
In March Databricks engineers have shared some tasty details about incremental refreshes on their paper about Enzyme. Since I have been actively exploring Lakeflow Spark Declarative Pipelines recently, I couldn't miss this opportunity to better understand what's behind!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
💡 You can find the link to the full paper in the "Further reading" section.
Because I've already introduced the topic a few weeks ago, Enzyme is a Databricks' Lakeflow Spark Declarative Pipelines (LSD) engine that performs incremental refreshes for Materialized Views (MV). An incremental refresh happens when only a part of the MV must be rewritten. For example, if the execution of your pipeline modifies only one partition, the incremental refresh may apply the partition overwrite strategy to reduce the operation overhead and replace only the partition impacted by the change.
High-level architecture
An LSDP-managed MV consists of two tables: the backing table and the top-level view. The backing table is where Enzyme stores processed records in a format optimized for incremental refreshes. For example, if your pipeline calculates the average of a column, the backing table will store the running sum and count. This allows the engine to compute the average from this partially aggregated data without having to re-scan previously processed data files.
Besides decomposing aggregates, the backing table also generates a unique, immutable and internal row_id to identify each output tuple at every stage of the query plan optimized by Enzyme. The generation of this id depends on where the operation occurs in the plan:
- For leaf nodes Enzyme uses Delta Lake's row tracking feature.
- For higher operators Enzyme uses the optimized operation's semantics to generate the id. For example, for a join the row ids are derived from the row identifiers from the left and right inputs, while an aggregation leverages the grouping keys to uniquely identify each row.
Thanks to these ids Enzyme knows precisely what rows should be updated in the backing table with either REPLACE WHERE or MERGE INTO operations.
The next figure shows the high-level architecture with row ids, backing table, and the top-level view built upon it:
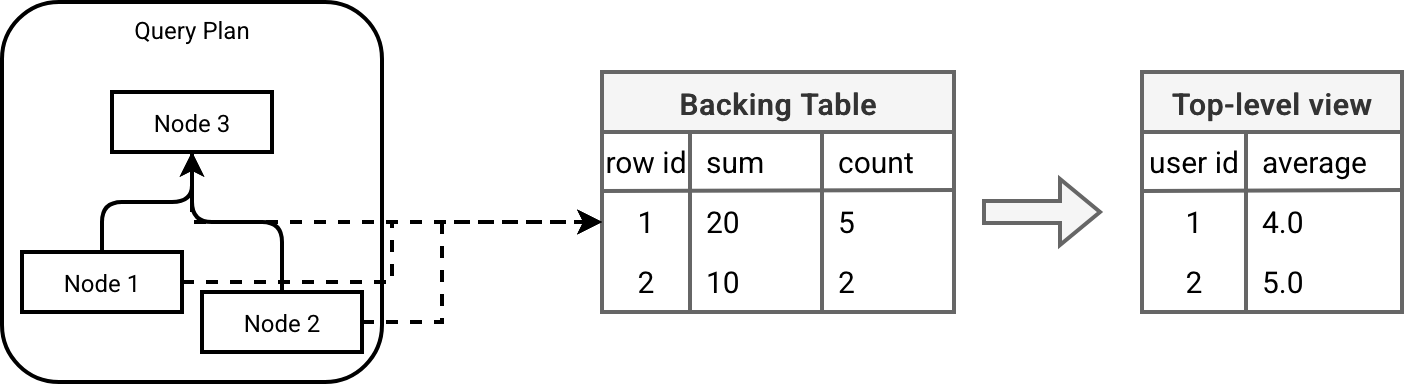
💡 Decomposed elements from the AVG aggregation are called in the paper the technique enablers. More specifically, they are defined as "transformations applied to MV definitions to make incremental computation possible or more efficient".
Refresh workflow
The table's decomposition is only one element of the puzzle. Another one is the incrementalization workflow summarized in the next schema.

Things start here with the Catalyst logical plan that defines the necessary operations to build the Materialized View. The Enzyme engine first applies a normalization step to:
- Simplify the query plan for further usage; here Enzyme performs some well known optimizations from Apache Spark world, inlining Common Table Expressions (CTE), merging filters, removing redundant operations.
