
During my talk, I insisted a lot on the reprocessing part. Maybe because it's the less pleasant part to work with. After all, we all want to test new pipelines rather than reprocess the data because of some regressions in the code or any other errors. Despite that, it's important to know how Structured Streaming integrates with this data engineering task.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The post groups all data reprocessing parts from the previous series about checkpoint, state store, watermark, and output modes. As previously, I will precede the content with some outline to give you a better picture of its content.
Outline:
- How to restore from an arbitrary point?
- What are operational constraints?
- Can I reprocess the data with update mode?
- How state store is able to return all state groups?
- Does the reprocessing using processing time timeout will drop states after restarting the query?
- Does expired state is returned at recovery?
- How to get rid of the expired state from state store?
How to restore from an arbitrary point?
Checkpointed files are stored in the directories corresponding to the query executions (batchId in the source code). When Apache Spark needs to know the latest file for each type, it applies a simple algorithm of listing the files in the given directory, and reverse sorting them by the name. It takes later the first valid file to retrieve the information about the next query to run.
Thus, to restore the processing you simply need to find the checkpoint you want to start with and promote it to the most recent checkpoint. For example, you can do that by moving latest checkpoints into another directory, just for the backup (you can delete them once the new query works correctly).
Can I reprocess the data with update mode?
That was my major concern when I learned about the update output mode. As you know, the state is organized in versions and each version corresponds to micro-batch execution or epoch of continuous execution. The first thought I had was "if the update mode is used, then I can only restore the state updated in the given execution".
To check this out, I prepared a simple reader for the state generated by the code from What is the difference with SaveMode? section. The reader initializes HDFSBackedStateStoreProvider and the single requirement was to put it under org.apache.spark.sql.execution.streaming.state package since all package-related classes are package-private. I also captured the parameters for state configuration, and the whole initialization code looks like:
val sparkConfig = new SQLConf()
val provider = new HDFSBackedStateStoreProvider()
provider.init(
StateStoreId(
checkpointRootLocation = "file:///home/bartosz/workspace/spark-scala/src/test/resources/checkpoint-to-read/state", operatorId = 0L, partitionId = 0,
storeName = "default"
),
keySchema = StructType(Seq(StructField("value", LongType, false))),
valueSchema = StructType(Seq(
StructField("groupState", StructType(Seq(StructField("value", StringType, true))), true),
StructField("timeoutTimestamp", LongType, false)
)),
None,
storeConf = StateStoreConf(sparkConfig),
hadoopConf = new Configuration(true)
)
Just to recall you, the state for home/bartosz/workspace/spark-scala/src/test/resources/checkpoint-to-read/state directory evolved like in that picture:
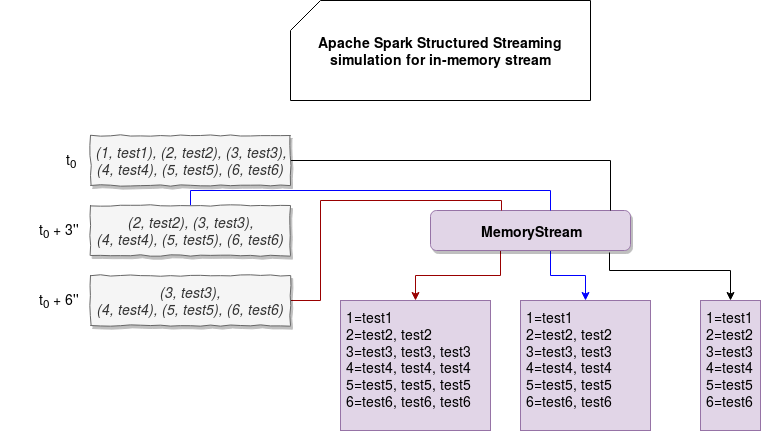
I started by exploration with latestIterator method. This method is responsible for getting the state related to the last version of state store. To my surprise, it returned all states!
