
One week later than initially announced, but here it is, the second part for Data+AI Summit 2023 retrospective. I don't know how, but I managed to include some streaming-related talks here too!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Optimizing Batch and Streaming Aggregations
In the first talk from this complementary list, Jacek Laskowski explains how to optimize aggregations in batch and streaming with Apache Spark. The first insight is pretty interesting. As both parts share the same logic, it's easier to start with batch query optimization, even if the issue comes from the streaming one!

Next, Jacek delves into the aggregation execution and reminds 3 physical operators involved at runtime:

The best one is the first from the list because it doesn't involve any sort operation and simply operates on the keys. The second one is similar but it doesn't support the Whole-Stage Java codegen while the last one works only for the aggregations without the grouping key. Jacek greatly summarizes them in the next 3 slides:

Unfortunately, this sort-based aggregator is not always related to the operation you're doing. For example, an aggregation qualified for the hash aggregation can fallback to the sort-based one if the underlying map structure runs out of memory. And it can be a big performance pain point you should be aware of:

But Jacek's investigation doesn't stop here. Turns out, the optimized aggregation was a custom User-Defined Aggregation Function (UDAF) that relies on the 2 least performant physical operators without any hope of being optimized by Catalyst:

But that's not all. The poorly performing aggregation was running in the streaming context. It may have its own issues you should get rid of, for example by turning the query to the batch one, before moving on:

All this led Jacek to the list of issues caused by the UDAF and underlying physical operation, and his recommendation:

🎬 Link to the talk: Optimizing Batch and Streaming Aggregations.
Eliminating Shuffles in Delete Update, and Merge
But aggregations are not the single performance-sensitive operations in Apache Spark. Others are row mutations. Anton Okolnychyi and Chao Sun share in their talk how to reduce the impact of shuffle for them.
But first, they remind how data processing frameworks deal with the row mutations. The effort can go to the reader side (merge-on-read) or the writer side (copy-on-write), both having their own pros and cons.
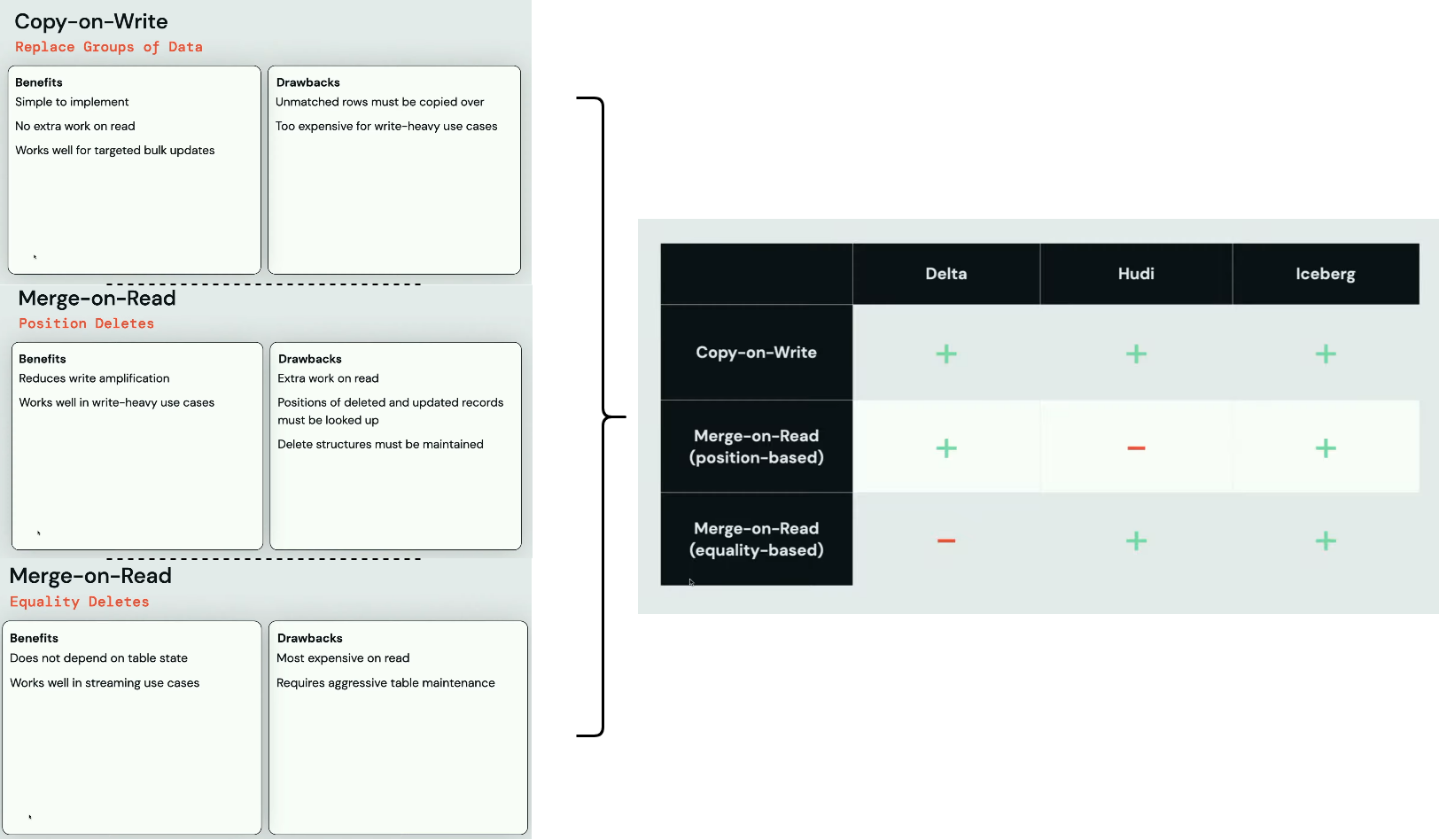
The Copy approach rewrites all rows from the file with the mutated rows while the Merge one creates a new file with only the mutated rows. Thus, the Merge and effort on the reader.
The Copy-On-Write often starts as a sort-merge join but due to the sort steps, it can be less efficient than its hash-based alternative:
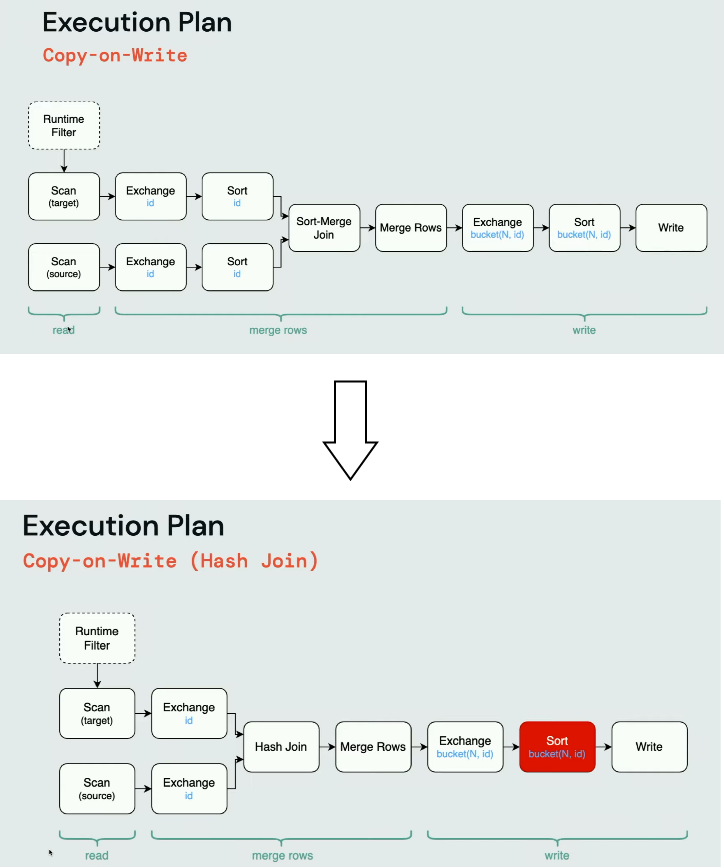