- Validate the query plan hasn't changed; this stage is called query fingerprinting and the goal is to ensure correctness of the refreshes. The fingerprint is the MV's definition id and whenever it changes, the incremental refresh won't be possible.
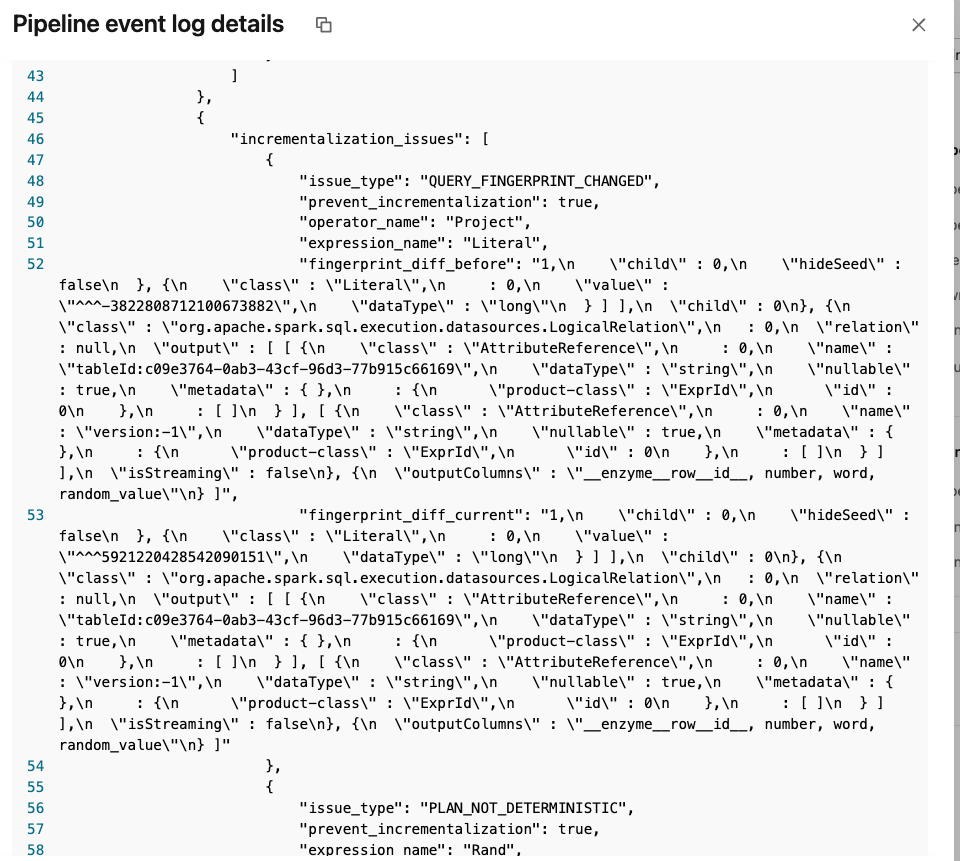
💡 Not only definition changes
Query fingerprint also changes when you use non deterministic functions, such as RAND(). Here is an example where, besides the fingerprinting you can see the query plan:
Next comes the delta plan generation. That's where Enzyme analyzes changes at the logical level, so without touching the data. To determine these changes, Enzyme doesn't consider the query as a whole. Instead it decomposes it into Apache Spark operators such as Project, Filter, Aggregate, Window, or Join and builds delta-plan fragments for each of them.