provider.latestIterator().foreach(rowPair => {
val key = rowPair.key.getLong(0)
val value = rowPair.value.getString(0)
val timeout = rowPair.value.getLong(1)
println(s"${key}=${value} expires at ${new Date(timeout)}")
})
And the result was:
1= + test1 expires at Thu Aug 08 18:57:34 CEST 2019 2= + test2 + test2 expires at Thu Aug 08 18:57:36 CEST 2019 3= + test3 + test3 + test3 expires at Thu Aug 08 18:57:40 CEST 2019 4= + test4 + test4 + test4 expires at Thu Aug 08 18:57:40 CEST 2019 5= + test5 + test5 + test5 expires at Thu Aug 08 18:57:40 CEST 2019 6= + test6 + test6 + test6 expires at Thu Aug 08 18:57:40 CEST 2019
To confirm my hypothesis, I did the second check with getStore(version: Long), that way:
for (storeVersion <- 0 to 9) {
println(s"Store version ${storeVersion}")
provider.getStore(storeVersion).iterator()
.foreach(rowPair => {
val key = rowPair.key.getLong(0)
val value = rowPair.value.getString(0)
val timeout = rowPair.value.getLong(1)
println(s"${key}=${value} expires at ${new Date(timeout)}")
})
println("----------------------------------")
}
And here too, I saw the state change from one version to another, always including all not expired entries from prior versions:
Store version 0 ---------------------------------- Store version 1 1= + test1 expires at Thu Aug 08 18:57:34 CEST 2019 2= + test2 expires at Thu Aug 08 18:57:34 CEST 2019 3= + test3 expires at Thu Aug 08 18:57:34 CEST 2019 4= + test4 expires at Thu Aug 08 18:57:34 CEST 2019 5= + test5 expires at Thu Aug 08 18:57:34 CEST 2019 6= + test6 expires at Thu Aug 08 18:57:34 CEST 2019 ---------------------------------- Store version 2 1= + test1 expires at Thu Aug 08 18:57:34 CEST 2019 2= + test2 + test2 expires at Thu Aug 08 18:57:36 CEST 2019 3= + test3 + test3 expires at Thu Aug 08 18:57:36 CEST 2019 4= + test4 + test4 expires at Thu Aug 08 18:57:36 CEST 2019 5= + test5 + test5 expires at Thu Aug 08 18:57:36 CEST 2019 6= + test6 + test6 expires at Thu Aug 08 18:57:36 CEST 2019 ---------------------------------- Store version 3 1= + test1 expires at Thu Aug 08 18:57:34 CEST 2019 2= + test2 + test2 expires at Thu Aug 08 18:57:36 CEST 2019 3= + test3 + test3 expires at Thu Aug 08 18:57:36 CEST 2019 4= + test4 + test4 expires at Thu Aug 08 18:57:36 CEST 2019 5= + test5 + test5 expires at Thu Aug 08 18:57:36 CEST 2019 6= + test6 + test6 expires at Thu Aug 08 18:57:36 CEST 2019 ---------------------------------- Store version 4 1= + test1 expires at Thu Aug 08 18:57:34 CEST 2019 2= + test2 + test2 expires at Thu Aug 08 18:57:36 CEST 2019 3= + test3 + test3 + test3 expires at Thu Aug 08 18:57:40 CEST 2019 4= + test4 + test4 + test4 expires at Thu Aug 08 18:57:40 CEST 2019 5= + test5 + test5 + test5 expires at Thu Aug 08 18:57:40 CEST 2019 6= + test6 + test6 + test6 expires at Thu Aug 08 18:57:40 CEST 2019 ---------------------------------- Store version 5 1= + test1 expires at Thu Aug 08 18:57:34 CEST 2019 2= + test2 + test2 expires at Thu Aug 08 18:57:36 CEST 2019 3= + test3 + test3 + test3 expires at Thu Aug 08 18:57:40 CEST 2019 4= + test4 + test4 + test4 expires at Thu Aug 08 18:57:40 CEST 2019 5= + test5 + test5 + test5 expires at Thu Aug 08 18:57:40 CEST 2019 6= + test6 + test6 + test6 expires at Thu Aug 08 18:57:40 CEST 2019 ---------------------------------- Store version 6 1= + test1 expires at Thu Aug 08 18:57:34 CEST 2019 2= + test2 + test2 expires at Thu Aug 08 18:57:36 CEST 2019 3= + test3 + test3 + test3 expires at Thu Aug 08 18:57:40 CEST 2019 4= + test4 + test4 + test4 expires at Thu Aug 08 18:57:40 CEST 2019 5= + test5 + test5 + test5 expires at Thu Aug 08 18:57:40 CEST 2019 6= + test6 + test6 + test6 expires