
In the previous post from Big Data patterns implemented series, I wrote about a pattern called fan-in ingress. The idea was to consolidate the data coming from different sources. This time I will cover its companion called fan-out ingress, doing exactly the opposite.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The post is divided into 4 parts. The first one describes 2 ways to implement the pattern. The next 2 parts will contain the implementation examples with the help of Apache Kafka and Apache Spark Structured Streaming. The final section will compare both of them.
Fan-out ingress pattern design
If you have read my series about Apache Beam, you will certainly figure out the similarity between side output and fan-out ingress pattern. Exactly like this Apache Beam's feature, the pattern takes the data of one data source and forwards it into 2 or more different places.
The pattern is then very similar to the approach we can meet in polyglot persistence-based systems. We have there one data source being a source of truth and different consumers reading that data and sending it to other data stores.
According to the pattern's description page linked in "Read also" section, the favored implementation uses one data processing steps to forward the records to other data stores:
"The event data transfer engine is configured with multiple sinks. Once configured, the incoming stream of data is automatically replicated and then forwarded to the configured sinks"
However, in this post I will analyze the second possible implementation where each consumer forwards the data to its own data store. I will focus on the positive and negative sides of both approaches in the last section.
All-in-one implementation
The first implementation uses the same approach as Apache Beam's side outputs, i.e. one processing logic to forward the data:
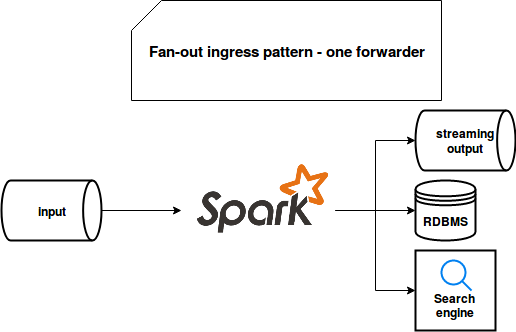
To implement it, I will use the same tools as in the Big Data patterns implemented - fan-in ingress post, i.e. Apache Kafka Docker image and Apache Spark Structured Streaming consumer-producer:
object SingleForwarder {
def execute(): Unit = {
val sparkSession = SparkSession.builder()
.appName("Spark-Kafka fan-out ingress pattern test - single forwarder").master("local[*]")
.getOrCreate()
val dataFrame = sparkSession.readStream
.format("kafka")
.option("kafka.bootstrap.servers", KafkaConfiguration.Broker)
.option("checkpointLocation", s"/tmp/checkpoint_consumer_${RunId}")
.option("client.id", s"client#${System.currentTimeMillis()}")
.option("subscribe", KafkaConfiguration.OutgressTopic)
.load()
// import sparkSession.implicits._
val query = dataFrame
.writeStream
.foreachBatch((dataset, batchId) => {
dataset.write.json(s"${FanOutPattern.JsonOutputDir}output${batchId}")
dataset.write
.option("checkpointLocation", s"/tmp/checkpoint_producer_fanout_${RunId}")
.format("kafka")
.option("kafka.bootstrap.servers", KafkaConfiguration.Broker)
.option("topic", KafkaConfiguration.OutputTopic).save()
})
.start()
query.awaitTermination(TimeUnit.MILLISECONDS.convert(1, TimeUnit.MINUTES))
query.stop()
}
}
Isolated implementation
But as I told, I will also analyze another implementation where each consumer will be responsible for one data store:
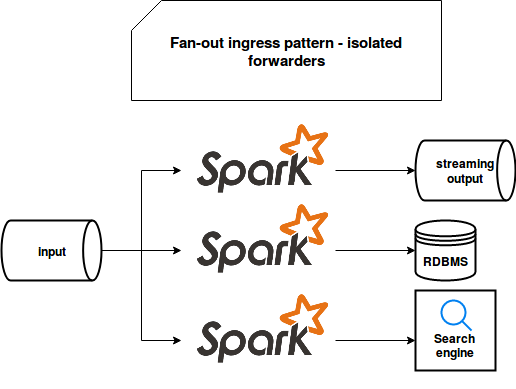
For that scenario, the code it could look like:
object JsonForwarder {
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession.builder()
.appName("Spark-Kafka fan-out ingress pattern test - JSON forwarder").master("local[*]")
.getOrCreate()
val dataFrame = sparkSession.readStream
.format("kafka")
.option("kafka.bootstrap.servers", KafkaConfiguration.Broker)
.option("checkpointLocation", s"/tmp/checkpoint_consumer_${RunId}")
.option("client.id", s"client#${System.currentTimeMillis()}")
.option("subscribe", KafkaConfiguration.OutgressTopic)
.load()
val query = dataFrame.writeStream.foreachBatch((dataset, batchId) => {
