
Yesterday I shared with you the human part of my Data+AI Summit. It's time now to give you my takeaways from the technical talks.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Unfortunately, I didn't see all the talks live. The Summit was my first in-person event of that size since Spark+AI Summit 2019 and was a rare chance to see many of my "virtual" friends IRL. Not knowing when will be the next occasion, I've decided to spend some time outside the talks and catch up on them offline, a bit like a batch layer in the Lambda architecture ;)
Data engineering
- Serverless Kafka and Apache Spark in a Multi-Cloud Data Lakehouse Architecture by Kai Waehner. The speaker is the Field CTO at Confluent so I was a bit worried about the eventual marketing-centric character of the talk. However, my worries weren't real because the talk was rather pragmatic, albeit not presenting a lot of technical low-level details. My takeaways are:
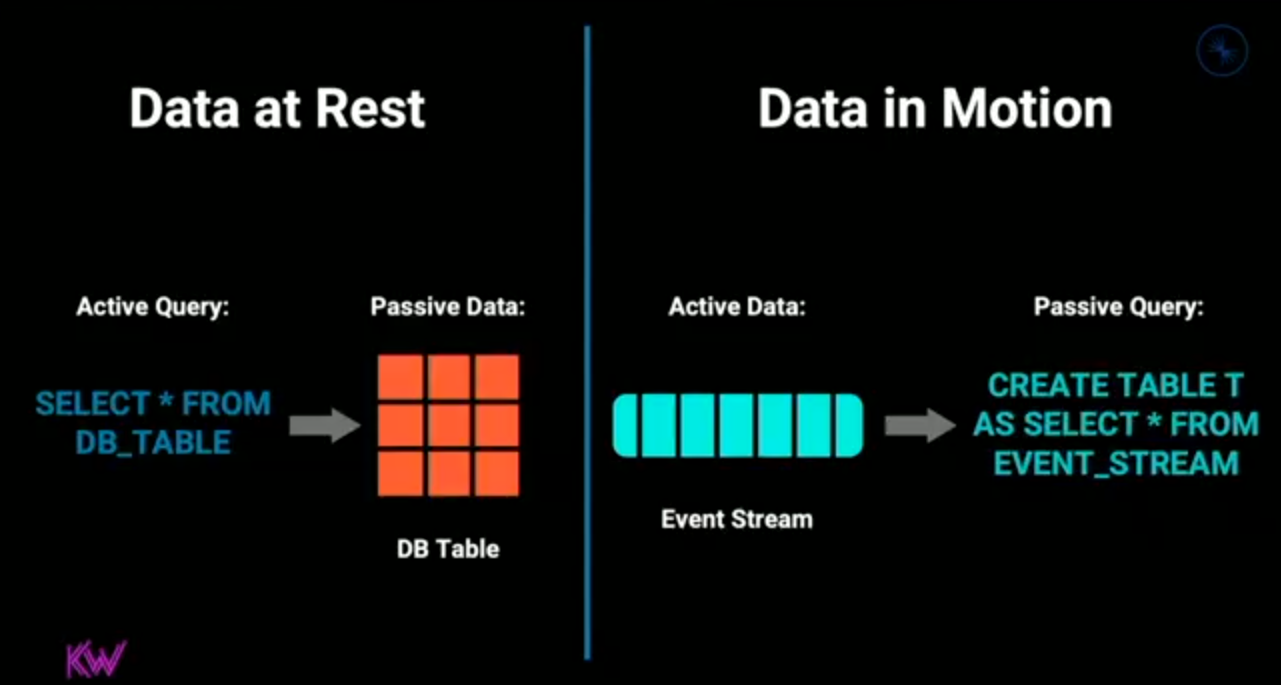
- Active Query and Passive Data vs. Active Data and Passive Query. That's an interesting vision for describing data at rest and data in motion. So far I have been reasoning in terms of data ingestion latency but this new term adds an extra and very important element to the equation, the query.
