
At the moment of writing this post I'm preparing the content for my first Spark Summit talk about solving sessionization problem in batch or streaming. Since I'm almost sure that I will be unable to say everything I prepared, I decided to take notes and transform them into blog posts. You're currently reading the first post from this series (#Spark Summit 2019 talk notes).
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
I've already shortly wrote about checkpoints in Structured Streaming in fault tolerance in Apache Spark Structured Streaming. However, I covered there only high-level concepts. Spark Summit was a great occasion to deep delve into the details of this feature. This and remaining posts of the series will be organized around different questions I was trying to figure out during the talk preparation. From time to time, to not bother you with 10 pages of details, one topic will be decomposed into 2 or more posts. That's the case for this first post presenting checkpoint storage internals.
Outline:
- Why needed?
- What is stored?
- What is the storage format?
- How checkpoint enforces at least delivery?
- Will it grow indefinitely?
- What are the configuration options?
- How to use checkpoint?
Why needed?
The primary goal of checkpointing is to ensure the fault-tolerance of streaming jobs. Thanks to the metadata stored in checkpoint files you will be able to restart your processing in case of any failure - business logic (ex: regression in the code) or technical (ex: OOM error).
Checkpoints are also important to guarantee at-least once processing in case of any failure in the middle of currently processed micro-batch.
What is stored?
Checkpoint is a physical directory, optimally on a distributed file system, responsible for storing 4 types of data:
- source - files in this directory contain the information about different sources used in the streaming query. For example, for Apache Kafka the checkpointed source file will contain a map between topic partitions and offsets at the first query execution. This value is immutable and doesn't change between query executions.
- offsets - contains a file with information about data that will be processed in given micro-batch execution. It's generated before the physical execution of the micro-batch. Internally it's represented by org.apache.spark.sql.execution.streaming.OffsetSeqLog class.
- commit logs - it's a kind of marker file with the information about the watermark used in the next micro-batch. Internally it's represented by org.apache.spark.sql.execution.streaming.CommitLog class and the metadata is represented as org.apache.spark.sql.execution.streaming.CommitMetadata.
- state - it'll be the topic of another post but checkpoint location is also responsible for the storage of state generated by stateful processing logic.
What is the storage format?
Checkpointed data, that is, offsets, commits and sources, is stored in plain text. Their common point is that all of them begin with the version number like "v1". The version should ensure that the checkpoint created with a new version of Apache Spark won't be processed by an older version of the framework. Allowing the processing of that case would risk to introduce consistency issues. You can see that from the message generated if the version is not supported which looks like:
The log file was produced by a newer version of Spark and cannot be read by this version. Please upgrade.
Regarding the remaining parts of checkpointed files, you will find the persisted elements in serialize methods of OffsetSeqLog and CommitLog classes. For the former one, the content looks like:
{"batchWatermarkMs":1564634495145,"batchTimestampMs":1564634518664, "conf":
{"spark.sql.streaming.stateStore.providerClass": "org.apache.spark.sql.execution.streaming.state.HDFSBackedStateStoreProvider",
"spark.sql.streaming.flatMapGroupsWithState.stateFormatVersion": "2",
"spark.sql.streaming.multipleWatermarkPolicy":"min",
"spark.sql.streaming.aggregation.stateFormatVersion": "2",
"spark.sql.shuffle.partitions": "200"}}
You retrieve there different configuration entries, current watermark and processing time (batchTimestampMs). The class exposing all this metadata is OffsetSeqMetadata. The list of configuration entries to persist is defined in OffsetSeqMetadata#relevantSQLConfs field. Does this configuration is used somewhere? Yes, for example spark.sql.shuffle.partitions is used to figure out the number of state stores associated with every streaming query. Also, the configuration overwrites the properties of current SparkSession before starting the streaming query for given execution. It happens inside OffsetSeqMetadata#setSessionConf method and you can notice that by observing messages like:
19/08/11 11:27:58 WARN OffsetSeqMetadata: Updating the value of conf 'spark.sql.shuffle.partitions' in current session from '10' to '200'. 19/08/11 11:27:58 WARN OffsetSeqMetadata: Updating the value of conf 'spark.sql.streaming.flatMapGroupsWithState.stateFormatVersion' in current session from '1' to '2'.
As for versions mentioned earlier, the configuration overriding also enforces consistency between executions. Imagine that you're running the same streaming job but with different state provider. Logically you won't retrieve your state from the last execution but do you want this? If you don't want to load the state, you can simply start another streaming query, with completely new checkpoint location.
Regarding the last element from offset file, it's a JSON line with the mapping between partitions and offsets for each data source involved in the query. For example, in the case of an Apache Kafka source this place will store topic name, partition number and starting offset for given micro-batch run, like here where we're reading a topic with 1 partition:
{"raw_data":{"0":246189}}
Commits file contains only one entry with the watermark applied to the next query execution:
{"nextBatchWatermarkMs":1564634495145}
State files are compressed but I will detail them in one of the next posts.
