
Even though you may be thinking now about Data+AI Summit 2024, I still owe you my retrospective for the 2023 edition. Let's start with the first part covering stream processing talks!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The Hitchhiker's Guide to Delta Lake Streaming
In the first talk from my list, Scott Haines and Tristen Wentling introduce the fascinating world of Delta Lake and streaming. In the first part, they introduce streaming and show the main difference between batch and streaming world for Delta Lake that is pretty well summarized in this slide:

Later, they introduce something completely new to me - and probably to you too - the Goldilocks Problem. "Streaming is always the Goldilocks Problem", meaning that there is never the right answer for sizing. If you use too small cluster, you'll inevitably encounter OOM errors. If you give you some extra capacity, you will run out of budget. If somehow you succeed to size it right today, nothing guarantees the setup will be fine next week... Summary in the slide below:

Even though it's hard to predict the resources you cluster will need, it's good to do at least an estimate. But how? Haven't we just learned it's barely impossible to size things in streaming? Thankfully, table properties can help. Tristen and Scott share a set of useful queries that should help you to:
- Analyze the table freshness

- Analyze the growth rate of the table and get a rough idea of the data increments over the days


The next part is about the rate limiting. You can configure it with the maxFilesPerTrigger or maxBytesPerTrigger. Whichever you choose, you should start small and increase the number if needed. Additionally, you can rely on the job triggers to control the rate even better.
The last point concerns schema evolution. Scott and Tristen recommend turning the overwriteSchema and mergeSchema off, or at least, being particularly careful with them. It can lead to inconsistent schemas and bad surprises in the system. The speakers compare it to git push --force; sometimes it'll work but when not, the failure can be catastrophic.


There are 3 lesson learned: Plan ahead (estimate), Make trade-offs between speed and costs (rate limiting), and Schema control.
After this pure Delta Lake streaming points, Scott and Tristen shared their discovery about the compression codec. Turns out, the zstd performs much better than the default Snappy encoder!

🎬 Link to the talk: The Hitchhiker's Guide to Delta Lake Streaming.
Streaming Schema Drift Discovery and Controlled Mitigation
There was also another talk about this schema merge in the context of streaming jobs. Alexander Vanadio explained not only why it's bad, but also how to detect and fix schema differences.
To start, he introduces the schema drift which happens when the data providers evolve their dataset you're working on without necessarily notifying you before. Of course, an apparently simple mitigation appears, the mergeSchema options introduced before. Alexander uses another picture to explain why it's not a good idea:
mergeSchema is like parking your bus on the train tracks; maybe the train will never, maybe the train was decommissioned (...) but if it wasn't, you're gonna have a bad day.
Above you can see some of the consequences:

Instead it's better to have a gating process that will control what you process in the pipeline. The solution Alexander proposes starts with Databricks Auto-Loader and its rescue strategy for records mismatching the schema. The speaker points out a specific use case when it can happen very often, the semi-structured dataset with sparsely populated data because some of the keys can be so rare than the Auto-Loader's schema inference mechanism will not even see them.
To implement the Schema Drift detection mechanism, Alexander starts by defining the Drift Table with all rejected events:
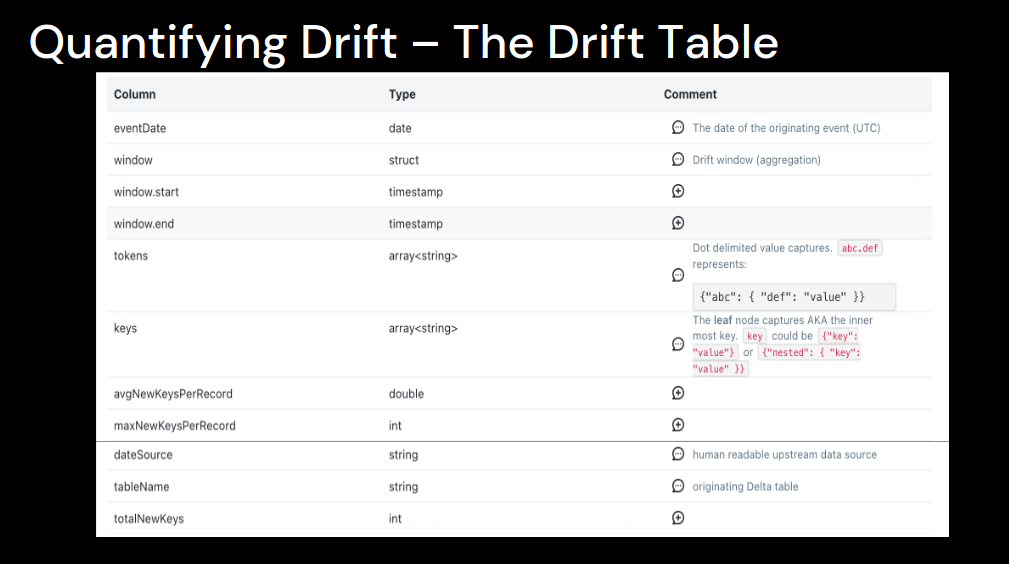
The next step is to visualize the table in SQL Workspace and create alerts on it:
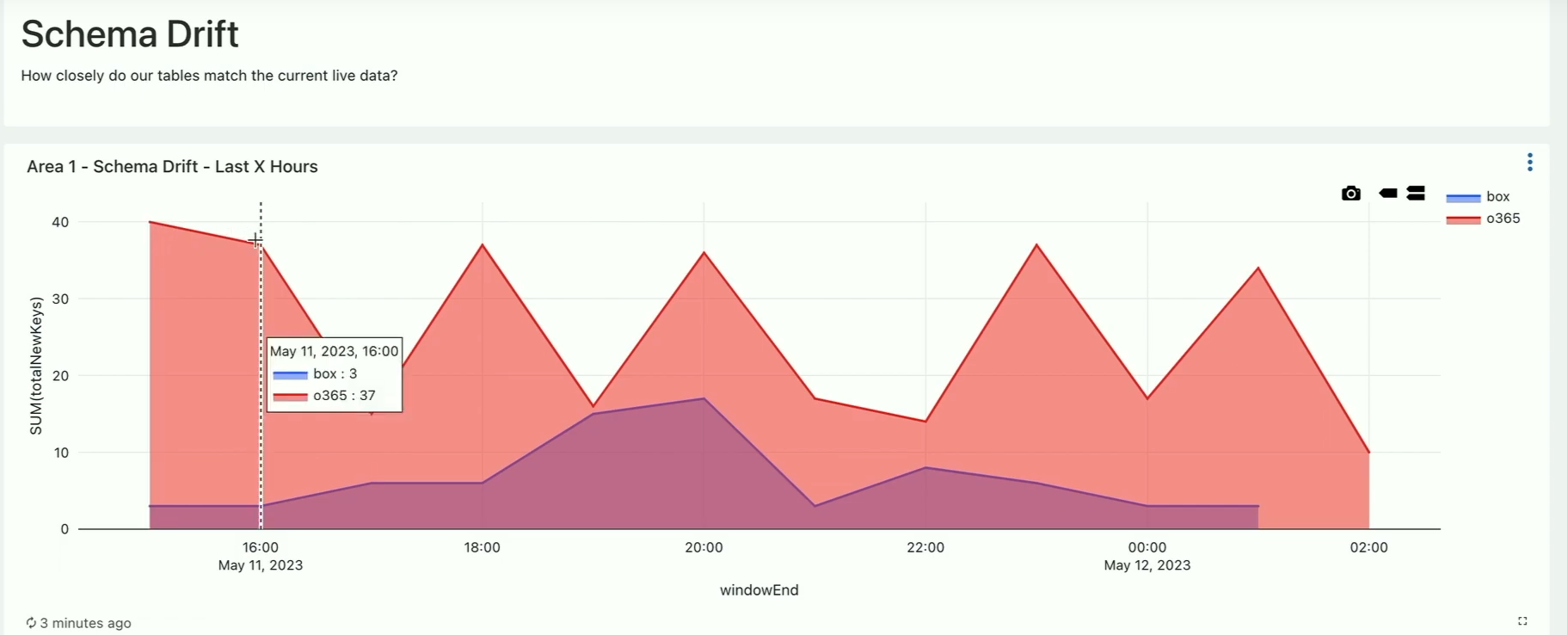
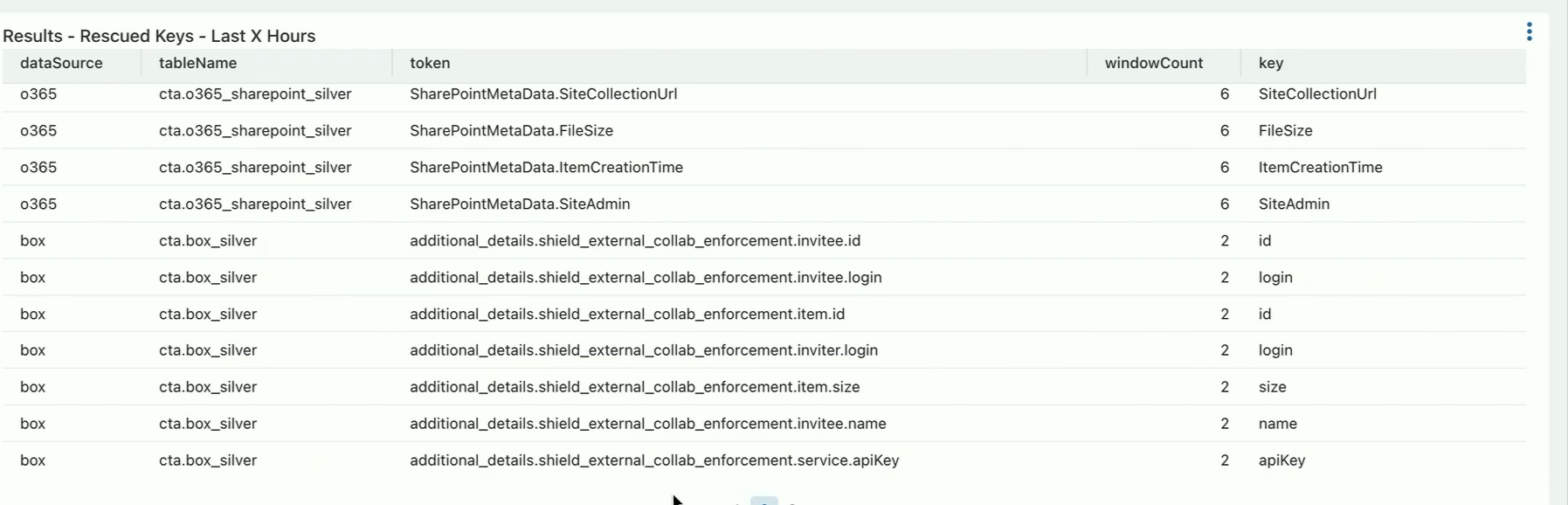
After, the point is to verify the rescued keys with the data providers and promote some of them to the table. How? By reverse-engineering the Auto-Loader! The idea is to add all necessary fields to the metadata file managed by this component:

And restart the job afterwards. Now, it still doesn't allow the new fields to be integrated in the Delta table. But guess what? When you have this gatekeeping layer up and running, you can safely turn the mergeSchema on! As Alexander mentions, it now works on "our terms", so the risk of having bad surprises is greatly reduced thanks to the schema drift detection mechanism:

🎬 Link to the talk: Streaming Schema Drift Discovery and Controlled Mitigation.
Unlocking Near Real Time Data Replication with CDC, Apache Spark™ Streaming, and Delta Lake
Schemas seem to be one of the main concerns of another streaming talk. This one was given by Ivan Peng and Phani Nalluri from DoorDash. They shared their journey for near real-time data replication.
Some context first. First, was the data ingestion approach based on the SQL queries but the drawback was the latency since the queries were expensive. The method evolved from a simple SELECT * FROM table query to the SELECT * FROM table WHERE update_at > $LATEST_DATE followed by the MERGE (upsert), that could run more often. One of the biggest challenges the authors faced was schema evolution, and especially the incompatible changes that would require a lot of human effort (more than 1k tables ingested).

That's how the Project Pepto was born:

The idea? Stream all changes with the Change Data Capture pattern to Apache Kafka and run Apache Spark Structured Streaming jobs to consume them and write to the Delta Lake lakehouse. At this moment, the job applies schemas from the Protobuf Schema Registry. Besides, for the first exports, instead of streaming the changes, the job makes the snapshots and writes them to S3. Finally, all this lakehouse data can be viewed in one of the available interfaces.
An important aspect here is the schema registry and the implication of the product engineering teams to apply the schema changes from the source databases there.
The ingestion works in 3 modes:
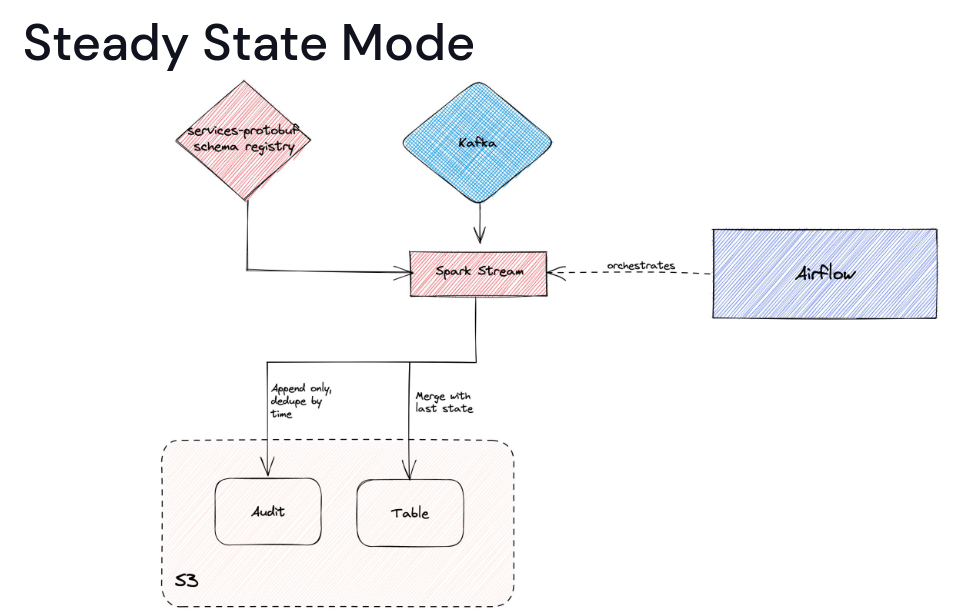
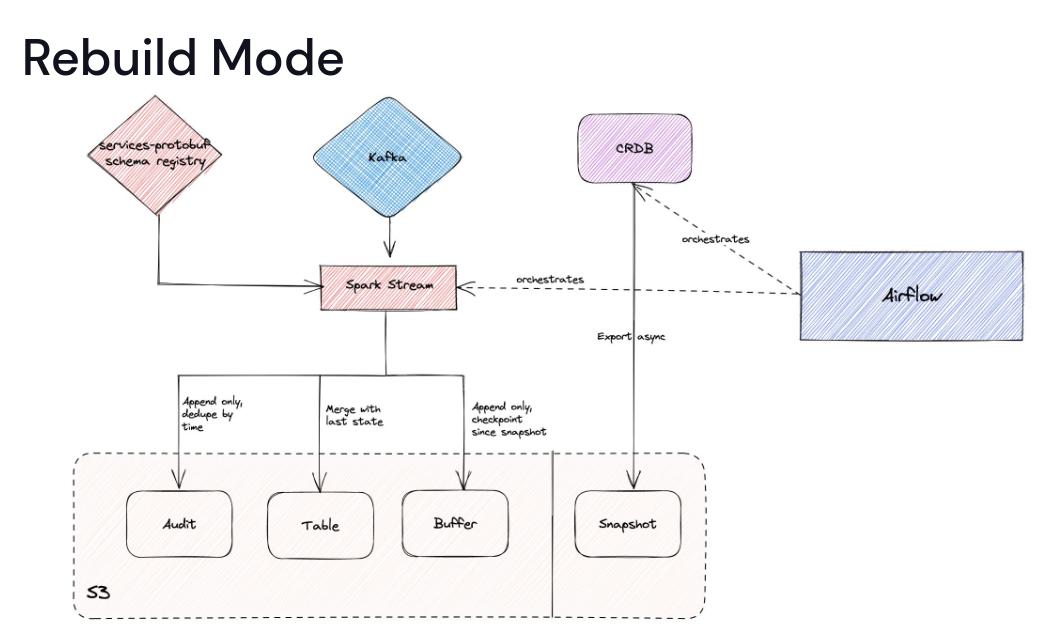
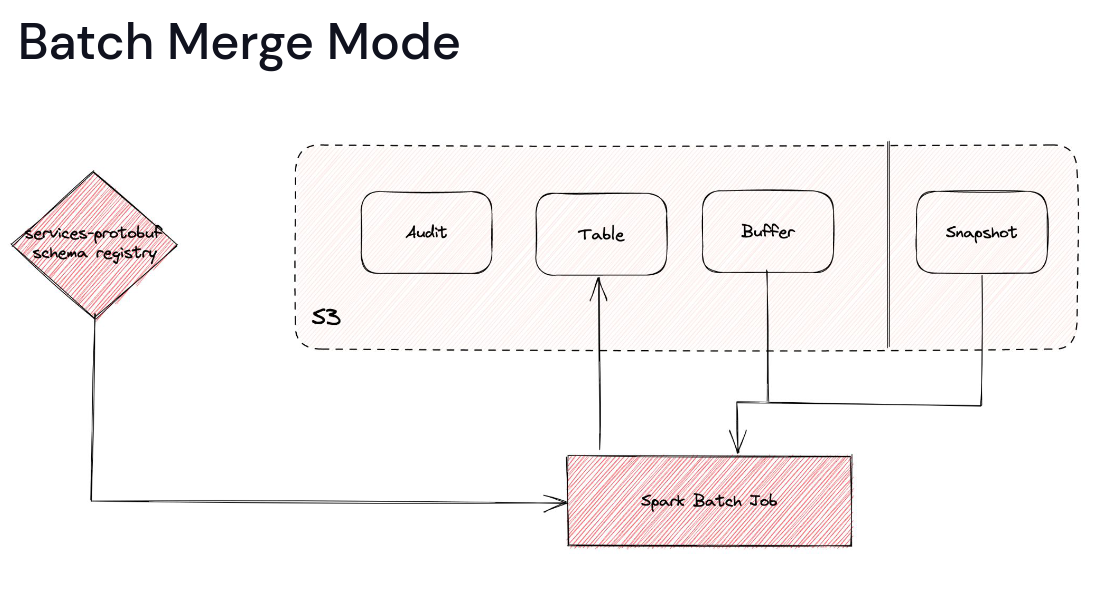
The Steady mode is for the initial CDC streaming and transformation use case. The Rebuild mode does the initial snapshot and also writes all CDC changes to a new buffer table. The final Batch mode is for fixing any incompatible schema changes as it overwrites the table by merging the snapshot and buffer rows.
The Project brought several improvements to the initial process:

🎬 Link to the talk: Unlocking Near Real Time Data Replication with CDC, Apache Spark™ Streaming, and Delta Lake.
Disaster Recovery Strategies for Structured Streams
After these schema-related topics, it's time to see a different streaming aspect, the resilience. In their talk, Sachin Balgonda Patil and Shasidhar Eranti, explained different strategies for recovering streaming pipelines.
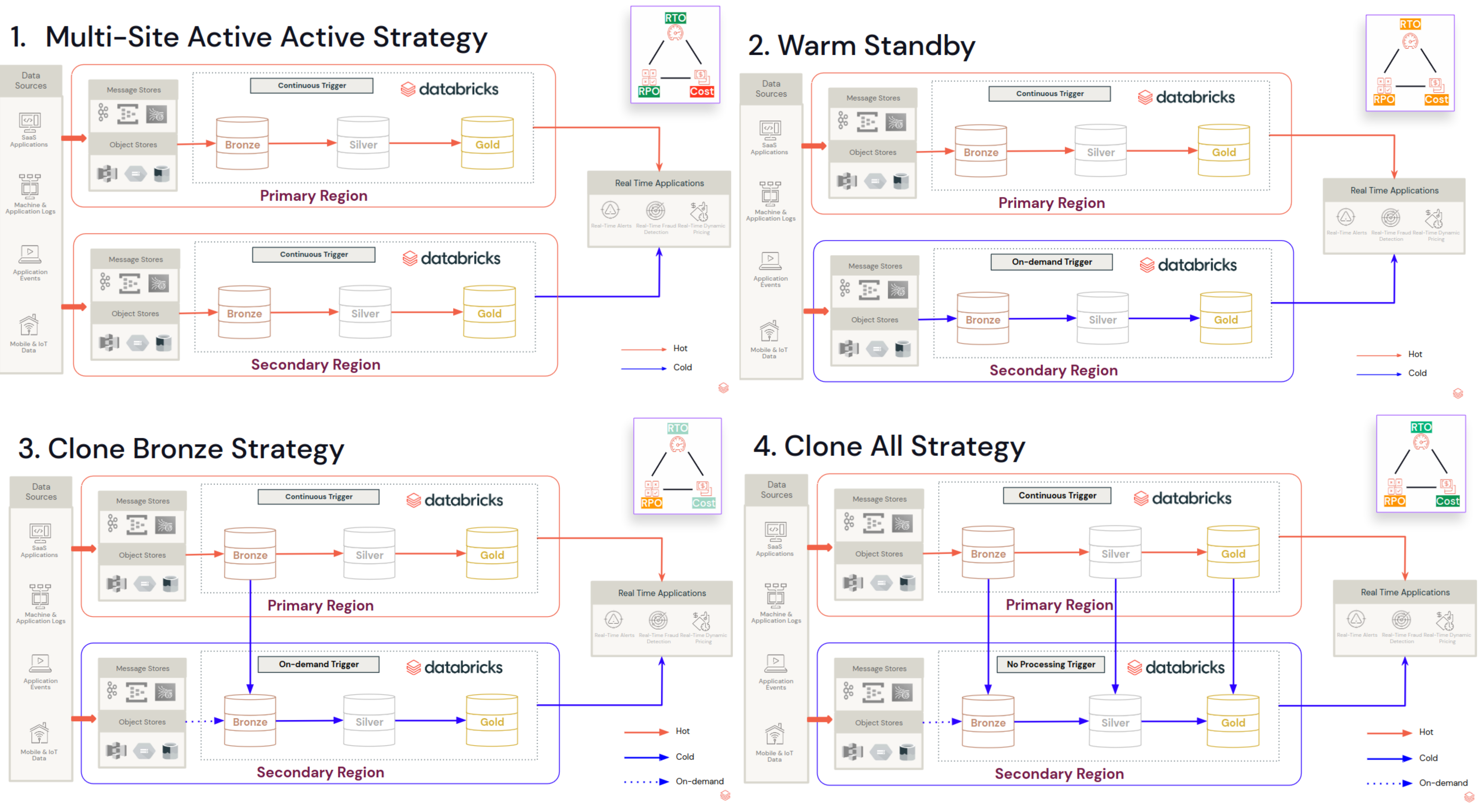
Which one to choose? It depends on what you want to optimize for. If it's RTO and RPO, the Multi-Site is the best. If you prefer a less expensive solution, clone-based can be a better fit. The decision making greatly simplifies this slide:
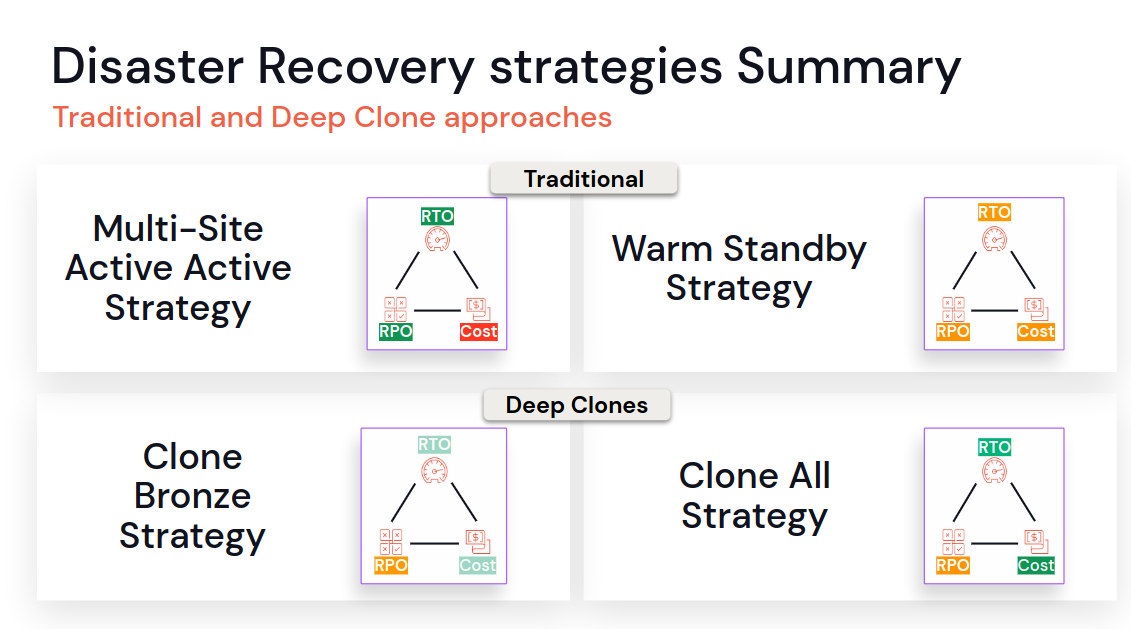
Sachin and Shasidhar give even more detailed information on how to implement disaster recovery for stateless and stateful pipelines. They decided to focus on the Deep Clones strategies and highlighted several important points:
- You cannot take the checkpoint as it because the tables have different ids in the metadata