- Streaming is not the solution for every problem. There are still several relevant use cases for batch processing, like a weekly reporting or ML models training.
- Lakehouse is a logical view, not physical. Lakehouse is a pattern that can be generally applied to data architectures. It's not vendor-specific and Kai quoted the examples from the Keynotes with Lakehouse implementations on public cloud providers. He also mentioned a key aspect for each data and software project: you chose the particular technology to solve your problem. We might forget it seeing the marketing content in our space talking for example a lot about ELT and data analytics as the Modern Data Stack (Modern data stack. Am I too old?).
- Improve resilience. Kai also shared an interesting pattern he saw in the Connected Car Infrastructure at Audi. The architecture has 2 Kafka clusters to physically separate the responsibilities. The first cluster is responsible for data ingestion and it's a key piece of the system with a high SLA. It replicates the data to the second cluster with lower SLA that is the source for all data analytics and data science use cases.
- Active Query and Passive Data vs. Active Data and Passive Query. That's an interesting vision for describing data at rest and data in motion. So far I have been reasoning in terms of data ingestion latency but this new term adds an extra and very important element to the equation, the query.
- Backfill Streaming Data Pipelines in Kappa Architecture by Xinran Waibel and Sundaram Ananthanarayanan. That's probably the talk I was most excited about. I remember an Uber's blog post about reprocessing data in Kappa architecture and was really curious to see how Netflix does this hard task. I wasn't deceived!
- The first of 3 backfilling strategies is replaying from the main data source. In other words, you change Apache Kafka offset in the job and replay. However, it has some drawbacks like the latency or costs ($93M for storing 30 days of Netflix apps data in Kafka!).
- The 2nd solution is to use Lambda architecture.. So instead of having a single streaming pipeline, we add one batch pipeline for data reprocessing. It's more cost-effective but adds some extra complexity to the codebase.
- The 3rd option is to use the unified API for batch and streaming. The solution addresses the previous codebase issue but it's not perfect either. Unfortunately, the batch and streaming APIs are not always up-to-date, especially when it comes to the complex streaming features like stateful processing?
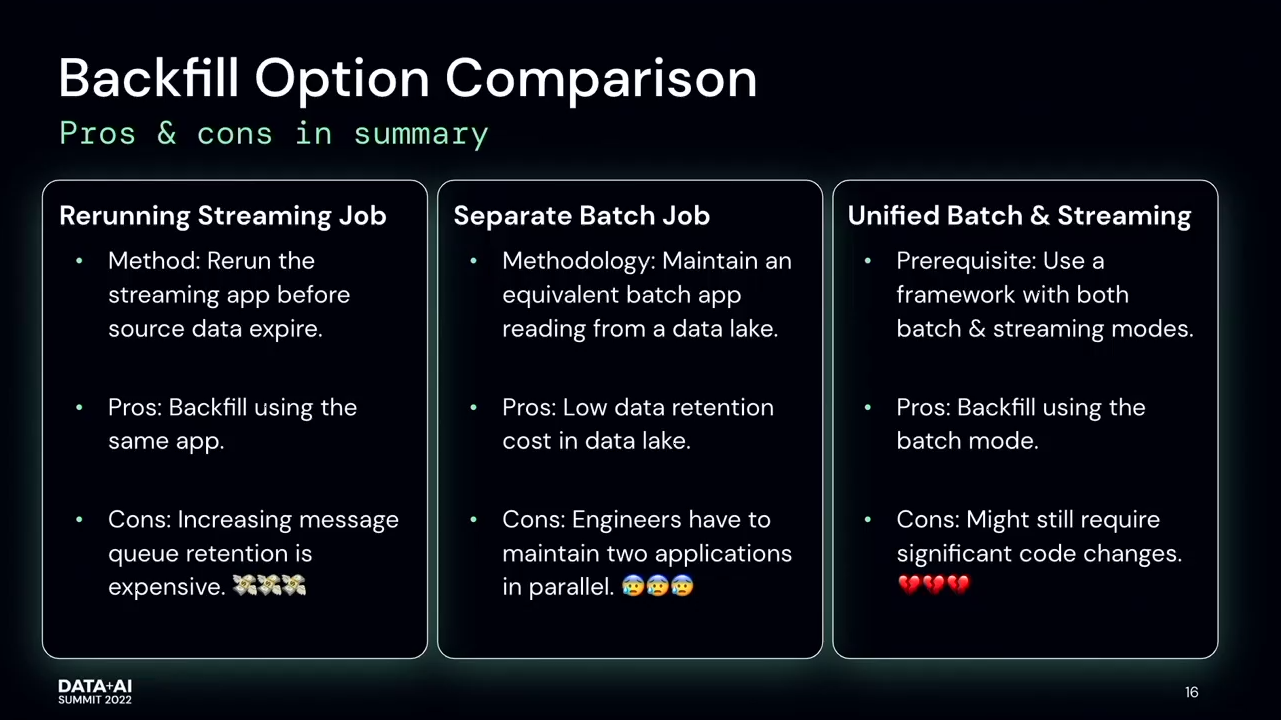
- The solution?. Combine all these 3 worlds, so reprocess data from the data lake with the streaming API.