How checkpoint enforces at least delivery?
Now, when you know that commits and offsets aren't generated at the same time, I bet that you have an idea to answer to this question. If not, this picture should help you to get one:
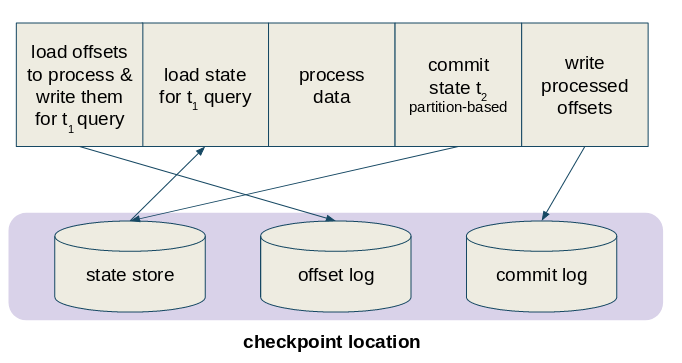
As you can see, since the data to process is written at the beginning of the query execution and the information about a successful processing only at its end, when the query is restarted, Apache Spark will simply check whether the last written offset has the corresponding commit log. If yes, it will consider the processing as successful and start from the next offset. Otherwise, it will restart the query from the oldest not completed execution.
Will it grow indefinitely?
No. Apache Spark will always keep the number of checkpointed files that you specified in the configuration entry. The configuration entry responsible for that number is spark.sql.streaming.minBatchesToRetain and its default is 100.
You should not ignore this property since it will define your data reprocessing period. For example, if you decided to keep only the last 10 entries that are generated every minute, you will be unable to reprocess the data older than 10 minutes - or at least, you will be unable to do it easily by simply promoting checkpointed information to the one to use by the query. Checkpoint cleaning is a physical delete operation, so you lose the information indefinitely.
What are the configuration options?
Actually you can configure checkpoint in 3 ways. First, you can define the custom checkpoint location in checkpointLocation parameter. Otherwise, you will need to figure out when the data is checkpointed by analyzing logs:
19/08/11 11:36:08 INFO CheckpointFileManager: Writing atomically to file:/tmp/temporary-886ab3a8-3354-4042-8678-54856b14619a/metadata using temp file file:/tmp/temporary-886ab3a8-3354-4042-8678-54856b14619a/.metadata.4770f382-b0d2-4c4e-9cd1-9825db1b7844.tmp 19/08/11 11:36:08 INFO CheckpointFileManager: Renamed temp file file:/tmp/temporary-886ab3a8-3354-4042-8678-54856b14619a/.metadata.4770f382-b0d2-4c4e-9cd1-9825db1b7844.tmp to file:/tmp/temporary-886ab3a8-3354-4042-8678-54856b14619a/metadata
Moreover, if you don't specify checkpointLocation, the directory created for the query execution will be only a temporary location that will be removed once current SparkSession stops.
Previous parameter applied at the query level and is good if you have multiple queries running over the same data source and sharing the same SparkSession. Otherwise, you can use a more global property called spark.sql.streaming.checkpointLocation. If this property is used, Apache Spark will create a checkpoint directory under ${spark.sql.streaming.checkpointLocation}/${options.queryName}. If queryName options is missing it will generate a directory with random UUID identifier.
Always define queryName alongside the spark.sql.streaming.checkpointLocation
If you want to use the checkpoint as your main fault-tolerance mechanism and you configure it with spark.sql.streaming.checkpointLocation, always define the queryName sink option. Otherwise when the query will restart, Apache Spark will create a completely new checkpoint directory and, therefore, do not restore your checkpointed state!
The last configuration property impacting checkpoints is spark.sql.streaming.checkpointFileManagerClass. This entry represents the class used to manage checkpointing and its default implementation used HDFS-compatible file system. If you want to implement your own, you will need to implement CheckpointFileManager trait.
In this first post from notes taken for my Spark Summit AI 2019 talk I covered the checkpoint storage part. You can learn here what is stored in the checkpoint location, what is the format of stored files and the required configuration to reduce the amount of written state. In the next part I will discuss checkpoint use for reprocessing purposes.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Checkpoint storage in Structured Streaming here:
Related blog posts:
- Extending state store in Structured Streaming - reprocessing and limits
- Extending state store in Structured Streaming - reading and writing state
- Why UnsafeRow.copy() for state persistence in the state store?
- Extending state store in Structured Streaming - introduction
- Extending data reprocessing period for arbitrary stateful processing applications
That's the first of my #SparkAISummit follow-up posts. I started with an introduction to the checkpoint storage in #ApacheSpark #StructuredStreaming. I also tried a new FAQ-like format. I'm really curious what do you think about it https://t.co/xqz2E02XYc
— Bartosz Konieczny (@waitingforcode) October 20, 2019