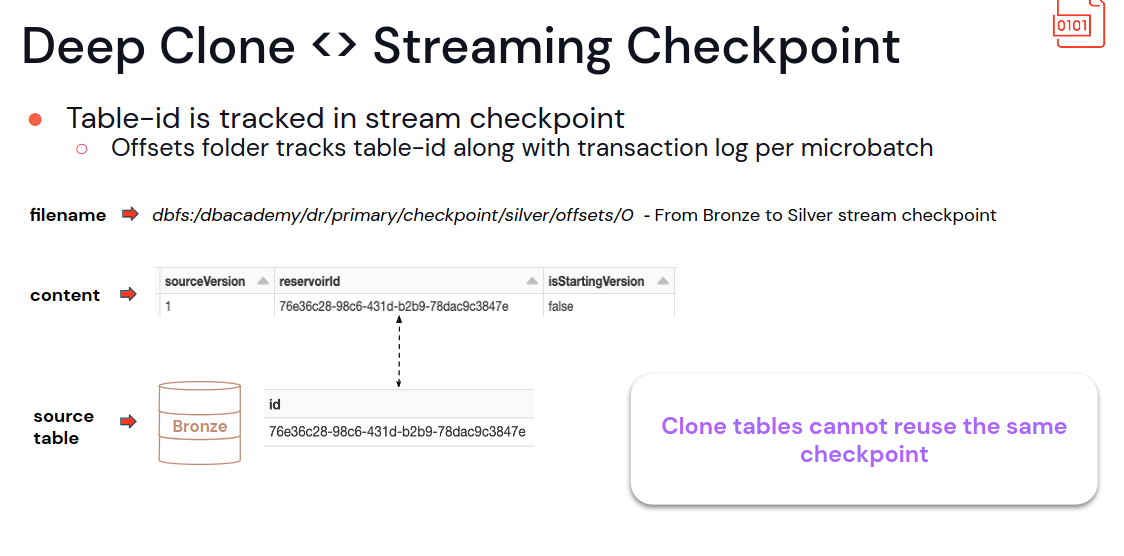
- Delta Deep Clone is an incremental operation, i.e. it won't clone the whole table each time, only the last changes.
For the stateless jobs, the best strategy is the Clone All approach with the following failover logic:
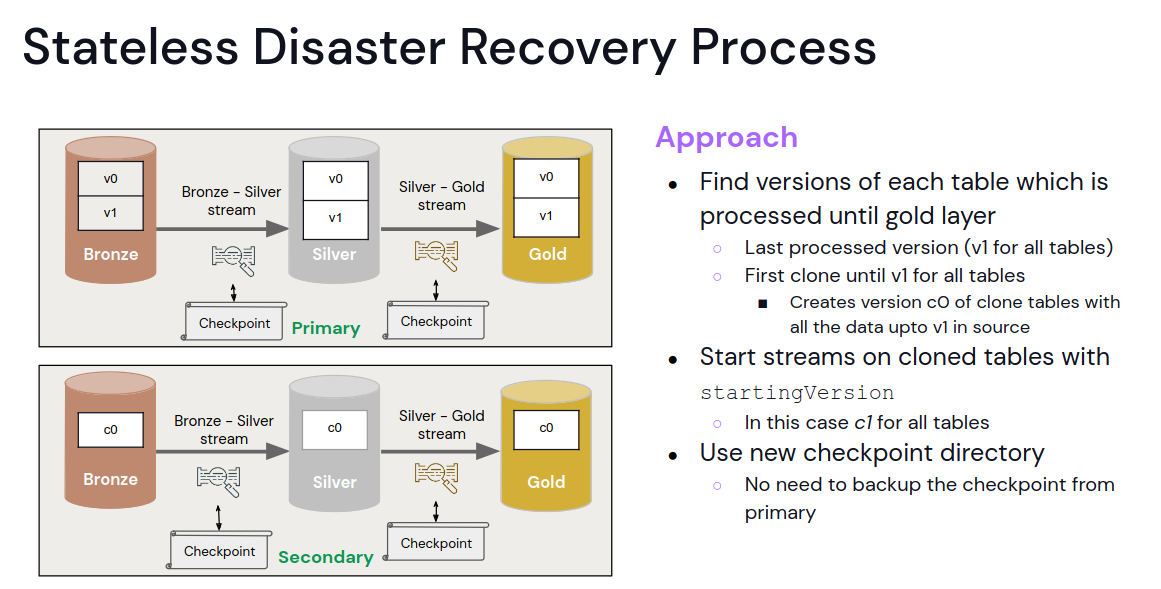
Stateful pipelines should be secured with the Clone Bronze strategy; the Clone All won't work because of the checkpoint incompatibility. That's the reason why only the Bronze table gets copied and the stateful job(s) will be rerun on top of it. The frequency will depend on your RPO and RTO. It can be a daily procedure or a more frequent action if lower guarantees are needed.
🎬 Link to the talk: Disaster Recovery Strategies for Structured Streams.
Top Mistakes to Avoid in Streaming Applications
Finally, the talk with some Structured Streaming best practices shared by Vikas Reddy Aravabhumi. He introduces all of them in the first slide:

But I'm sure it's not enough, so let's go and see them in detail:
- Kafka data retrieval - remember, there is 1 task per Kafka partition by default; you can increase it with option("minPartitions", sparkContext.defaultParallelism)
- Rate throughput - with maxOffsetsPerTrigger (Kafka), maxFilesPerTrigger, maxBytesPerTrigger (Delta); particularly useful when you start your query for the first time and reading the whole history
- The rate throughput might be ignored - the slides show the situation when

- Prefer AvailableNow instead of Once for triggering streaming jobs in a batch way; the throughput limits are not respected in the latter one
- Watermark is there to reduce the state overhead.
- Prefer RocksDB for a more memory efficient state store.
- Remember to persist the input DataFrame in your foreachBatch function to avoid recomputing it.
🎬 Link to the talk: Top Mistakes to Avoid in Streaming Applications.
Structured Streaming: Demystifying Arbitrary Stateful Operations
To complete the Vikas' talk, Angela Chu shared how to build an arbitrary stateful processing job. She explains the whole idea very clearly around these 4 concepts:

The first block is about the data types you use for the input records, state, and output interacting with the stateful function. PySpark, on the other hand, requires schemas instead of the classes. For a simpler usage, you can use a namedtuple. At this occasion, Angela reminds that the input data are iterators, so the one-pass data structures. You might need to materialize them if you need to access them twice.
When it comes to the initialization logic box, it's relatively easy with Scala API since uses the native getOrElse. It's a bit different for Python:

The 3rd part is about the business logic for steady-state, so for an already initialized state. The idea here is to use the CRUD operations exposed by the state store to update or remove the state depending on the incoming data. Again, an important thing to notice here for the PySpark API; the key is a tuple!

Finally, there is the part for expired state that should implement state removal from the state store and output records generation.
🎬 Link to the talk: Structured Streaming: Demystifying Arbitrary Stateful Operations.
Good news, that's all for the streaming talks I wanted to share with you. The bad one, that's only part 1 of the Data+AI 23 retrospective! The next one will cover more deep dive and technical aspects of Apache Spark and Delta Lake.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- DAIS 2024: Orchestrating and scoping assertions in Apache Spark Structured Streaming
- Data+AI Summit 2024 - Retrospective - Apache Spark
- DAIS 2024: Testing framework from the Dataflow model for Apache Spark Structured Streaming
- Data+AI Summit 2024 - Retrospective - Streaming
- Data+AI Summit 2023, retrospective part 2