- Learn to Efficiently Test ETL Pipelines by Jacqueline Bilston. An amazing talk about how one inexplicable data issue led to data tests improvement with the Saff Squeeze method.
- There are 2 types of tests: data tests and logic tests. Data tests verify data quality, so the things like nulls or duplicates in the dataset. The logic tests, on the other hand, are unit and integration tests ran against test datasets in the code.
- Big test case might be the source of your future problem. Jacqueline spotted out that a big test case trying to cover as many variations of the job's input data as possible, was the reason why the regression was detected only by the data customers. She proposed fine-grained tests that are much more readable and efficient.

- Saff Squeeze. It's a method to create simpler tests based on the big test.

- Tip#1: use meaningful ids. If your test dataset has some ids, you don't need to use mysterious values or numbers. If the id is a string, you can use a more meaningful value to the tested case, such as "filtered_out_product" if we would like to test a function filtering the products.
- Tip#2: make the assertions specific to the test. Try to focus on the assertions targeting only the changes generated by the tested method.
- Tip#3: prefer bug-specific test cases. It's hard to figure out what happens for one large test trying to cover multiple bugs. It's better to isolate, even though you'll end up with much more test functions. The good thing is that you'll clearly see the failed feature in the CI/CD or local build process. Otherwise, you'd need to dig into the test and find the issue by yourself.
- Beyond Monitoring: The Rise of Data Observability by Barr Moses. An interesting talk with a great reminder about this important "data monitoring" aspect. Among the things to remember:
- Data issues are often detected by data consumers. It reduces their trust in the data. It also wastes data engineers energy to fix the problems and backfill the pipelines.

- Data observability equation is metrics + traces + logs. It's an equation easily solved by software engineers. Unfortunately, data world has still some catch-up to do.
- Discover → Resolve → Prevent is the lifecycle of solving a problem through Data Observability. It doesn't mean the data will be always perfect but that it'll be easier to control.
- Data observability pillars are: Freshness (e.g. table without data or with late data), Distribution (e.g. a lot of null values), Volume, Schema, Lineage (e.g. can help better identifying the impact of data issues) .
- Data issues are often detected by data consumers. It reduces their trust in the data. It also wastes data engineers energy to fix the problems and backfill the pipelines.