at Thu Aug 08 18:57:40 CEST 2019 ---------------------------------- Store version 7 1= + test1 expires at Thu Aug 08 18:57:34 CEST 2019 2= + test2 + test2 expires at Thu Aug 08 18:57:36 CEST 2019 3= + test3 + test3 + test3 expires at Thu Aug 08 18:57:40 CEST 2019 4= + test4 + test4 + test4 expires at Thu Aug 08 18:57:40 CEST 2019 5= + test5 + test5 + test5 expires at Thu Aug 08 18:57:40 CEST 2019 6= + test6 + test6 + test6 expires at Thu Aug 08 18:57:40 CEST 2019 ---------------------------------- Store version 8 1= + test1 expires at Thu Aug 08 18:57:34 CEST 2019 2= + test2 + test2 expires at Thu Aug 08 18:57:36 CEST 2019 3= + test3 + test3 + test3 expires at Thu Aug 08 18:57:40 CEST 2019 4= + test4 + test4 + test4 expires at Thu Aug 08 18:57:40 CEST 2019 5= + test5 + test5 + test5 expires at Thu Aug 08 18:57:40 CEST 2019 6= + test6 + test6 + test6 expires at Thu Aug 08 18:57:40 CEST 2019 ---------------------------------- Store version 9 1= + test1 expires at Thu Aug 08 18:57:34 CEST 2019 2= + test2 + test2 expires at Thu Aug 08 18:57:36 CEST 2019 3= + test3 + test3 + test3 expires at Thu Aug 08 18:57:40 CEST 2019 4= + test4 + test4 + test4 expires at Thu Aug 08 18:57:40 CEST 2019 5= + test5 + test5 + test5 expires at Thu Aug 08 18:57:40 CEST 2019 6= + test6 + test6 + test6 expires at Thu Aug 08 18:57:40 CEST 2019
The problem with the tested state was that none of them expired. To check what state groups are retrieved for the expired state, I changed a little bit the mapping function. I added shorter state duration and also increased the query execution time to make this state expire:
private val MappingExpirationFunc: (Long, Iterator[Row], GroupState[String]) => String = (key, values, state) => {
// ...
state.setTimeoutDuration(4000)
// ...
}
new Thread(new Runnable() {
override def run(): Unit = {
while (!query.isActive && !query.status.isTriggerActive) {}
// ...
Thread.sleep(120000L)
}
object StateReader {
def main(args: Array[String]): Unit = {
// ...
for (storeVersion <- 0 to 63) {
// …
}
provider.latestIterator().foreach(rowPair => {
val key = rowPair.key.getLong(0)
val value = rowPair.value.getString(0)
val timeout = rowPair.value.getLong(1)
println(s"${key}=${value} expires at ${timeout}")
})
After executing this method, I moved all the checkpoint directory to /src/test/resources/checkpoint-to-read-expired directory and executed state reader once again:
---------------------------------- Store version 4 1= + test1 expires at -1 2= + test2 + test2 expires at 1565423359548 3= + test3 + test3,test3 expires at 1565423359548 4= + test4 + test4,test4 expires at 1565423359548 5= + test5 + test5,test5 expires at 1565423359548 6= + test6 + test6,test6 expires at 1565423359548 ---------------------------------- Store version 62 1= + test1 expires at -1 2= + test2 + test2 expires at -1 3= + test3 + test3,test3 expires at -1 4= + test4 + test4,test4 expires at -1 5= + test5 + test5,test5 expires at -1 6= + test6 + test6,test6 expires at -1 ---------------------------------- Store version 63 1= + test1 expires at -1 2= + test2 + test2 expires at -1 3= + test3 + test3,test3 expires at -1 4= + test4 + test4,test4 expires at -1 5= + test5 + test5,test5 expires at -1 6= + test6 + test6,test6 expires at -1
This time I changed the printed results a little. Instead of returning the date, I preferred to return the timestamp, just to show you how Apache Spark retrieves expired state. Here too, you can see that all groups are returned - even if they've expired! And so also for the last version of state store. Does it mean that when you'll recover, you will also need to filter out the expired state?
