
After checkpointing, it's time to start a new chapter of Spark Summit AI 2019 preparation posts. And in this new chapter I will describe the state store. It's the first of 3 articles about this important part of the stateful processing.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This first post covers the basics of state store. You'll learn here about its relationship with checkpoint location, impact on stateful processing and basic storage model.
- What is stateful processing?
- How to use arbitrary stateful processing?
- Where state is stored?
- What is stored?
- Do all keys are always written to state store?
- How long a state is kept?
- What is the relationship with checkpoint?
- What is the relationship between version and metadata checkpoint version?
What is stateful processing?
Stateful processing is an operation working on some state evolving in time. It means that the value of such computation will change with every new incoming event.
Even though stateful processing makes immediately thinking about sessions, it's not its single use case. You can also execute more general ideas like window-based aggregations (eg. count of visitors during the last 5 minutes).
How to use arbitrary stateful processing?
Arbitrary stateful operations can be executed from mapGroupsWithState or flatMapGroupsWithState methods. Both take as parameters the type of timeout, the state mapping function and the output mode of the function.
The first parameter, as explained before, defines the state expiration policy used in the stateful operation. Regarding the mapping method, it should take a key, a sequence of new events and an optionally existent state. Inside the function, you can play with the optional state and:
- terminate the state if its hasTimedOut returns true
- override the state with its update method
- change its expiration time with setTimeoutDuration or setTimeoutTimestamp method
The function is invoked only when a group has new events to integrate or when the state expired. In the latter case, the input rows are empty.
Where state is stored?
Checkpoint files are stored in memory (only few most recent queries) and in checkpoint files for fault-tolerance.
What is stored?
In the checkpointe location, state data is stored as LZ4-compressed files. The compressed objects are UnsafeRows representing the key, the value and the expiration time (if expiration time management enabled on *GroupsWithState function) for each state. You can see that in HDFSBackedStateStoreProvider#readSnapshotFile method responsible for restoring state from a snapshot file:
input = decompressStream(fm.open(fileToRead))
val keyRowBuffer = new Array[Byte](keySize)
ByteStreams.readFully(input, keyRowBuffer, 0, keySize)
val keyRow = new UnsafeRow(keySchema.fields.length)
keyRow.pointTo(keyRowBuffer, keySize)
val valueSize = input.readInt()
if (valueSize < 0) {
throw new IOException(
s"Error reading snapshot file $fileToRead of $this: value size cannot be $valueSize")
} else {
val valueRowBuffer = new Array[Byte](valueSize)
ByteStreams.readFully(input, valueRowBuffer, 0, valueSize)
val valueRow = new UnsafeRow(valueSchema.fields.length)
An important thing to notice is that the compression codec is not guaranteed to be compatible across different versions of Apache Spark:
* @note The wire protocol for this codec is not guaranteed to be compatible across versions
* of Spark. This is intended for use as an internal compression utility within a single Spark
* application.
*/
@DeveloperApi
class LZ4CompressionCodec(conf: SparkConf) extends CompressionCodec {
In-memory map contains not compressed version of these UnsafeRows.
Do all keys are always written to state store?
It depends on the output mode. *groupsWithState operation uses the updated state, so only changed and removed states are written to the map. You can see it here:
if (groupState.hasRemoved && groupState.getTimeoutTimestamp == NO_TIMESTAMP) {
stateManager.removeState(store, stateData.keyRow)
numUpdatedStateRows += 1
} else {
val currentTimeoutTimestamp = groupState.getTimeoutTimestamp
val hasTimeoutChanged = currentTimeoutTimestamp != stateData.timeoutTimestamp
val shouldWriteState = groupState.hasUpdated || groupState.hasRemoved || hasTimeoutChanged
if (shouldWriteState) {
val updatedStateObj = if (groupState.exists) groupState.get else null
stateManager.putState(store, stateData.keyRow, updatedStateObj, currentTimeoutTimestamp)
numUpdatedStateRows += 1
}
This method of FlatMapGroupsWithStateExec.InputProcessor is called when all the state changes are correctly processed. As you can see, it delegates all the changes to a class being an instance of StateManager which is a proxy class between the physical execution node and the state store implementation. But this update-only writing strategy doesn't mean that the state store contains only updated states. If one state doesn't receive any update during several queries, it's still present in the state store because it will probably expire in some nearer or further in the future. It's silently moved from one query into another.
How long a state is kept?
Exactly like for checkpoint files, state store retains only number of files specified in spark.sql.streaming.minBatchesToRetain configuration entry. Using the same property guarantees to keep the same data recovery semantics for metadata and state.
The cleaning task is executed by a maintenance process which first creates snapshot files and later cleans too old files (delta and snapshot). The frequency of the maintenance task is defined in spark.sql.streaming.stateStore.maintenanceInterval parameter and it defaults to 60 seconds.
I was wondering why cleaning the state was necessary and the single answer that came to my mind was about the performance. The storage in our days, especially the one on the cloud, is cheap and retaining a state for a long period of time would help to facilitate maintenance and data reprocessing. The problem is that state store often executes the method listing all files so automatically, more files we'll have, the more time this operation will take.