The Sort step before the Write is highlighted on purpose. It's required by Apache Iceberg used in the plan analysis to keep only one file open per task. Once all records for a given partitions are written, the task closes the partition file and opens the file for the next one.
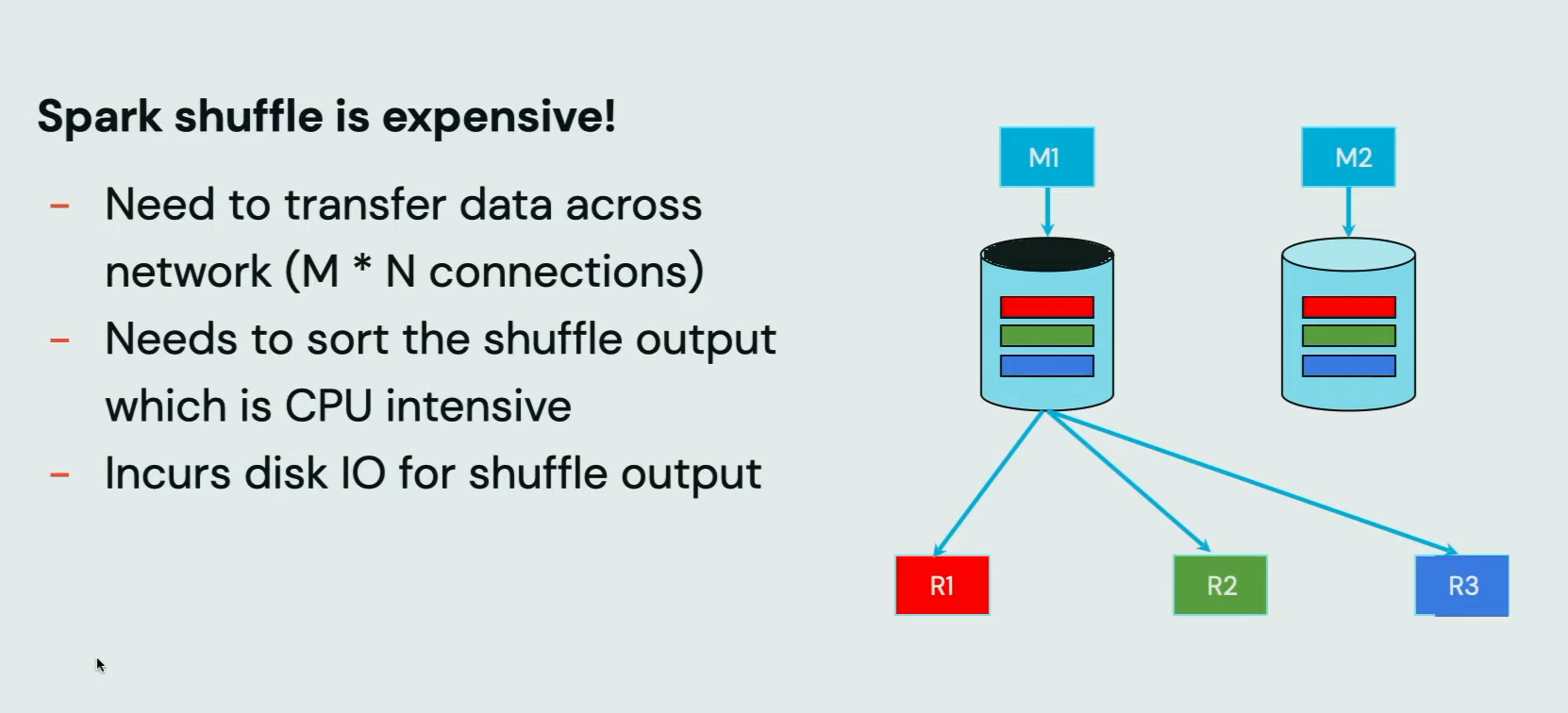
However, the hash join is not a silver bullet. As it relies on shuffle, it can also become costly in terms of execution time. Anton and Chao recall it in their next slide:
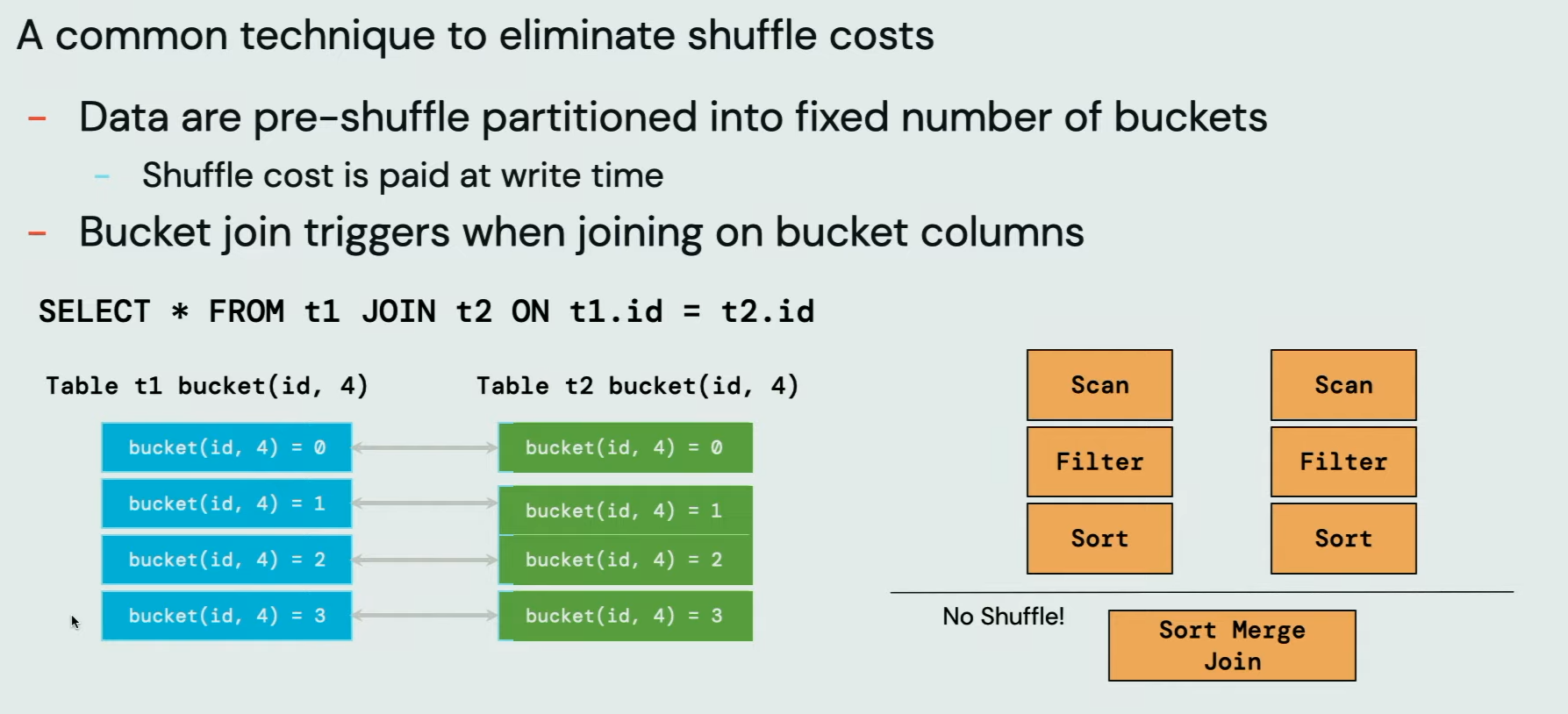
If you are a seasoned Apache Spark user, you know that you can avoid shuffle in joins by using buckets. Well, technically you still pay the shuffle price but you do it only once, while writing the dataset. All subsequent readers should be shuffle-less:
However, the bucket is not that well supported in the recent AI. And besides, it also has some other technical limitations:

For that reason, Anton and Chao introduce the Storage-Partitioned Join:

Even though it works the same as the bucketed version, so perform a join operation without shuffle, it needs to address some extra challenges:
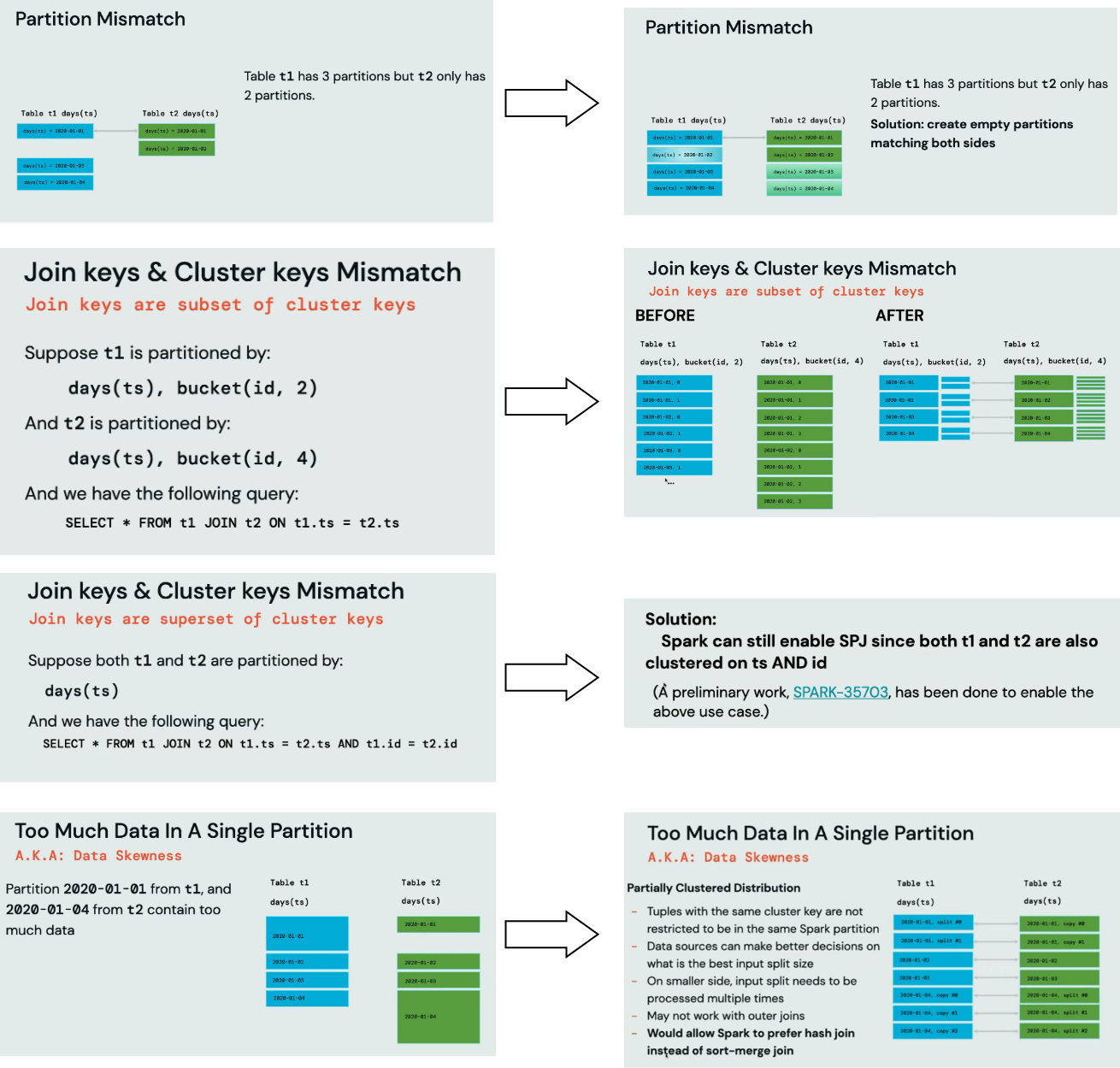
The overall impact of the Storage-Partitioned Join on the benchmarked query is huge:

🎬 Link to the talk: Eliminating Shuffles in Delete Update, and Merge.
Managing Data Encryption in Apache Spark™
Shuffle and optimization are not the single topics from the last Data+AI Summit. Another one is security, presented in the Gidon Gershinsky's talk about data encryption.
Gidon starts by explaining how the data encryption works for the data storage. You certainly find some of the concepts familiar if you have already worked with the encryption on the cloud but the talk targets one specific technology which is Apache Parquet.
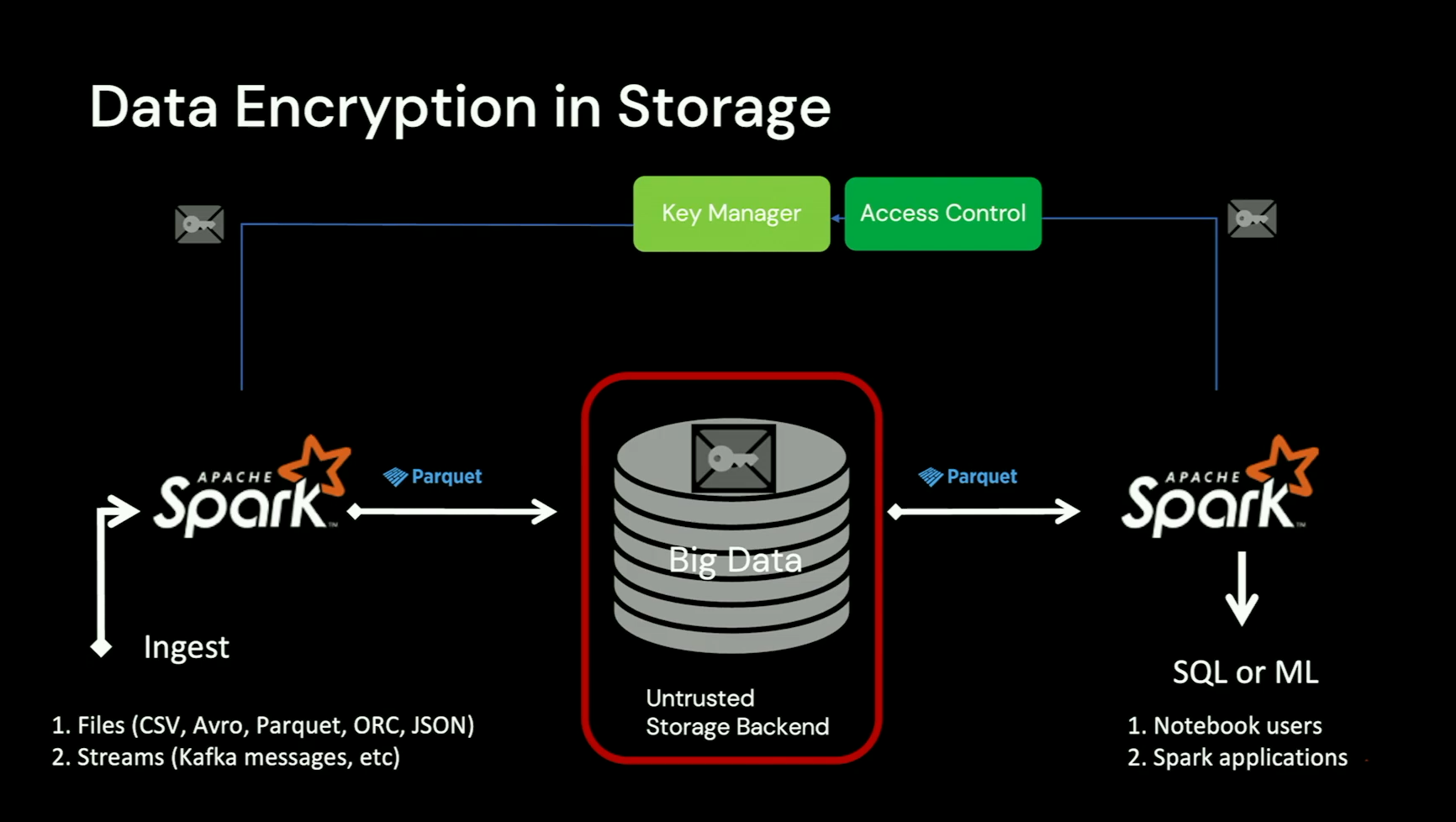
The first important thing to know is the scope and impact. Encryption in Apache Parquet applies to all data and metadata modules, and preserves all Parquet capabilities despite the encryption:

There is even more! The encryption can apply to a particular column as well making it one of the implementations for the data sharing:

Currently, this data sharing is a part of one of the available encryption modules greatly summarized by Gidon in this slide:

Besides, the encryption helps protect the data against tampering, including modifying data page contents, replacing one data page with another:

And most importantly, because it's a concern of many of us, the "Encryption won't be your bottleneck", as the cipher algorithms work in the CPU hardware:

Before talking about Apache Spark integration, Gidon explains another concept, the Envelope Encryption. The idea here is to use a Master Encryption Key to encrypt Data Keys that in their turn, are used to encrypt the data. A Data Key can be used for a file or even for a particular column. Because of this Master Key encrypts Data Key workflow, it's called Envelope Encryption.

Now, comes the Apache Spark integration. There are 2 integration modes, High-Level API, through Hadoop configuration and automatic Data Keys generation by Apache Parquet, or the Low-Level where you've more responsibilities. Apache Spark relies on the High-Level API approach, as presented in the slide:

Using the encryption requires then setting Hadoop configuration entries:

Besides these basic write-read operations, the integration has other capabilities, including columnar encryption and plaintext footer mode where the jobs without any access to the encryption keys can still access the footer and read the data:

🎬 Link to the talk: Managing Data Encryption in Apache Spark™.
Flink + Delta: Driving Real-time Pipelines at DoorDash
That's the talk I missed to add to my previous blog post about stream processing talks. I still don't know how it landed in this second part but anyway, let's see some great insight from Allison Cheng about the Delta Lake integration with Apache Flink!
First, she reminds some of the data lake issues solved with Delta Lake:

Next, Allison explains how to solve some common problems, starting with the small files issue. If you use Apache Flink, you can control the size with the checkpoint frequency:

But the checkpoint won't be enough. When the workload is low, the risk of creating small files still exists. Solution? The Flink Reactive Mode that adjusts the available compute resources:
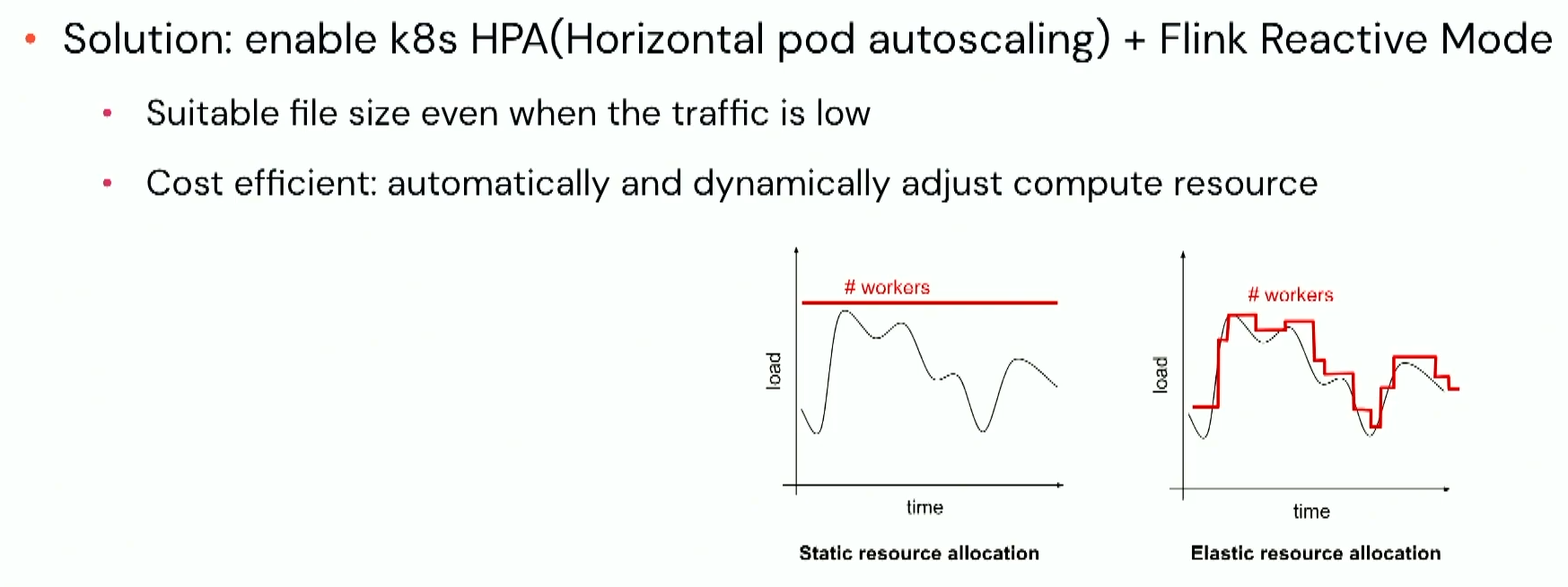
An interesting insight from Allison's talk is about using Apache Spark together with Apache Flink in a single system:
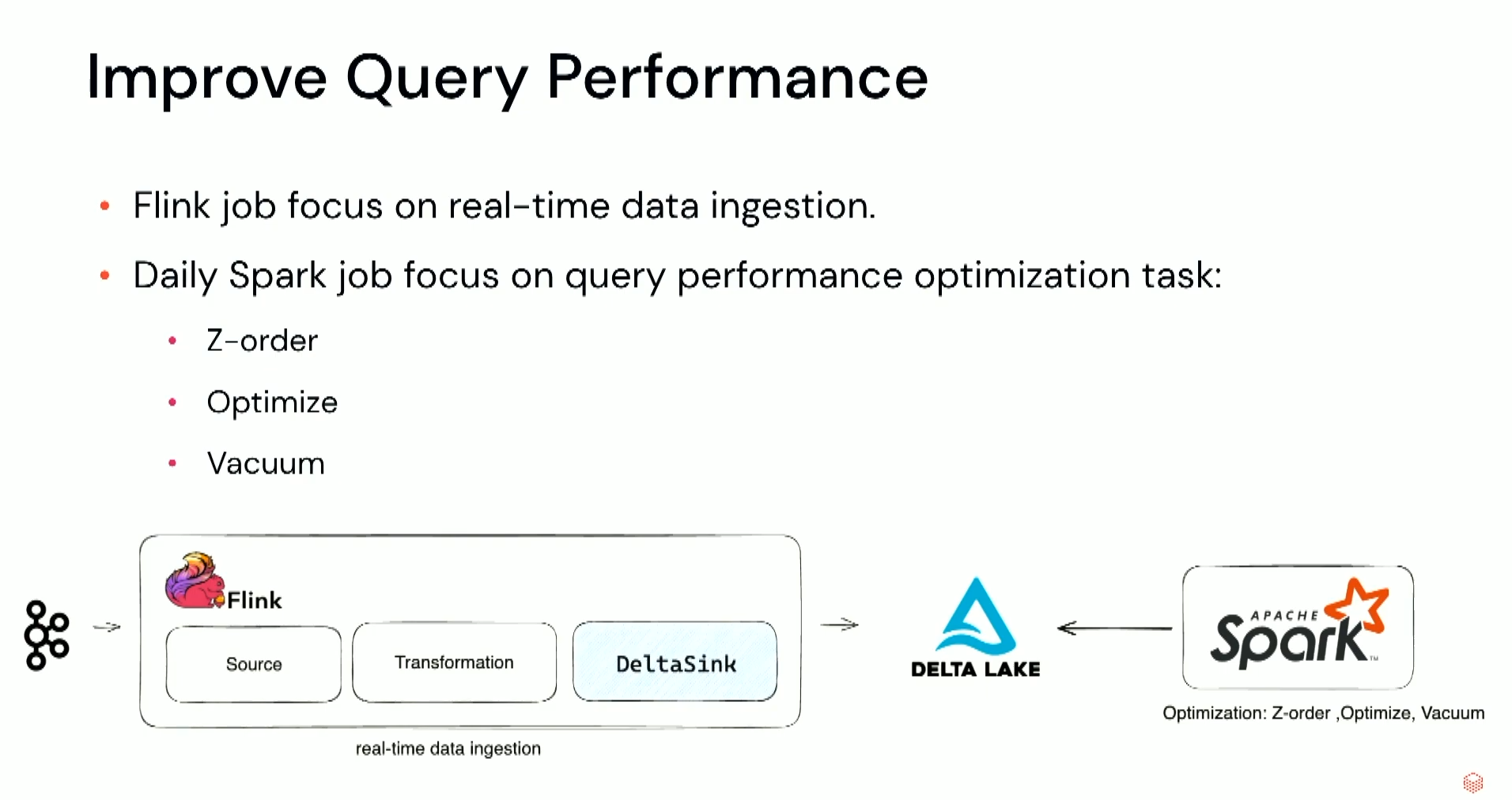
Another problem you might encounter with the Flink+Delta integration is Delta Lake checkpointing. Global committer can occasionally have CPU spikes due to the time spent on the checkpoint creation. It's now possible to skip this part in Apache Flink and let it in the maintenance tasks on Apache Spark side:

🎬 Link to the talk: Flink + Delta: Driving Real-time Pipelines at DoorDash.
Deep Dive Into Grammarly's Data Platform
To close my Data+AI Summit 2023 retrospective, let me share an interesting talk from Grammarly about their data architecture. Although you'll find the high-level view very familiar, you'll certainly learn a lot from the implementation details shared by Christopher Locklin and Faraz Yasrobi:
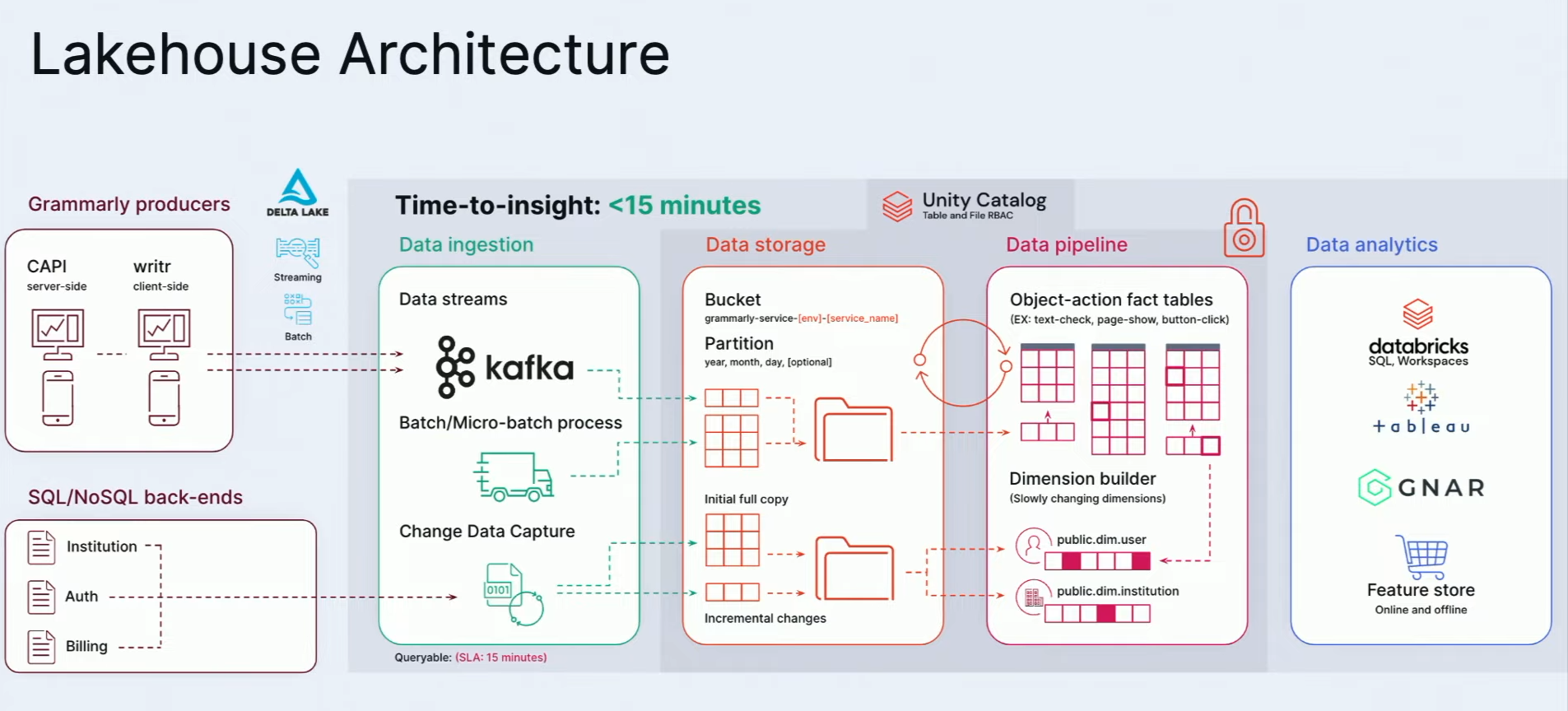
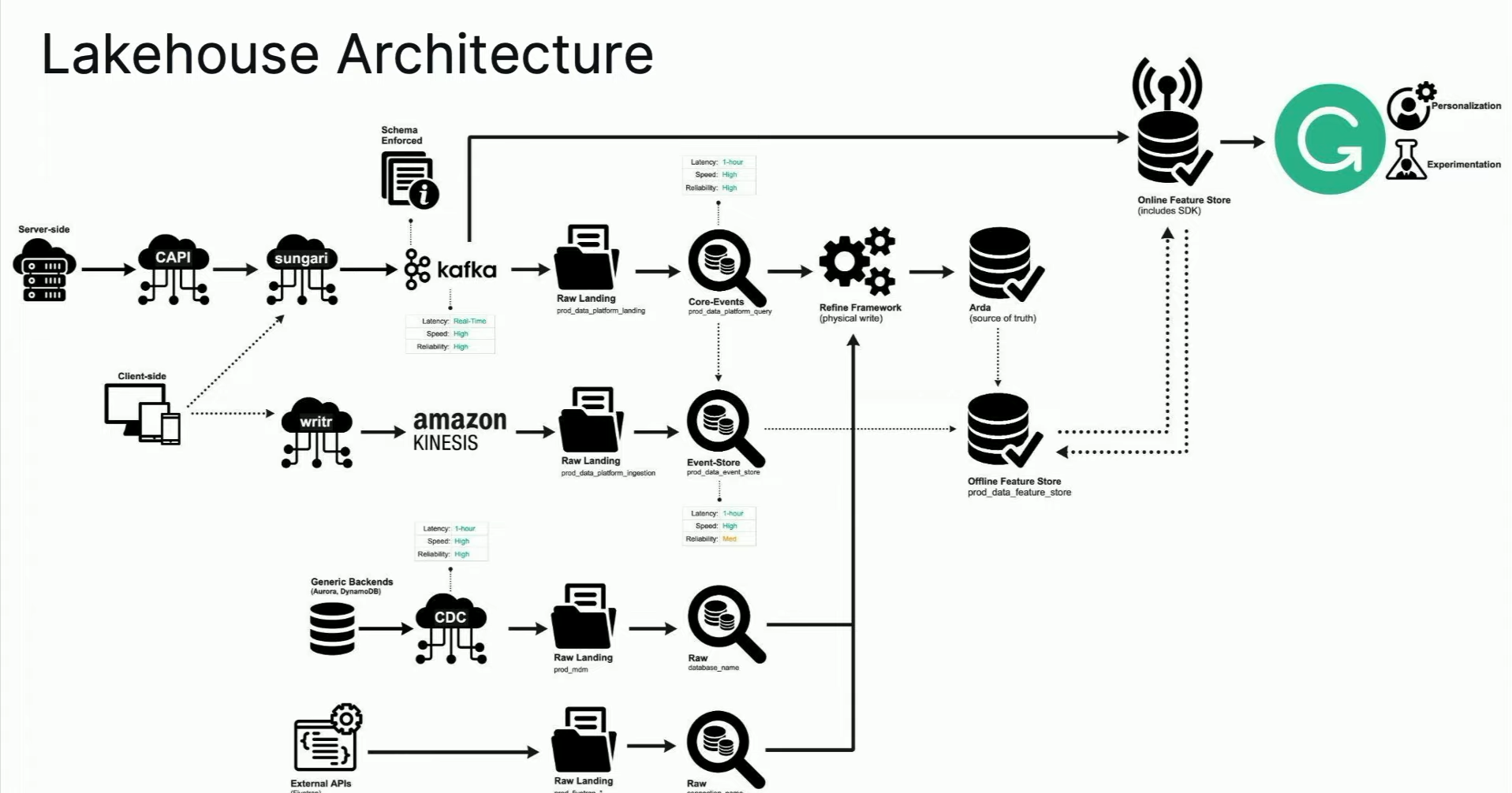