Three components build delta-plan fragments:
- Pre-plan corresponding to the logical plan that would compute the previous output
- Post-plan corresponding to the logical plan that would compute the new output
- Delta-plan corresponding to the logical plan that would compute the changes for a given operator
Enzyme analyzes the query plan bottom-up and each analyzed operator emits the delta-plan to its upstream operators which, in their turn, use this information to create their own delta-plan and emit next:
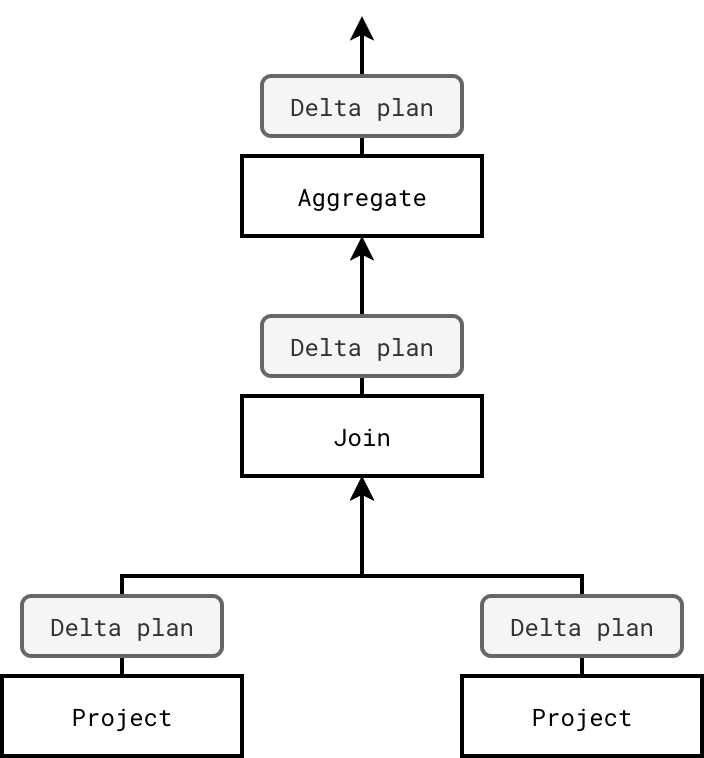
To better understand this delta-plan part, let's analyze a possible output for the Project node, so a SELECT * FROM statement. Here the change between the previous and the new execution is the difference between the committed versions for the input table.
Think about this delta-plan as an augmented logical plan which contains some additional information (deltas). These additional attributes are one of the elements used by the next step in the workflow which is the cost estimation. Enzyme estimates cost based on the profile of the historical executions as "the sum of executor CPU times across key physical operators, including joins, aggregates, window functions, shuffles, file scans, and file writes". If there is no history for a MV, Enzyme leverages query processing logs.
After comparing the cost for each operator, Enzyme moves to the next step which is applying the changes.
Applying changes - REPLACE and MERGE
The execution workflow continues and the part for applying changes looks like in the next figure:

Besides rewriting the execution plan, Enzyme also shares the best execution strategy suggestions with Apache Spark. It may involve sharing hints for the join strategy, or converting predicate-based operators to semi-joins in case of failed dynamic file pruning activation for data pruning.
After applying these elements to the plan, Enzyme performs yet another preparation step. The engine decides how the backing table will be updated. It can follow here the:
- MERGE INTO strategy.
- REPLACE WHERE strategy. It's a delete-then-insert operation and for that reason Enzyme must perform an additional step before physically appling the changes. This step is called effectivization and consists of removing inconsistent actions on the changed rows. For example, a row can be marked as for insertion and for deletion. Because of the delete-then-insert semantics, the deleted row will be left in the backing table while it should have been deleted just after the insert. The effectivization will remove redundant pairs of insert/delete rows to avoid this kind of issues, and also reduce the volume of updated rows.
The chosen method depends on the "characteristics of the changeset and the query structure". The paper doesn't share any other details when the one writing strategy is picked over another. But this definition gives another important component of the physical plan execution which is the changeset. Changeset is a dataset with all the removed and added rows to the backing table.
💡 Enzyme may cache DataFrames for complex plans, like the ones with multiple aggregations or joins. The cache can help avoid redundant input reading in case of a DataFrame shared in different places of the MV query plan.
After all these steps the backing table gets refreshed with some additional metadata useful for the next query incrementization. The changes are visible via the top-level view to the end user.
The Enzyme paper gives much more interesting details on how the incremental refreshes are really working with Lakeflow Spark Declarative Pipelines. Putting all them here would mean just rephrasing the paper while my goal was to vulgarize it so that you - and me from the future by the way - can understand the big picture much more easily.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Enzyme and Materialized Views on Databricks - better understanding from the SIGMOD-Companion paper here:
Related blog posts:
- Lakeflow Spark Declarative Pipelines and Slowly Changing Dimensions
- Lakeflow Spark Declarative Pipelines, flows, private tables, and configuration
- Lakeflow Spark Declarative Pipelines, introduction and incremental refreshes
- Spark Declarative Pipelines internals
- Spark Declarative Pipelines, going further