
If you are a newcomer in the distributed world, someone certainly told you that shuffle is bad and will slow down your processing. But what does it mean? What happens when this infamous shuffle exists in your code? In this article you should find some answers for the shuffle in Apache Spark.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
To illustrate the logic behind the shuffle, I will use an example of a group by key operation followed by a mapping function. In the first section, you will learn about the writing part. In the second one, you will see what happens on the reader's side when the shuffle files are demanded.
Shuffle - writing side
The first important part on the writing side is the shuffle stage detection in DAGScheduler. To recall, this class is involved in creating the initial Directed Acyclic Graph for the submitted Apache Spark application. It's later divided into jobs, stages and tasks, and all those parts are sent to the resource manager for the physical execution.
DAGScheduler has a method called getShuffleDependencies(RDD) where it will retrieve all parent shuffle dependencies for given RDD. How are these dependencies found? In the physical plan, the shuffle nodes are represented by ShuffleExchangeExec and inside it, you can find a field called shuffleDependency. It holds a ShuffleDependency class involved in the shuffle stages detection at the DAGScheduler level:
private def getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
getShuffleDependencies(rdd).map { shuffleDep =>
getOrCreateShuffleMapStage(shuffleDep, firstJobId)
}.toList
}
private[scheduler] def getShuffleDependencies(
rdd: RDD[_]): HashSet[ShuffleDependency[_, _, _]] = {
waitingForVisit += rdd
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.remove(0)
if (!visited(toVisit)) {
visited += toVisit
toVisit.dependencies.foreach {
case shuffleDep: ShuffleDependency[_, _, _] =>
parents += shuffleDep
case dependency =>
waitingForVisit.prepend(dependency.rdd)
}
}
}
parents
}
The ShuffleDependency instance is created in the ShuffleExchangeExec as ShuffleDependency[Int, InternalRow, InternalRow] where the Int is the partition number, the first InternalRow is the corresponding row and the last one the combined rows after the shuffle. The partition here is the after-shuffle partition number, so the reader's partition that will need the row. And it's computed from a partitioner that can be one of RoundRobinPartitioning, HashPartitioning, RangePartitioning or SinglePartition. For the group by key operation, the partitioner will be the hash-based one and the partition will be computed from the modulo-based hash algorithm:
case h: HashPartitioning =>
val projection = UnsafeProjection.create(h.partitionIdExpression :: Nil, outputAttributes)
row => projection(row).getInt(0)
def partitionIdExpression: Expression = Pmod(new Murmur3Hash(expressions), Literal(numPartitions))
Apart from this RDD construction logic, ShuffleDependency also includes an instance of ShuffleWriterProcessor and it's the class responsible for shuffle generation when the tasks (ShuffleMapTask class) of the shuffle stage are executed:
override def runTask(context: TaskContext): MapStatus = {
// ...
val rddAndDep = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])]( // ...
val rdd = rddAndDep._1
val dep = rddAndDep._2
dep.shuffleWriterProcessor.write(rdd, dep, mapId, context, partition)
}
// ShuffleWriteProcessor
def write(
rdd: RDD[_],
dep: ShuffleDependency[_, _, _],
mapId: Long,
context: TaskContext,
partition: Partition): MapStatus = {
var writer: ShuffleWriter[Any, Any] = null
// ...
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](
dep.shuffleHandle,
mapId,
context,
createMetricsReporter(context))
writer.write(
rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
As you can see, the shuffle writer retrieves the partition stored in the ShuffleDependency and applies a write method. The physical writing is delegated to the specific shuffle writer, which creates shuffle files in the format like:
shuffle_${shuffle id}_${map id}_${reduce id}
It's enough to discover how the shuffle happens on the reader's side. I will complete this information next year with a complementary post explaining different shuffle writers.
Shuffle - reading side
Let's see now what happens on the reader side. But before looking at the code, let's see the files generated by the shuffle writer:
. |-- 09 |-- 0a |-- 0b |-- 0c | `-- shuffle_0_0_0.data |-- 0d | `-- shuffle_0_3_0.index |-- 0e |-- 0f | `-- shuffle_0_1_0.index |-- 11 |-- 15 | `-- shuffle_0_1_0.data |-- 21 |-- 29 | `-- shuffle_0_3_0.data |-- 30 | `-- shuffle_0_0_0.index |-- 32 | `-- shuffle_0_2_0.index |-- 33 |-- 36 | `-- shuffle_0_2_0.data |-- 3b `-- 3e
As you can see, every "data" file, so the one storing the rows to fetch by the reducer at the reading stage, has a corresponding "index" file. Here, the BypassMergeSortShuffleWriter generated the output, but as announced, you will learn in another post whether this is different for other writers.
