
To scale Spark applications automatically we need to enable dynamic resource allocation. But to make it work we need another feature called external shuffle service that will be covered here.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post explains external shuffle service in Apache Spark. Its first part focuses on purely theoretical aspect of it. The second one presents configuration option while the third one goes deeper and shows how this layer is implemented. The final section gives an example of the use.
Definition
At first glance we could mistakely think that external shuffle service is a distributed component of Apache Spark cluster responsible for the storage of shuffle blocks. But it's simpler than that. External shuffle service is in fact a proxy through which Spark executors fetch the blocks. Thus, its lifecycle is independent on the lifecycle of executor.
When enabled, the service is created on a worker node and every time when it exists there, newly created executor registers to it. During the registration process, detailed in further sections, the executor informs the service about the place on disk where are stored the files it creates. Thanks to this information the external shuffle service daemon is able to return these files to other executors during retrieval process.
External shuffle service presence also impacts files removal. In normal circumstances (no external shuffle service), when an executor is stopped, it automatically removes generated files. But when the service is enabled, the files aren't cleaned after the executor's shut down. The following schema illustrates in a big picture what happens on a worker node when external shuffle service is enabled:
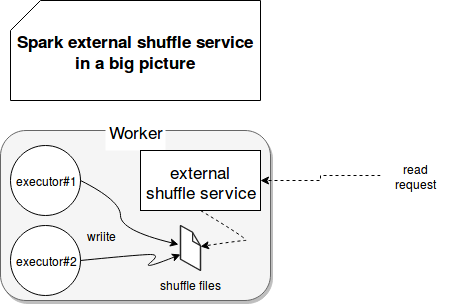
One big advantage of this service is reliability improvement. Even if one of executors goes down, its shuffled files aren't lost. Another advantage is the scalability because external shuffle service is required to run dynamic resource allocation in Spark.
Configuration
The properties describing external shuffle service begin with spark.shuffle.service prefix. We can distinguish among them:
- spark.shuffle.service.enabled - a boolean value defining if the service is enabled.
- spark.shuffle.service.port - defines the port on which the external shuffle service is running. Since the service is supposed to run on the same node as the executor, the host is not present in the configuration.
- spark.shuffle.service.index.cache.size - determines how big the cache can be. The cache in the case of external shuffle service is used to store index file information. It avoids to open/close these files every time a block is fetched. It's mainly used by sort-based shuffle data
Sort-based shuffle
It was the reaction of Spark engine to slow hash-based shuffle algorithm. Its sort-based version doesn't write each separate file for each reduce task from each mapper. Instead doing that, the sort-based shuffle writes a single file with sorted data and gives the information how to retrieve each partition's data to the executor. This information is defined as an index file indicating where each of partitions begins in the constructred data file. More detailed explaination was presented in the post about Shuffling in Spark.
External shuffle service internals
Executors communicate with external shuffle service through RPC protocol by sending the messages of 2 types: RegisterExecutor and OpenBlocks. The former one is used when the executor wants to register within its local shuffle server. The latter message is used during blocks fetch process. Both actions are operated by BlockManager via its shuffleClient: ShuffleClient field. Regarding the external shuffle service enabled configuration, the instance used in this field is either NettyBlockTransferService (no external shuffle) or org.apache.spark.network.shuffle.ExternalShuffleClient. Here we focus only on the second one.
During the register step, init(String appId) of shuffleClient is invoked by BlockManager. Here shuffleClient only setups some utilitary objects as the factory to create remote connections. Later BlockManager calls registerWithShuffleServer(String host, int port, String execId, ExecutorShuffleInfo executorInfo) that is very important becauses at this specific moment shuffle service discovers the storage topology of the executor (i.e. where shuffle files are stored):
val shuffleConfig = new ExecutorShuffleInfo( diskBlockManager.localDirs.map(_.toString), diskBlockManager.subDirsPerLocalDir, shuffleManager.getClass.getName )
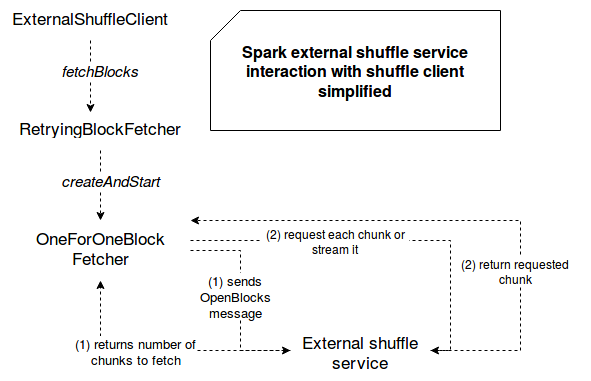
Blocks fetching operation involves more objects than the registration step. The request is generated in ExternalShuffleClient's fetchBlocks(String host, int port, String execId, String[] blockIds, BlockFetchingListener listener, TempFileManager tempFileManager) method and consists on the use of RetryingBlockFetcher instance that can retry to fetch blocks in case of failures. Physically the fetch process is realized by OneForOneBlockFetcher that sends the requests to retrieve needed blocks. The first step here consists on retrieving the pairs composed of (block id, number of chunks) for each of them. Later another requests are sent to get the content of these chunks.
