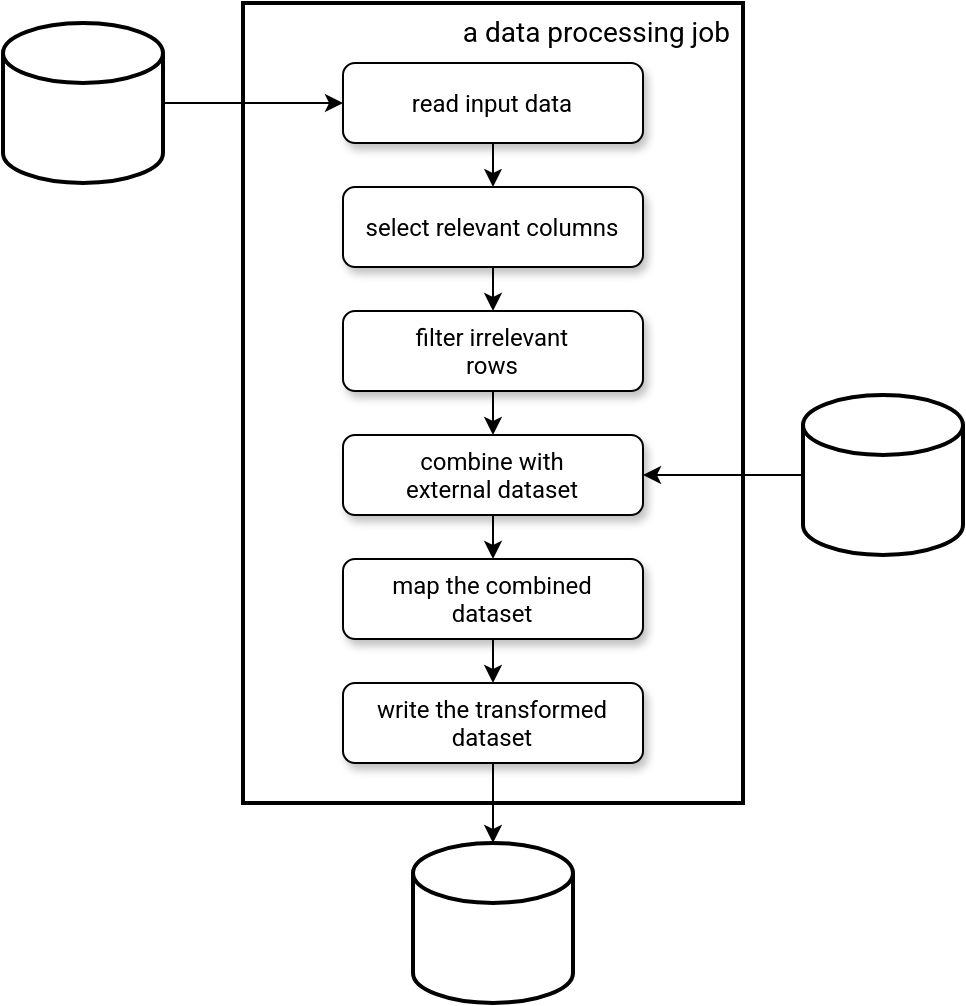
Our data engineering job can be viewed as a sequence of functions that either takes the output of the previous function, or a dataset as a parameter. Good news for us, data engineering frameworks (Apache Spark, Pandas, Polars, ...), they all come with their own dataset abstractions. As long as you work on those abstractions, you shouldn't be concerned by the solitary vs. sociable tests dilemma. You will likely prefer the sociable tests approach with real data abstractions that you can build from anything (memory, raw files, ...). The real input and output will only matter for your integration tests.
If we go back to the software engineering world, we should now define a unit. The answer is not simple because all the functions of our job, as well as the whole job, are valid unit candidates for unit tests. Therefore, it's important to decide which units to test:
- Individual functions only. The tests should be easier to set up and maintain. However, the tests will not spot any integration issues.