The answer is no. Apache Spark filters the states with "-1" by itself. The "-1" is, by the way, a marker for "no timeout" information which happens when the state expires. But if the state expired, why it's still in the checkpointed files? It's simply because I didn't call the state's remove() method. When it's called, the framework adds a marker saying that the state was removed and at the recovery time, it will use this marker to remove the key from the in-memory map.
How state store is able to return all state groups?
Now you already know that Apache Spark will get all group states before the most recent state store version and return you only the ones that are still active or are about to expire in the next processing window. In this part, I would like to focus on the way Apache Spark retrieves all states.
When one state store version is not in the in-memory map, Apache Spark will first try to find it in the snapshot file. If there is nothing in the snapshot file, it will try to figure out the most recent snapshot file or in-memory data. In the end, it will complete such restored versions with delta files:
var lastAvailableVersion = version
var lastAvailableMap: Option[MapType] = None
while (lastAvailableMap.isEmpty) {
lastAvailableVersion -= 1
if (lastAvailableVersion <= 0) {
// Use an empty map for versions 0 or less.
lastAvailableMap = Some(new MapType)
} else {
lastAvailableMap =
synchronized { Option(loadedMaps.get(lastAvailableVersion)) }
.orElse(readSnapshotFile(lastAvailableVersion))
}
}
// Load all the deltas from the version after the last available one up to the target version.
// The last available version is the one with a full snapshot, so it doesn't need deltas.
val resultMap = new MapType(lastAvailableMap.get)
for (deltaVersion <- lastAvailableVersion + 1 to version) {
updateFromDeltaFile(deltaVersion, resultMap)
}
synchronized { putStateIntoStateCacheMap(version, resultMap) }
resultMap
}
That snippet comes from HDFSBackedStateStore's loadMap(version: Long) method. When the version doesn't exist in the local in-memory map, which is the case when the state is recovered in case of failure, it will first check whether there is an available snapshot. If yes, it will load all content from it and load new data from delta files created after the checkpoint, prior to the version that we want to recover.
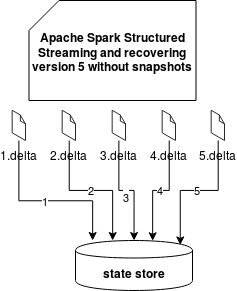
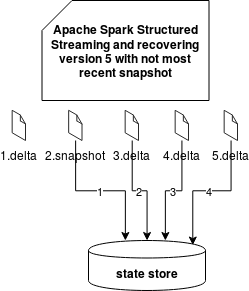
We can then have 3 situations:
- no snapshot file
- snapshot that is not the most recent version
- snapshot that is the most recent version
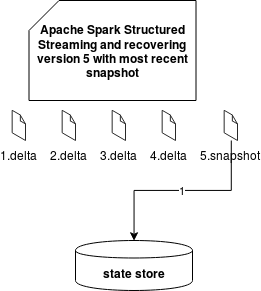
Only the last solution is quite clear because it simply loads the state. Two others have some interrogation points about the recovered state to the state store. As you know, every delta file stores not only updated values but also the removed ones. The difference between these 2 operations is that the update stores new value whereas the removal of a fixed marker of "-1". When Apache Spark retrieves a delta file, it checks that value and either puts the key to the in-memory state or removes it from there. And since the removal happens after the put (a simple case of an expired state), the entry is first put to the state store map and later removed from it.
That way, restoring a key1 from one of the 4 versions (key1, 30), (key1, 50), (key1, -1), (key1, 3) would return:
- version 1: (key1, 30) because of put(key1, 30)
- version 2: (key1, 50) because of put(key1, 30), put(key1, 50)
- version 3: None because of put(key1, 30), put(key1, 50), remove(key1)
- version 4: (key1, 3) because of put(key1, 30), put(key1, 50), remove(key1), put(key1, 3)
Does the reprocessing using processing time timeout will drop states after restarting the query?
When I was writing the part about watermark relationship to the mapGroupsWithState, that question came to my mind. After all, if event-time timeout is based on the events, state expiration will be safe, since coupled to the events that will remain unchanged even after restarting the past query. But what if the timeout is processing-time based, ie. based on the time that may vary a lot if the past state is reprocessed after 3 days?