dataset.write.json(s"/tmp/fan-out/${RunId}/output${batchId}")
}).start()
query.awaitTermination(TimeUnit.MILLISECONDS.convert(1, TimeUnit.MINUTES))
query.stop()
}
}
object KafkaForwarder {
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession.builder()
.appName("Spark-Kafka fan-out ingress pattern test - Kafka forwarder").master("local[*]")
.getOrCreate()
val dataFrame = sparkSession.readStream
.format("kafka")
.option("kafka.bootstrap.servers", KafkaConfiguration.Broker)
.option("checkpointLocation", s"/tmp/checkpoint_consumer_${RunId}")
.option("client.id", s"client#${System.currentTimeMillis()}")
.option("subscribe", KafkaConfiguration.OutgressTopic)
.load()
// import sparkSession.implicits._
val query = dataFrame.writeStream
.option("checkpointLocation", s"/tmp/checkpoint_producer_fanout_${RunId}")
.format("kafka")
.option("kafka.bootstrap.servers", KafkaConfiguration.Broker)
.option("topic", KafkaConfiguration.OutputTopic)
.start()
query.awaitTermination(TimeUnit.MILLISECONDS.convert(1, TimeUnit.MINUTES))
query.stop()
}
}
Comparison
Both approaches have their good and bad sides. Having a single consumer may reduce your costs because it will be always one computation resource used. Also, it will be always one place to monitor and to evolve which in some contexts may be easier than having the forwarding logic in different places.
But regarding the evolution, the solution of one forwarder is not ideal if you have different delivery constraints. Let me explain. You would like to write the data from your streaming broker into a transactional sink (e.g. MySQL for whatever reason, I know it's not too much "Big Data"), an indexable sink (e.g. Elasticsearch) and another stream (e.g. Apache Kafka topic). With such constraints, you can write the data to the topic without any extra overhead, i.e. only move it to another storage. On the other side, it's not true for 2 other sources which will perform much better for less frequent but bigger writes. To handle that, you will probably need to buffer them somehow in memory. That's fine but the data delivery to the second topic will be delayed by the maximum buffer time of both. This problem doesn't exist in the decoupled architecture where each consumer lives his life and even doesn't know that other ones exist.
To mitigate the previous issue, you can still group the data sinks in the categories of accepted latency. But even that coupling brings some risk that the unavailability of one of them will break all the rest. Also, the maintenance seems easier in the decoupled case. Even an apparently trivial task of upgrading the version of one code dependency can become problematic with one consumer because it risks bringing some incompatibilities between components. The risk is smaller for the case of multiple consumers.
Fan-out ingress pattern is a new proof that every architecture, data or not data-centric, will be a tradeoff between the maintenance, costs, and facility to evolve it. In this post, I presented 2 possible implementations of the pattern, with one and multiple consumers forwarding the data to other places. Both have their advantages and drawbacks but the decoupled version seems to look much easier to maintain and evolve. Even though it risks to increase the final costs.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Big Data patterns implemented - fan-out ingress in Apache Spark Structured Streaming here:
Related blog posts:
- Data Engineering Design Patterns: Dynamic Data Overwriter
- Data Engineering Design Patterns: Hybrid continuous consumer
- Get it once, few words on data deduplication patterns in data engineering
The 4th #data engineering pattern I covered in "data engineering patterns" series is fan-out ingress with #StructuredStreaming examples using foreachBatch added in Apache Spark 2.4.0 https://t.co/8zge4zCeem
— Bartosz Konieczny (@waitingforcode) May 5, 2019