- Job only. The tests should be harder to set up and maintain because you might need to represent various possible scenarios in the input dataset, such as a valid/invalid row for each of the functions composing the block. On the other hand, this approach brings better coverage for integration issues.
- Individual functions and job. In this mixed approach, tests of the individual functions focus on covering as many different values as possible while the test of the job just verifies the correct interaction between them.
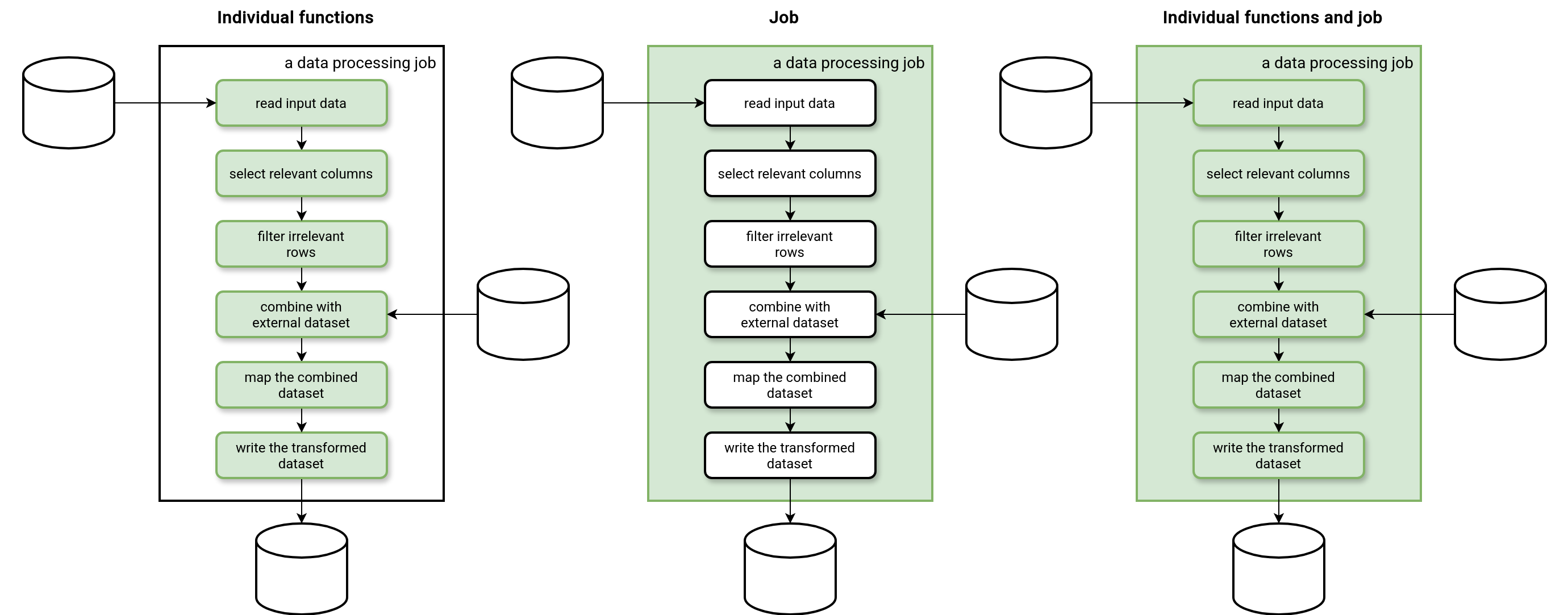
Remember one thing, though. Tests are an exclusive part of your code base that will require maintenance, adaptation, and evolution. Considering all this should help you answer the question what option will be the best for you.
Dataset biais
The big problem with all tests fully embedded to the code base is the dataset bias. Put differently, you write the unit tests with the dataset knowledge you have today but you never know whether this knowledge will reflect the reality of tomorrow. A pretty clear example here is an unexpected value in a column. Your unit tests may consider a field as being contained within a range, and suddenly, without anyone notifying you, the range might be extended by the data producer. Consequently, your unit tests will pass but your job will generate some data outside the expected range.