In such a case, 2 things can happen. In the first, the restored state gets new events and thus, it's lifetime extended. For the second scenario, the restored state doesn't get new events in the next trigger window and, therefore, it will expire:
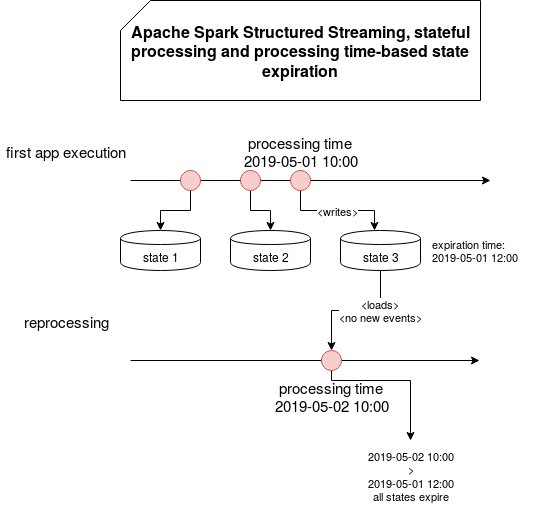
Why that behavior? Simply because the processing time state is coupled to real processing time, so if you restart the query from 2 days ago and all states are expiring 2 days ago, if there won't be any new events to extend them, they will simply expire because of the difference between the real-time (NOW) and state expiration time (NOW - 2 days).
And why the events in the next triggered window will extend the state? Simply because for processing time-based expiration time you define the duration which is added to the current processing time. Automatically old TTL will be overridden with the most recent one. It works also by the semantic of the expired state processing. The expired state is processed always after the alive state, ie. only if given state group doesn't receive new event in the current processing window, it will be considered as expired:
// FlatMapGroupsWithStateExec
// Generate a iterator that returns the rows grouped by the grouping function
// Note that this code ensures that the filtering for timeout occurs only after
// all the data has been processed. This is to ensure that the timeout information of all
// the keys with data is updated before they are processed for timeouts.
val outputIterator =
processor.processNewData(filteredIter) ++ processor.processTimedOutState()
Does expired state is returned at recovery?
No. Before I tell you why, let's start by a presentation of call sequence at state recovery:
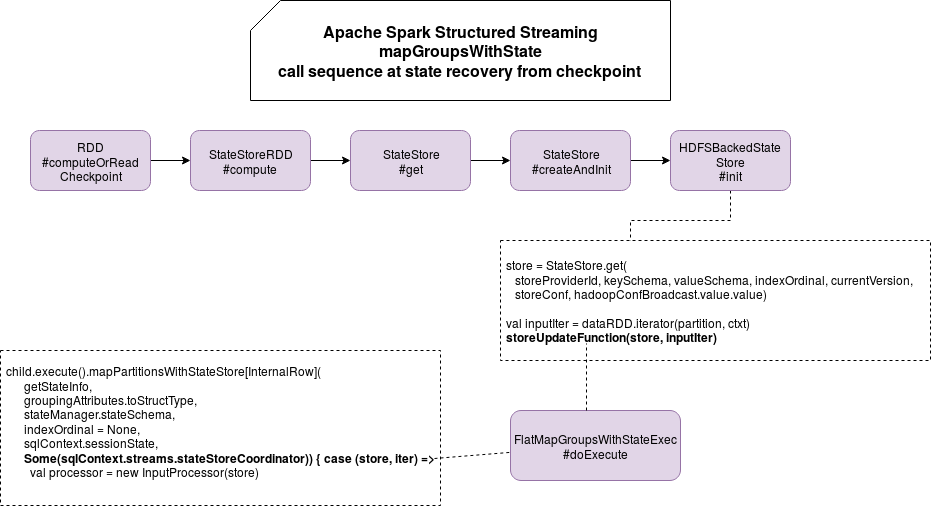
StateStoreRDD is responsible for figuring out the last version of the state. If you remember previous points, the recovery will retrieve all group states before it. However, all won't be returned to the group function and it's because of that snippet of FlatMapGroupsWithStateExec:
// If timeout is based on event time, then filter late data based on watermark
val filteredIter = watermarkPredicateForData match {
case Some(predicate) if timeoutConf == EventTimeTimeout =>
iter.filter(row => !predicate.eval(row))
case _ =>
iter
}
val outputIterator =
processor.processNewData(filteredIter) ++ processor.processTimedOutState()
What will happen at the recovery time? First, the mapping function will receive all up-to-date states. Later, it will process expired state but only the ones expired recently. How? To find the answer, we must go to processTimeOutState() function:
def processTimedOutState(): Iterator[InternalRow] = {
if (isTimeoutEnabled) {
val timeoutThreshold = timeoutConf match {
case ProcessingTimeTimeout => batchTimestampMs.get
case EventTimeTimeout => eventTimeWatermark.get
case _ =>
throw new IllegalStateException(
s"Cannot filter timed out keys for $timeoutConf")
}
val timingOutPairs = stateManager.getAllState(store).filter { state =>
state.timeoutTimestamp != NO_TIMESTAMP && state.timeoutTimestamp < timeoutThreshold
}
timingOutPairs.flatMap { stateData =>
callFunctionAndUpdateState(stateData, Iterator.empty, hasTimedOut = true)
}
} else Iterator.empty
}
Here you can see that Apache Spark will filter out the recovered states with the timestamp field is equal to NO_TIMESTAMP value, which is…-1! The same -1 that we've met in the Can I reprocess the data with update mode? part.