But the state is also kept in memory for faster access during the processing (checkpoint is mainly for fault-tolerance). The in memory state is persisted in util.TreeMap[Long, ConcurrentHashMap[UnsafeRow, UnsafeRow]](Ordering[Long].reverse) map where:
- the key is the number of the executed query
- the value is a map composed of: a state key (grouping key) and a state value with timeout timestamp (if configured)
The reverse ordering of the map is quite important because it helps to clean up too old versions. The number of versions to keep in the memory map is defined in spark.sql.streaming.maxBatchesToRetainInMemory property and everything happens that way, everytime a new version is created (= a new query is executed):
val size = loadedMaps.size()
if (size == numberOfVersionsToRetainInMemory) {
val versionIdForLastKey = loadedMaps.lastKey()
if (versionIdForLastKey > newVersion) {
// this is the only case which we can avoid putting, because new version will be placed to
// the last key and it should be evicted right away
return
} else if (versionIdForLastKey < newVersion) {
// this case needs removal of the last key before putting new one
loadedMaps.remove(versionIdForLastKey)
}
}
What is the relationship with checkpoint?
If the default state backed by an HDFS-compatible storage, is used, the state will be stored alongside checkpoint metadata files. The structure of that state store looks like:

The structure of state store shows clearly that the number of "substores" is equal to the number of partitions. And that's quite natural since all operations involving state are executed at partition-level.
Another thing to notice at this occasion is about the names of delta files. Each file starts with an auto-incremented number. The number corresponds to a state version. This version is coupled to the query and for the case of continuous execution it's equal to the current's epoch number. For the case of micro-batch execution, this number corresponds to the micro-batch execution number.
What is the relationship between version and metadata checkpoint version?
If you analyze the files generated by a structured streaming query execution, you'll see that the files with metadata starts with 0 whereas the ones belonging to state with 1:
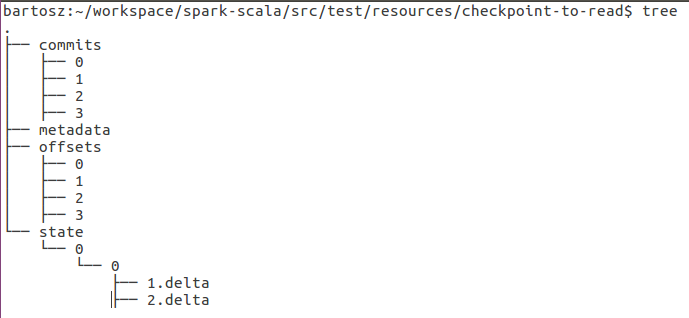
And that's the key to understand what will be the content of snapshot file:
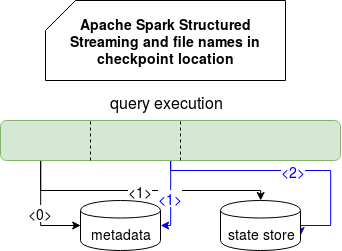
Every time a new micro-batch or an epoch begins, Apache Spark initializes the state by passing corresponding number to StateStoreProvider#getStore(version: Long). For the first execution, the version number will be 0 and an empty state will be used. It will be defined only after the first successful execution and for that specific case, the state will be written as version + 1 , hence it will be saved as the state that can be freely loaded in the next query execution. So, the store generated after the first execution will be 1. Now, the second query will be executed (number=1) and it will retrieve previously saved state from memory (generated by query=0 but saved in version=1). All changes made by this query will be saved as version=2 and the loop will continue like that.
Thus, after the first query execution you should see the checkpoint structure like in this output where the offsets were written for the first query (0) but the state for the next one (1):
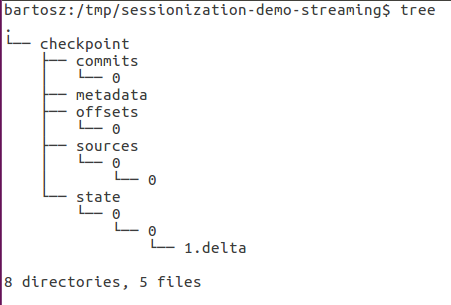
This post begins a new chapter for the Spark Summit 2019 posts. State store is a key element if you want to build stateful processing pipelines. It guarantees a state persistence for subsequent query executions in an in-memory local cache but also a fault-tolerance with checkpoint location. In the next posts about state store you'll learn some internal details about the fault-tolerance purpose and state lifecycle management.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Extending state store in Structured Streaming - reprocessing and limits
- Extending state store in Structured Streaming - reading and writing state
- Why UnsafeRow.copy() for state persistence in the state store?
- Extending state store in Structured Streaming - introduction
- Extending data reprocessing period for arbitrary stateful processing applications
It's time for the second part of #SparkAISummit follow-up posts. I start today with an introduction to #ApacheSpark #StructuredStreaming state store (FAQ-style again ) https://t.co/UMjfLssQOX
— Bartosz Konieczny (@waitingforcode) October 26, 2019