
It's the second summary blog post after the Let's celebrate - the 600th post is coming one published last year. As previously, it's time to summarize last year and share my plans for 2021.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The idea is very simple - summarize what happened last year, share my blogging plans for 2021 and wish you all the best for 2021! Well, I can start by the last point and wish you a great and healthy year, with a lot of exciting data projects.
Blog posts
Let's begin with the 104 blog posts published in 2020. Once again, the most popular category was Apache Spark SQL with 27 articles. It's 5 less than last year because some other categories got more focus: Apache Spark Structured Streaming (20, +1), Apache Kafka (11, +11!), Apache Spark (8, +3) and Apache Pulsar (4, +4). Besides Spark SQL, I also "did" worse for data engineering patterns (6; -7) and data on AWS (3, -3). If you want to compare the results, you will find the graphs for 2019 and 2020 below:
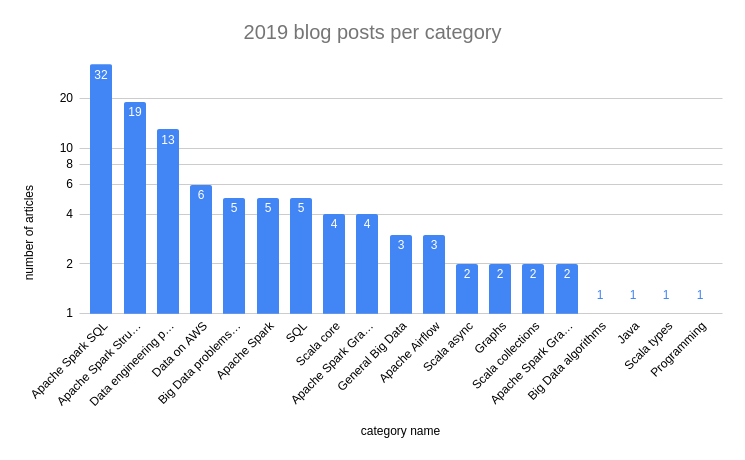
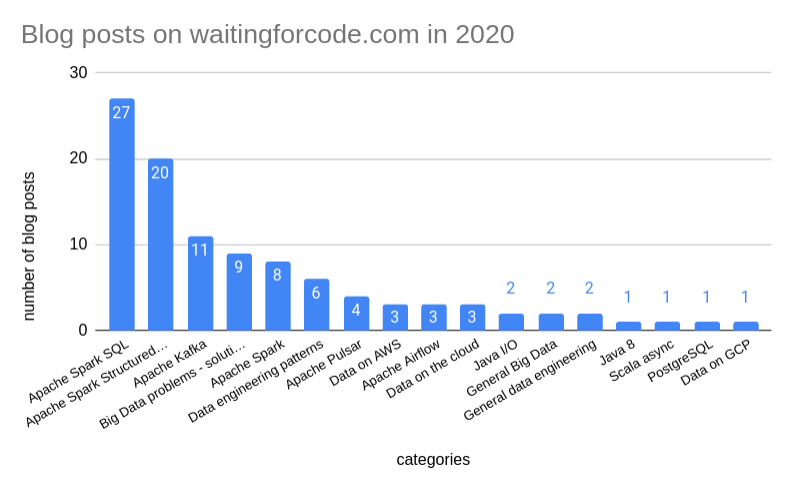
Last year I also shared the top 10 most read posts. This time - surprise, surprise - Apache Spark is only in the 3rd position. I'm still wondering why! Maybe because of the counting method? I'm taking a flat number of reads and since some of the blog posts were published at the beginning of the year, they had more chances to get read. Anyway, maybe in the future I will change the measurement method but meantime, the top list is:
- Data validation frameworks - Deequ and Apache Griffin overview
- Apache Kafka idempotent producer
- Apache Kafka source in Structured Streaming - "beyond the offsets"
- Setting up Apache Spark on Kubernetes with microk8s
- What's new in Apache Spark 3.0 - Proleptic Calendar and date time management
- Schema case sensitivity for JSON source in Apache Spark SQL
- Apache Kafka and max.in.flight.requests.per.connection
- Docker images and Apache Spark applications
- Handling multiple I/O from one thread with NIO Selector
- sortWithinPartitions in Apache Spark SQL
Social media
Apart from the blog, I'm also on Twitter and try to regularly share all the blog updates. If I compare this category with last year, I can see a quite big improvement! Last year only 2 blog posts reached 20+ "likes" but in 2020 there were already 7. Does it mean I improved something or simply the Twitter recommendation algorithm started to "like" me? Let me know what do you think and meantime find the 3 most popular tweets:
To end my journey with #ApacheKafka this month, and before starting the new one in March about transactions, I published a new post. Today I focused on idempotent producers https://t.co/1P1YVZ5I8F
— Bartosz Konieczny (@waitingforcode) January 26, 2020#ApacheSpark is not only about the code, it also about the visuals ?️ The new version of the framework brings some important changes in the UI part, including a major evolution for #StructuredStreaming pipelines ? https://t.co/uFVLcBn4E4
— Bartosz Konieczny (@waitingforcode) October 10, 2020During the next months, I will write about my #ApachePulsar discovery. Today it's time for the first of the posts about a simplified architecture and local setup with docker-compose https://t.co/zUod7qz29s
— Bartosz Konieczny (@waitingforcode) April 25, 2020Looking for some inspiring #dataengineering books ? ? In the new blog post, you can find the Top 9 of the books I've appreciated the most so far ? https://t.co/PLx3CXZF6F
— Bartosz Konieczny (@waitingforcode) December 13, 2020As promised last month, today I published a blog post about my journey to #AWS #BigData Specialty where I described the learning process and used learning resources https://t.co/l27T1hvK3J
— Bartosz Konieczny (@waitingforcode) February 16, 2020