How to get rid of the expired state from state store?
The reason why I was retrieving the state without timeout (-1) was the mapGroupsWithState function and the lack of remove() call on the expired group state. If the explicit removal method is not invoked, Apache Spark won't automatically clean up the expired state from state store. If you carefully analyze the implementation of FlatMapGroupsWithStateExec operator, you'll see that there is no call on the methods of such type.
To confirm my hypothesis about removals, I added a breakpoint printing s"Removing key ${key.getLong(0)}" in HDFSBackedStateStore#remove(key: UnsafeRow) method:
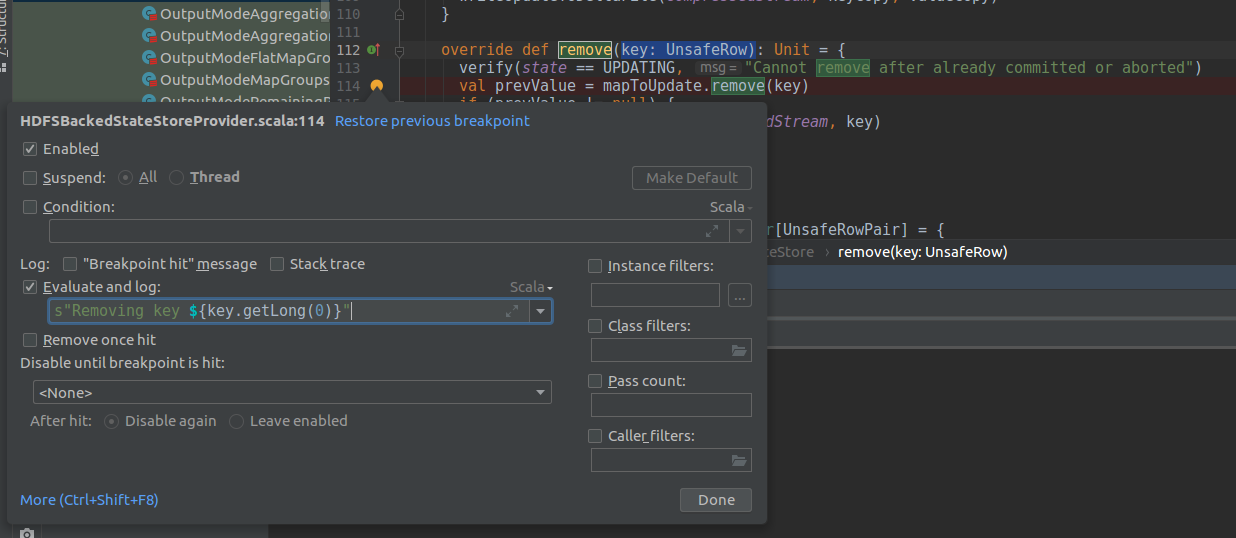
After executing my code example with long query execution and short-living state, I didn't see any "Removing key..." message.