On the reader's side, the DAGScheduler executes the ShuffledRDD holding the ShuffleDependency introduced in the previous section. When it happens, the compute(split: Partition, context: TaskContext) method will return all records that should be returned for the Partition from the signature. And that's where the shuffle is, so the data transfers across the network (so far it remains local!). The compute method will create a ShuffleReader instance that will be responsible, through its read() method, to return an iterator storing all rows that are set for the specific reducer's:
reader.read().asInstanceOf[Iterator[Product2[Int, InternalRow]]].map(_._2)
Here too, you will discover a little bit more details about shuffle readers in one of the next blog posts and that's why, I will focus here on another aspect, ie. how the reader knows what files it should fetch? It's possible thanks to the MapOutputTracker that is aware of the created shuffle files. Before creating the shuffle files reader, the tracker is called to retrieve all shuffle locations for the given shuffle id:
override def getReader[K, C](
handle: ShuffleHandle,
startPartition: Int,
endPartition: Int,
context: TaskContext,
metrics: ShuffleReadMetricsReporter): ShuffleReader[K, C] = {
val blocksByAddress = SparkEnv.get.mapOutputTracker.getMapSizesByExecutorId(
handle.shuffleId, startPartition, endPartition)
new BlockStoreShuffleReader(
handle.asInstanceOf[BaseShuffleHandle[K, _, C]], blocksByAddress, context, metrics,
shouldBatchFetch = canUseBatchFetch(startPartition, endPartition, context))
}
The blocksByAddress are later used by the ShuffleBlockFetcherIterator to build FetchRequest instances:
/**
* A request to fetch blocks from a remote BlockManager.
* @param address remote BlockManager to fetch from.
* @param blocks Sequence of the information for blocks to fetch from the same address.
*/
case class FetchRequest(address: BlockManagerId, blocks: Seq[FetchBlockInfo]) {
val size = blocks.map(_.size).sum
}
And these requests will later fetch shuffle blocks from the executors, inside the fetchUpToMaxBytes():
// Process any regular fetch requests if possible.
while (isRemoteBlockFetchable(fetchRequests)) {
val request = fetchRequests.dequeue()
val remoteAddress = request.address
if (isRemoteAddressMaxedOut(remoteAddress, request)) {
logDebug(s"Deferring fetch request for $remoteAddress with ${request.blocks.size} blocks")
val defReqQueue = deferredFetchRequests.getOrElse(remoteAddress, new Queue[FetchRequest]())
defReqQueue.enqueue(request)
deferredFetchRequests(remoteAddress) = defReqQueue
} else {
send(remoteAddress, request)
}
}
If you want a quick summary of the above and low-level explanation, check the schema below:
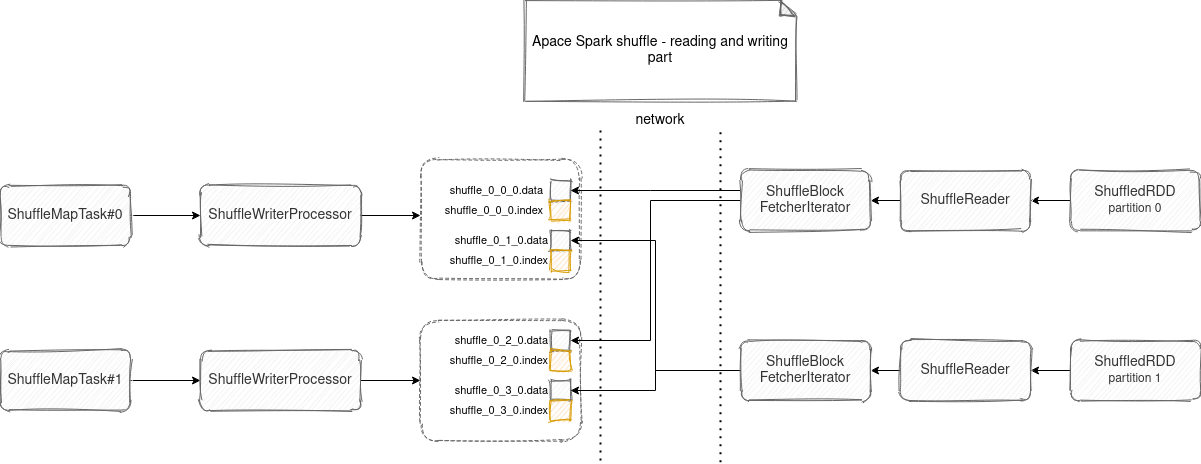
Shuffle is one of the trickiest components of Apache Spark. Maybe not from the understanding point of view because - I hope -you understood it better thanks to this blog post. But it's a building block for many data processing applications, one of the potential performance problems, and also one of the components making elastic scaling more complicated, for example, with dynamic resource allocation feature or Kubernetes scheduler.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Shuffle in PySpark
- Radix and Tim sort
- Shuffle configuration demystified - part 2
- Shuffle configuration demystified - part 1
- Shuffle reading in Apache Spark SQL - wrapping iterators and beyond
I wrote my first blog post about #ApacheSpark shuffle 3 years ago ? But it was quite a high-level overview. In the new blog post, you can see the first of more low-level presentations.
— Bartosz Konieczny (@waitingforcode) December 5, 2020
? https://t.co/kzMWksZsmt