A valid solution to that issue is to apply the Audi-Write-Audit-Publish (AWAP) data quality pattern I'm sharing in Chapter 9 of my Data Engineering Design Patterns book. The idea is to run data validation steps before extracting and loading the dataset. It's currently better than any kind of tests because it validates live data whilst tests usually run only when you make some code changes.
AWAP != no problems
The AWAP pattern gives more confidence towards data exposed to your end users. However, it doesn't guarantee a 100% correctness due to a possibly misimplemented rule, or simply a forgotten one.
Code coverage is not enough
Two popular measures in software engineering to analyze unit tests coverage are lines and methods. Both analyze how well your tests cover the existing code base. Even though this measure also influences how good your data engineering project is, due to a slightly different nature of data applications, the code coverage metrics won't be enough. Unlike software engineering projects that operate on data coming from user interfaces and interactions, data engineering jobs operate on datasets that are more dynamic and variable. Consequently, knowing all possible values for a dataset is not possible.
For that reason an important layer in data projects is the data observability layer. It provides a valuable insight on how the data looks like. Good news, it's not only for the day-to-day monitoring purposes. You can also leverage the data observability layer to define more accurate unit tests and better control the dataset bias issue.
Addressing the bias issue brings a new concept for unit tests, the dataset coverage. Instead of focusing on the code lines covered with tests, dataset coverage focuses on the possible range of values covered in each test. Let me list a few examples here:
- Different date formats in your input dataset that you need to transform to the common one.
- A text-based transformation consisting of splitting values from two columns and combining them together. What if one of the columns doesn't have the value to split on? The transformation may generate a NULL. Is it an acceptable outcome?
- A simple mapping transformation from a finite set of possible values to another, e.g. an English-to-French translation of Mr to Monsieur, what if sometimes you have a Mister or M?
I shared a possible implementation of that dataset coverage in my Data+AI Summit 2024 repository. The implementation leverages a Mediator design pattern to record all values tested by your functions and next compares them against the data profile as close as possible to your production environment.

The solution consists of a central dataset wrapper that records all values used in the tests. Once all tests have run, the wrapper exposes the recorded values to a pytest.feature that compares them against a data profile. Whenever it detects some significant differences, it fails the whole test's suite execution.
Data test cone
If we know that the code coverage is not the single relevant measurement for tests in data systems, does it mean none of the software engineering test patterns should be used? Not at all, pick the one that addresses most of your issues. If your data is well structured and 80% of the issues can be caught at the development level, the Test Pyramid should be ok. If your issue is the connection to the external services, maybe you should think of the Honeycomb model. Or...
...or, if you cannot decide or have problem pretty much everywhere, Data test cone might be a better option:

In a nutshell - since we're going to explore this in other blog posts and also, in my recent Tests for data engineers on Databricks workshop - the Data test code:
- Allows some integration tests but mostly to validate tricky parts such as features available on your data platform exclusively
- Prefers unit tests over integration tests as they are cheaper to put in place and maintain. However, they are not enough due to dynamically changing data.
- Favors data tests that operate on real data and detects issues after code changes before they reach your end users.
The article went from presenting various test patterns coming from the software engineering world, to proposing a new and better adapted approach for data systems. If the blog post left you hungry, it's on purpose. A hungry reader is what I'm looking for as a blogger ;) Jokes aside, I couldn't write more and keep you focused. But I promise, next time it's going to be a bit more concrete.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about On tests in data systems here:
- The Practical Test Pyramid Testing of Microservices The Testing Trophy and Testing Classifications Write tests. Not too many. Mostly integration. What's the "unit" in unit testing and why is it not a class Integration Test
Related blog posts:
- Alerts, guards, and data engineering
- Agnostic data alerts with ydata-profiling
- Love and hate - Excel files and data engineers