To deal with this, Grammarly uses a composable framework that the speakers perfectly summarized in this slide:
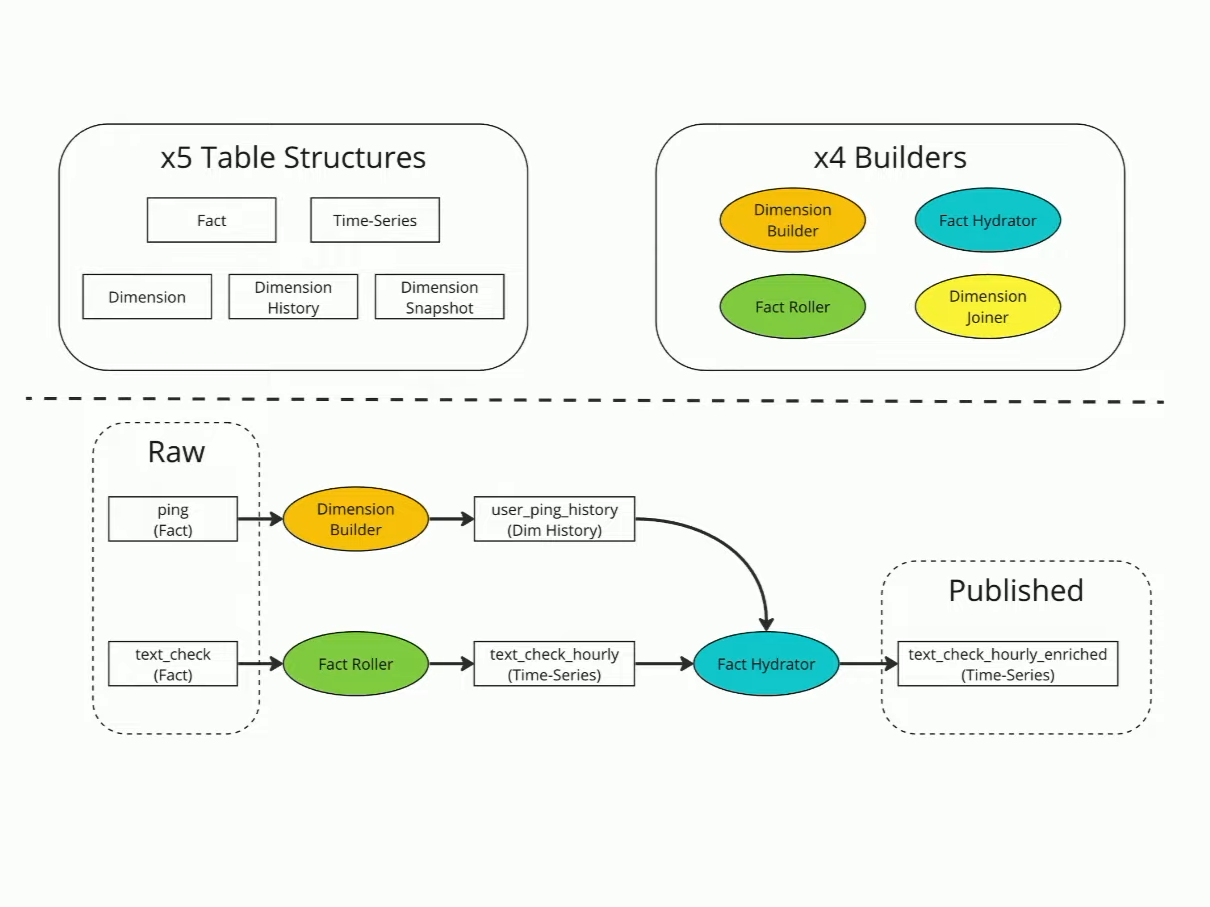
One of the interesting features of the builders is late data management with stateful processing.
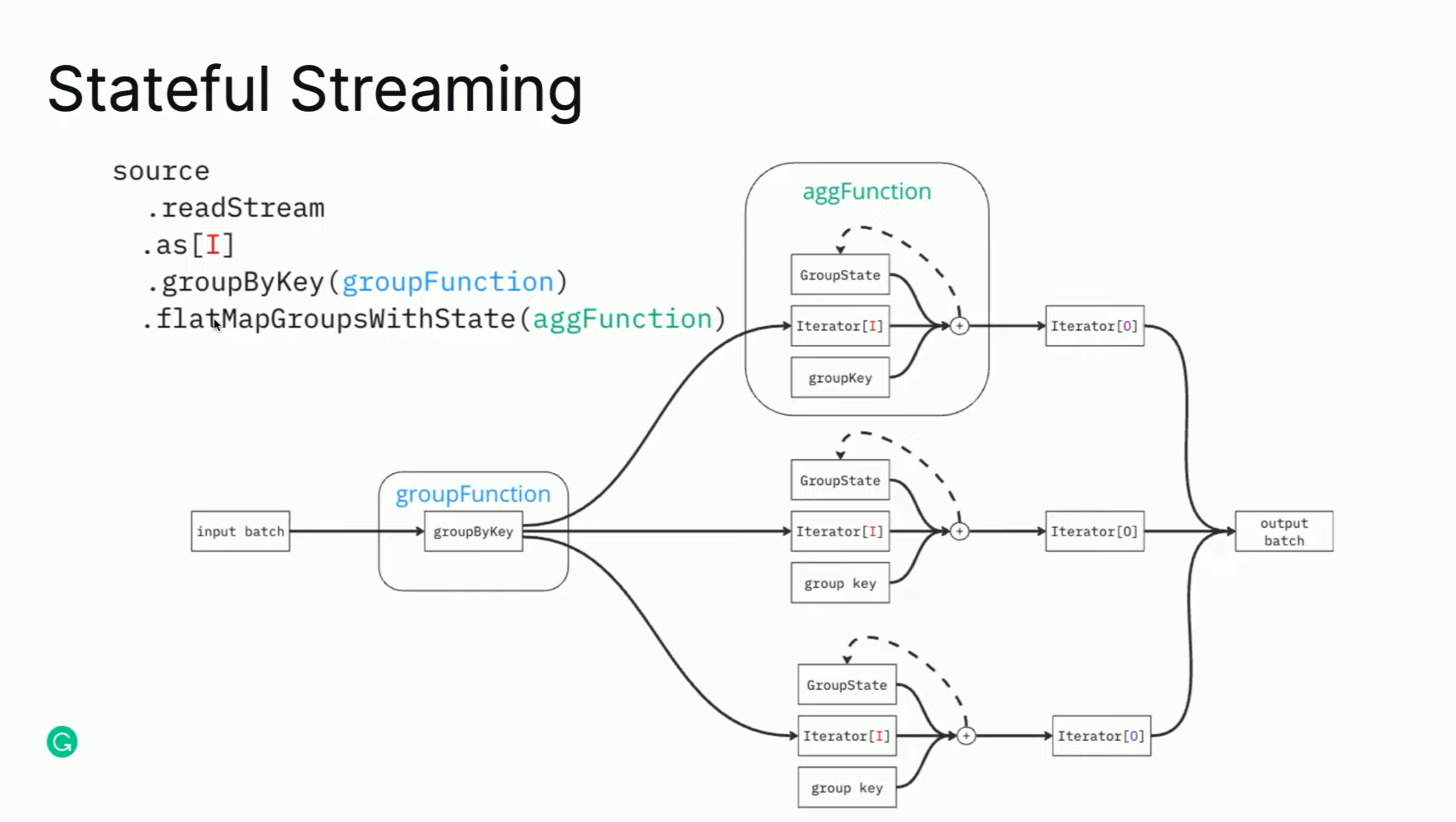
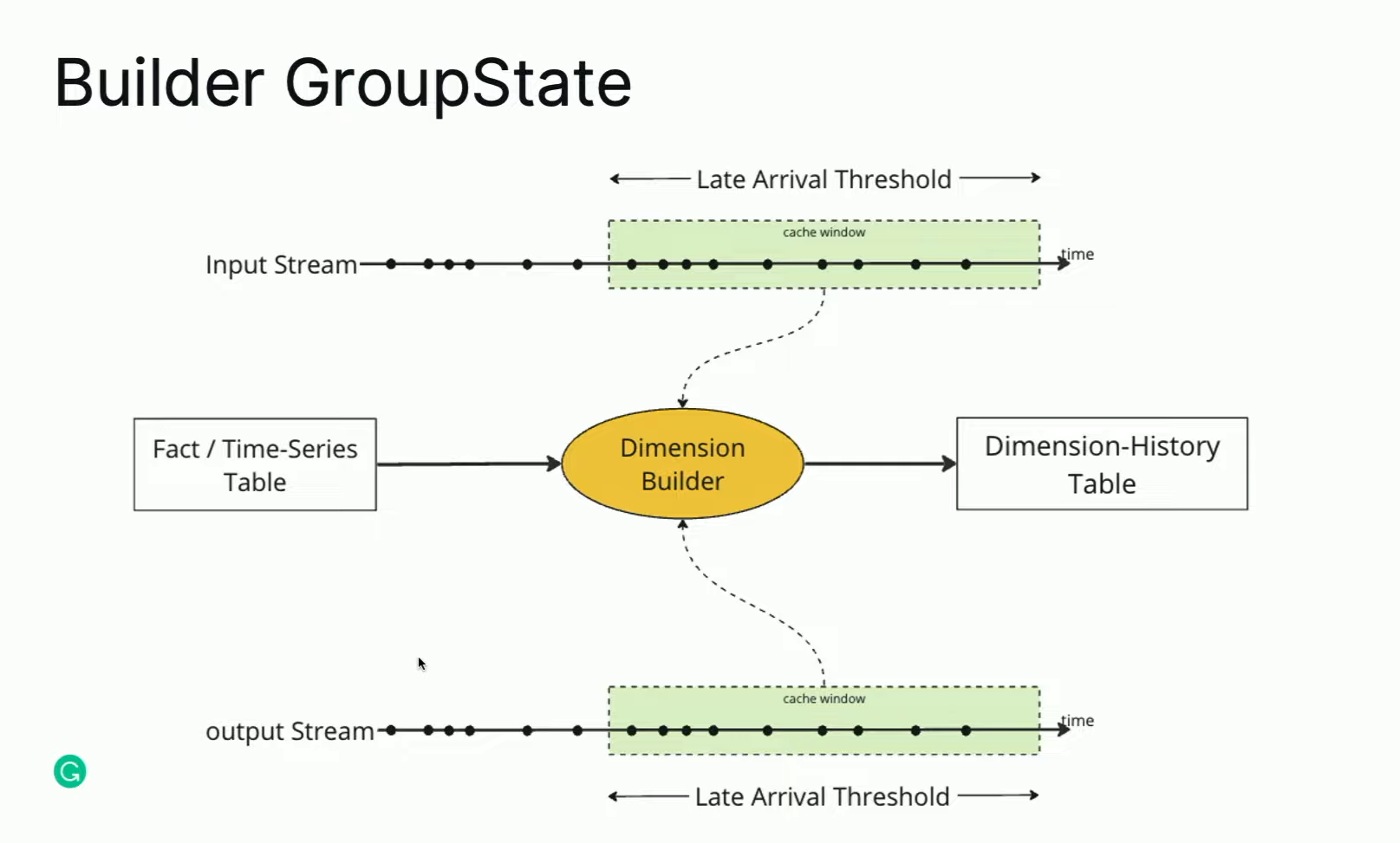
As you can see, each builder is a stateful job keeping some window open for integrating late data. The window size is defined as a part of the builder's API, as demonstrated here:

Among the 5 table normalized types you'll find:
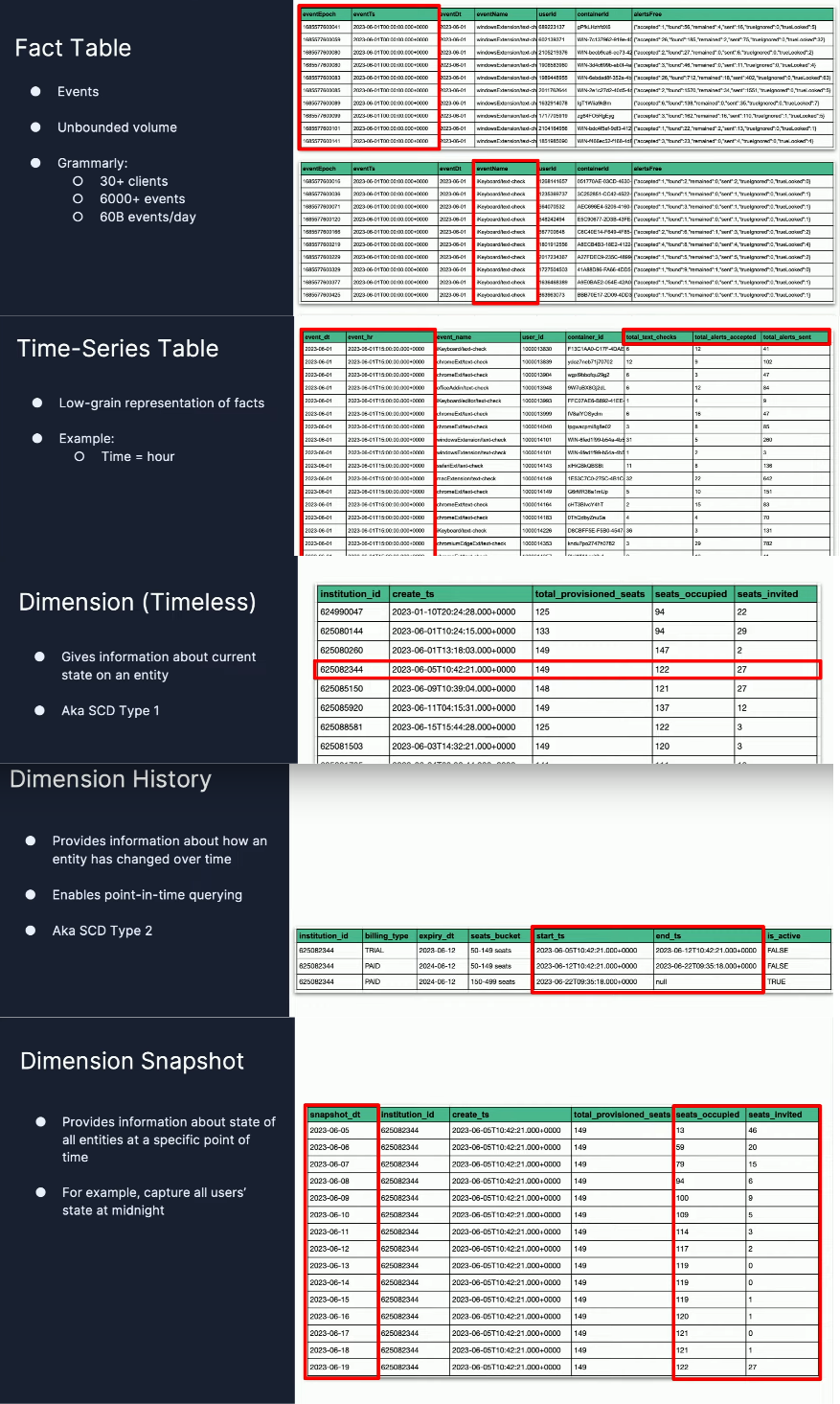
Each of them has a dedicated builder process:
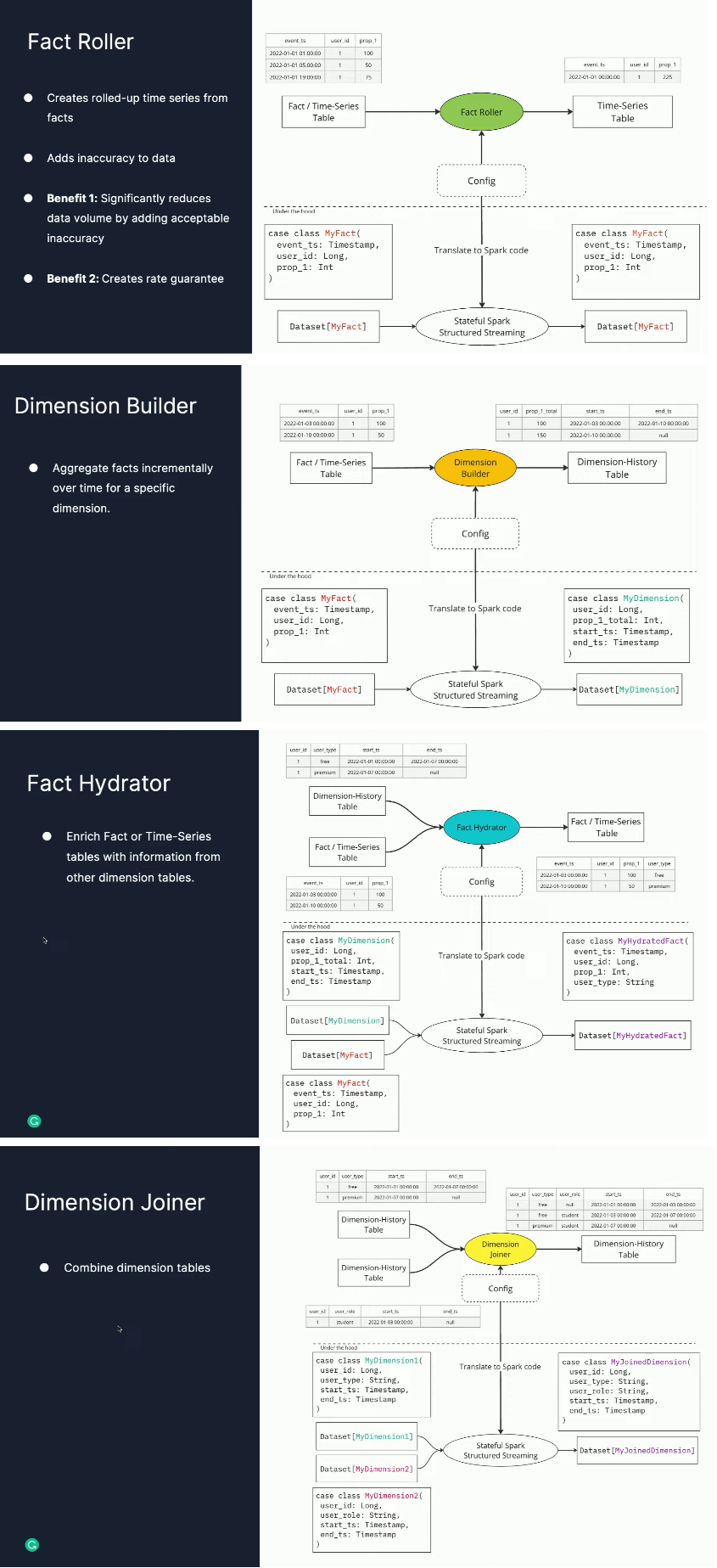
🎬 Link to the talk: Deep Dive Into Grammarly's Data Platform.
That's all for the 2023 edition. The next starts on June 10th!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- DAIS 2024: Orchestrating and scoping assertions in Apache Spark Structured Streaming
- Data+AI Summit 2024 - Retrospective - Apache Spark
- DAIS 2024: Testing framework from the Dataflow model for Apache Spark Structured Streaming
- Data+AI Summit 2024 - Retrospective - Streaming
- Data+AI Summit 2023, retrospective part 1 - streaming