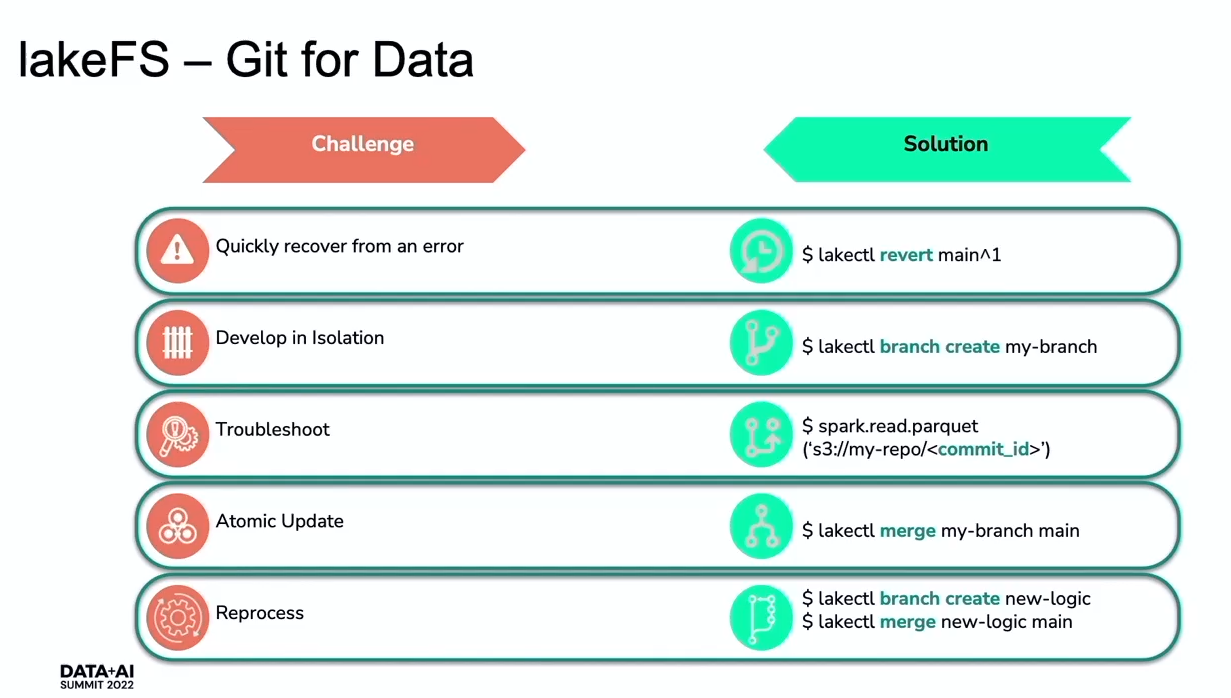
- Chaos Engineering in the World of Large-Scale Complex Data Flow by Adi Polak. If you don't know lakeFS, you definitely should watch this talk! Adi starts by adapting Chaos Engineering from the software world to the data and in the end shows how to solve its common problems in a Git-like way using lakeFS:
- Chaos Engineering in the data traduction means these 4 steps: Steady State (= Data product requirements such as data quality, accuracy, duplicates, SLA), Vary Real-World Examples (= in the data world we can encounter schema changes, data corruption, data variance), Experiments on Production (= use production data), Automated Experiments (= manage data lifecycle in stages).
- Data lifecycle stages for automated experiments are: Development (experimentation, debugging, collaboration with other engineers/teams), Deployment (version control, best practices and data quality insurance), Production (rollback in case of an unexpected failure to troubleshoot the issue and still exposing relevant data).
- How to handle these stages? With Git...for Data. lakeFS is a tool providing the answer to a lot of data lifecycle questions. The summary is just below:
- Data Lakehouse and Data Mesh - Two Sides of the Same Coin by Max Schultze and Arif Wider. The talk includes 2 hot concepts of the data space of the moment. I couldn't miss it!
- Max recalled 3 main building blocks of a Lakehouse: data lake storage layer, metadata & data governance layer, and finally support for both BI & ML use cases. The implementation at Zalando looks like in the following schema.