As you can see from the list, some of the tweets (AWS Big Data certification, data engineering books) are related to "me". Does it mean you would like to see more "personal" blog posts? If you want to share your opinion on this or other topic, please leave a comment or send me a message.
Last year, I also took care of the YouTube channel, so far having only no-sound videos to illustrate the blog posts. That being said, I still use the channel to illustrate the blog posts but try to do it with my voice. The top 3 most liked videos last year were:
Last year plans
To recall, in 2020, I wanted to gain better expertise on AWS and GCP data services, Apache Pulsar and Kubernetes. Finally, I succeeded in only half of the plan. I worked hard to learn more about cloud data services, and as a result, I got an AWS Big Data specialty in January and GCP Data Engineer in December. It was hard and time-consuming, but I can say now that I feel much better when I approach a new cloud provider. Recently, I had a chance to work on 2 Azure projects, and I was less intimidated than when I first worked with AWS.
Regarding the two missed points. I started to explore Apache Pulsar and even blogged a few times about it . "Unfortunately", Apache Spark 3 was released last year and - I won't hide it - it's still my favorite Open Source project. I took the decision on whether continuing Pulsar exploration vs learning what's inside Spark 3 very quickly and you could read it in the Apache Spark 3.0.0 features series.
Kubernetes is an even bigger failure. Even though I wrote a few blog posts on running Spark on Kubernetes, I would like to do more in this field.
To justify this, I can say that I blogged a bit more on general data engineering topics like data validation (and discovered Great Expectations!) and data pipelines (mostly Airflow, but also shared a few patterns). I also created new categories like data on the cloud and data on GCP.
Plans for 2021
So, what's my blogging plans for 2021? First, keep learning Apache Spark. The next release (3.1.0) is planned next year (check versioning policy), so I will undoubtedly have a lot to explore in this field. Besides the 3.1.0, Apache Spark has still some low-level concepts like shuffle writers or join algorithms that I would like to explore!
That's the first part of the writing plan. The second one - and it joins my goal of becoming a Pi-shaped person profile - is the cloud, and more exactly, cloud data services. Next year I plan to pass Azure Data Engineer certification, and blogging on the cloud topic should help me to organize the knowledge and see how well I know it since I will have to explain it to you ;)
These 2 topics should dominate next year on the blog, but I don't promise to write exclusively about them. Also, I would like to understand the ACID-compatible file formats (probably Delta Lake or Apache Hudi) and make a bit more videos on the blog's YouTube channel. So far, I considered it as a "decorator" for blog posts but maybe sometime in the future, I will publish blog posts as videos?
Thank you for being here, and I hope you will enjoy 2021 with me on the blog!
And if you want to support my blogging journey, you can offer me a coffee. I have everything to make it tasty while writing the new blog posts ☕

Wishing you the best in 2021!
Best,
Bartosz
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- 2025 retrospective on waitingforcode.com
- 2024 retrospective on waitingforcode.com
- 2023 retrospective on waitingforcode.com
104 blog posts later. It's time to sum up last year. Discover the most popular categories, 2 failures and the plan for 2021 ? https://t.co/Vi1jOnnPRN
— Bartosz Konieczny (@waitingforcode) December 30, 2020
All the best in 2021!