But GroupState instance returned to our mapping function has a special method returning a flag indicating whether the state was removed or not, called hasRemoved. For the default implementation (GroupStateImpl), when the client calls remove() function, an internal removed field is passed to true and, therefore, the returned flag is so. Thanks to that FlatMapGroupsWithStateExec, once all groups processed, invokes this code for every state:
if (groupState.hasRemoved && groupState.getTimeoutTimestamp == NO_TIMESTAMP) {
stateManager.removeState(store, stateData.keyRow)
numUpdatedStateRows += 1
}
Hence, only explicit state cleaning is implemented in the function. But that's not true for all stateful operations. Some of them like streaming deduplication which removes keys older than the current watermark, or joins removing the old state from the store.
In this next snippet I'm using remove() function and as previously, I'll later read the persisted state version from the state store reader:
private val MappingExpirationFunc: (Long, Iterator[Row], GroupState[String]) => String = (key, values, state) => {
if (state.hasTimedOut) {
val stateBeforeClosing = state.get
state.remove()
s"${stateBeforeClosing}: timed-out"
} else {
state.setTimeoutDuration(4000)
val numbers = values.map(row => row.getAs[String]("name"))
val newState = s"${state.getOption.getOrElse("")} + ${numbers.mkString(",")}"
state.update(newState)
s"${key} => [${newState}]"
}
}
And with such a change, the persisted states didn't contain any expired group:
Store version 1 3= + test3 expires at 1565521732001 1= + test1 expires at 1565521732001 4= + test4 expires at 1565521732001 2= + test2 expires at 1565521732001 5= + test5 expires at 1565521732001 6= + test6 expires at 1565521732001 ---------------------------------- Store version 2 3= + test3 + test3,test3 expires at 1565521826502 2= + test2 + test2 expires at 1565521826502 5= " + test5 + test5,test5,test5,test5 expires at 1565521826502 6= ( + test6 + test6,test6,test6,test6,test6 expires at 1565521826502 4= + test4 + test4,test4,test4 expires at 1565521826502 ---------------------------------- Store version 3 ---------------------------------- Store version 4 ---------------------------------- ... Store version 14 ---------------------------------- Store version 15 ----------------------------------
What are operational constraints?
When you're restarting your query, you have some flexibility to modify several configuration entries. However, there are some of them which cannot be modified between query executions: spark.sql.shuffle.partitions, spark.sql.streaming.stateStore.providerClass, spark.sql.streaming.multipleWatermarkPolicy, spark.sql.streaming.flatMapGroupsWithState.stateFormatVersion and spark.sql.streaming.aggregation.stateFormatVersion. If you try to override them, Apache Spark will put back the values from the checkpointed offset files. You can check that behavior in OffsetSeqMetadata#setSessionConf(metadata: OffsetSeqMetadata, sessionConf: RuntimeConfig) method.
But the configuration entries are not a single constraint. The remaining ones are about:
- state schema changes - as you already know, Spark checkpoints state as a row, so it keeps information about the schema. Changing the schema is then not allowed because it will be unable to serialize/deserialize it. On the other hand, the mapping function can be modified.
- sources - a source cannot be changed since the information about it are checkpointed to the offset logs. To recall, you'll retrieve there the things like offsets to process, existent partitions and so forth. Thus, having a different source means automatically starts the query from scratch. However, it's possible to modify some configuration about the sources like rate.
- aggregation state - you can't modify the grouping keys since the query won't be able to reuse the state. The same concern is valid for joins and streaming deduplication queries.
- query changes - for map or filter you can add extra cases to filter or projections.
- sinks - here too the changes are limited and for instance, you can switch from file system to Kafka but not the opposite. The same rule concerns topics and output directories. The former ones can while the latter ones can't be modified.
As you can see, the checkpoint can be easily used to restore the query from an arbitrary point in time. However, it has some important operational constraints and you should be aware of them when you define your data reprocessing policy.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Reprocessing stateful data pipelines in Structured Streaming here:
Related blog posts:
- Extending state store in Structured Streaming - reprocessing and limits
- Extending state store in Structured Streaming - reading and writing state
- Why UnsafeRow.copy() for state persistence in the state store?
- Extending state store in Structured Streaming - introduction
- Extending data reprocessing period for arbitrary stateful processing applications
Reprocessing data is not always a pleasant task ? In today's post I show how #ApacheSpark #StructuredStreaming provides data reprocessing capabilities for an arbitrary stateful processing https://t.co/pvjQVAmG0g
— Bartosz Konieczny (@waitingforcode) November 16, 2019