Chunks retrieval is made in streaming mode or in batch mode (1 by 1). The former operation is realized by TransportClient's stream(String streamId, StreamCallback callback). It consists on sending a StreamRequest message to the instance of TransportRequestHandler. The handler informs the client about opening a TCP connection used to send required data. The transfer occurs throughout this connection and is not a part of a message sent batck by the handler. sends to the client needed data within a single TCP connection. Block retrieval for batch mode is made with TransportClient's fetchChunk(long streamId, int chunkIndex, ChunkReceivedCallback callback) method. As you can see, the method contains an index of chunk to retrieve. The handler returns to the client only this specific chunk, one chunk per request.
The following schema summarizes what happens when the blocks are read with external shuffle service enabled:
Example
To see what happens when external shuffle service, we'll run Spark 2.3.0 in standalone mode. Beside master and worker nodes we'll also need to start external shuffle service with ./start-shuffle-service.sh. And even if it doesn't show plenty how external shuffle service performs, it's enough to see some basic actions through learning tests:
val logAppender = InMemoryLogAppender.createLogAppender(Seq("shuffle service",
"Registered streamId",
"Received message ChunkFetchRequest", "Received request: OpenBlocks",
"Handling request to send map output"))
private val sparkSession: SparkSession = SparkSession.builder().appName("SaveMode test").master("spark://localhost:7077")
.config("spark.shuffle.service.enabled", true)
.getOrCreate()
"shuffle files" should "be read with external shuffle fetcher" in {
import sparkSession.implicits._
val numbers = (1 to 100).toDF("nr").repartition(10).repartition(15)
// Only to trigger the computation
numbers.collect()
val classWithMessage = logAppender.messages
.groupBy(logMessage => logMessage.loggingClass)
.map(groupClassNameWithMessages => (groupClassNameWithMessages._1,
groupClassNameWithMessages._2.map(logMessage => logMessage.message)))
val blockManagerMessage = classWithMessage("org.apache.spark.storage.BlockManager")
// Block manager controls if the files can be removed after stopping the executor
// It also defines from where shuffle files will be fetched. Throughout below message we
// can see that the fetch will occur from external shuffle service
blockManagerMessage should have size 1
blockManagerMessage(0) shouldEqual "external shuffle service port = 7337"
// In such case we can only see the activity of below classes and exchanges. The executors
// aren't registered with external shuffle server in standalone mode because of this check from
// BlockManager class: if (externalShuffleServiceEnabled && !blockManagerId.isDriver) {
// registerWithExternalShuffleServer()
// }
// So we check the existence of fetch messages
val nettyBlockRpcServerMessages = classWithMessage("org.apache.spark.network.netty.NettyBlockRpcServer")
val openBlocksMessagePresent = nettyBlockRpcServerMessages.find(_.contains("Received request: OpenBlocks"))
openBlocksMessagePresent.nonEmpty shouldBe true
val messageDecoderMessages = classWithMessage("org.apache.spark.network.protocol.MessageDecoder")
val fetchChunkRequestPresent = messageDecoderMessages.find(_.contains("ChunkFetchRequest: ChunkFetchRequest{streamChunkId"))
fetchChunkRequestPresent.nonEmpty shouldBe true
}
At first glance when I first encounter external shuffle service concept I considered it as a remote service managing shuffle files. However after some reading we can learn that it's not the case and this service is located on every worker, back to executor(s) belonging to different applications. In fact, external shuffle service can be summarized to a proxy that fetches and provides block files. It doesn't duplicate them. Instead it only knows where they're stored by each of node's executors.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about External shuffle service in Apache Spark here:
Related blog posts:
- Shuffle in PySpark
- Radix and Tim sort
- Shuffle configuration demystified - part 2
- Shuffle configuration demystified - part 1
- Shuffle reading in Apache Spark SQL - wrapping iterators and beyond
In another today's post some notes about #ApacheSpark external shuffle service: https://t.co/PiJQ9qN2oX pic.twitter.com/GuIEbgr9eY
— bardev (@waitingforcode) July 7, 2018