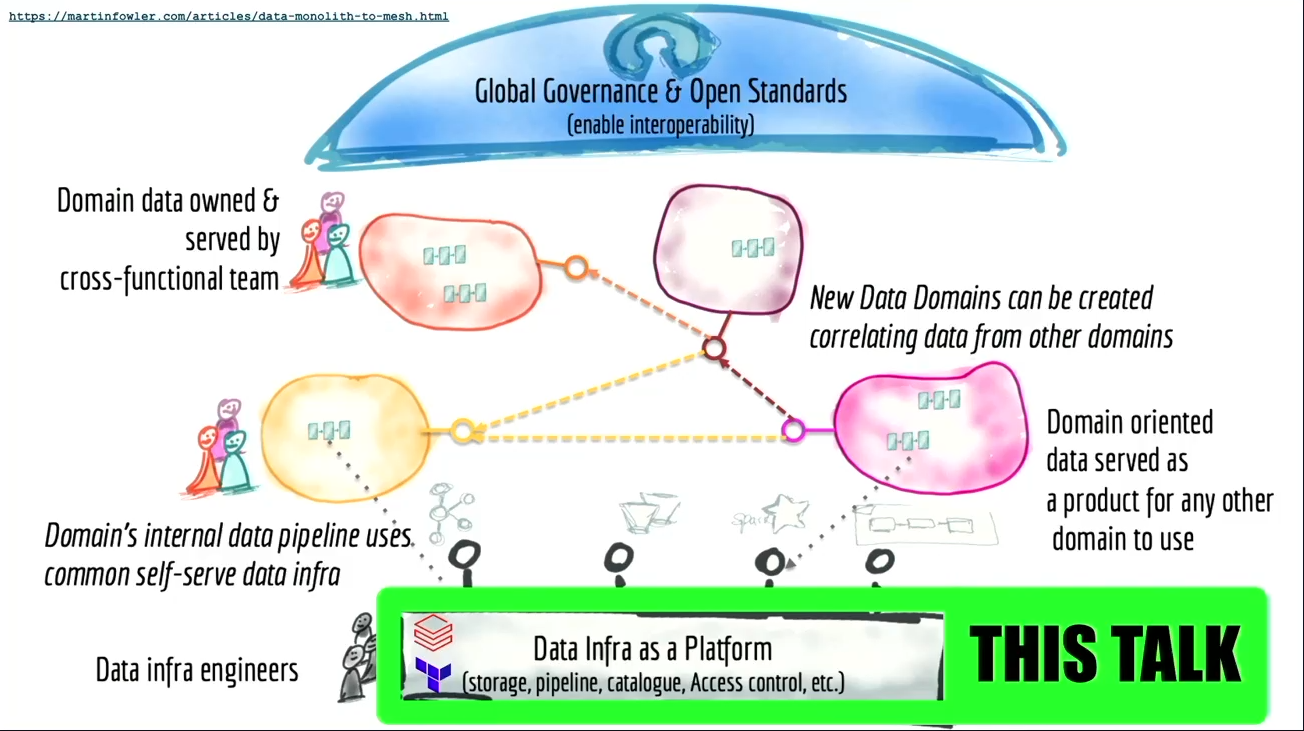
- Arif on his turn, gave the definition of Data Mesh. His picture is more than self-explanatory!

- "Data Mesh is about solving problems with people", so it's more an organizational approach whereas Lakehouse is a technology-based solution.
- Despite addressing data problems from different angles, Data Mesh and Lakehouse can't work alone.

 .
.
- Max recalled 3 main building blocks of a Lakehouse: data lake storage layer, metadata & data governance layer, and finally support for both BI & ML use cases. The implementation at Zalando looks like in the following schema.
- The Road to a Robust Data Lake: Utilizing Delta Lake and Databricks to Map 150 Million Miles of Roads a Month by Itai Yaffe and Ofir Kerker. Itai and Ofir explained how data ingestion changed between 2019 and 2022. Despite using a managed option, they wrote some specific code to deal with small files:
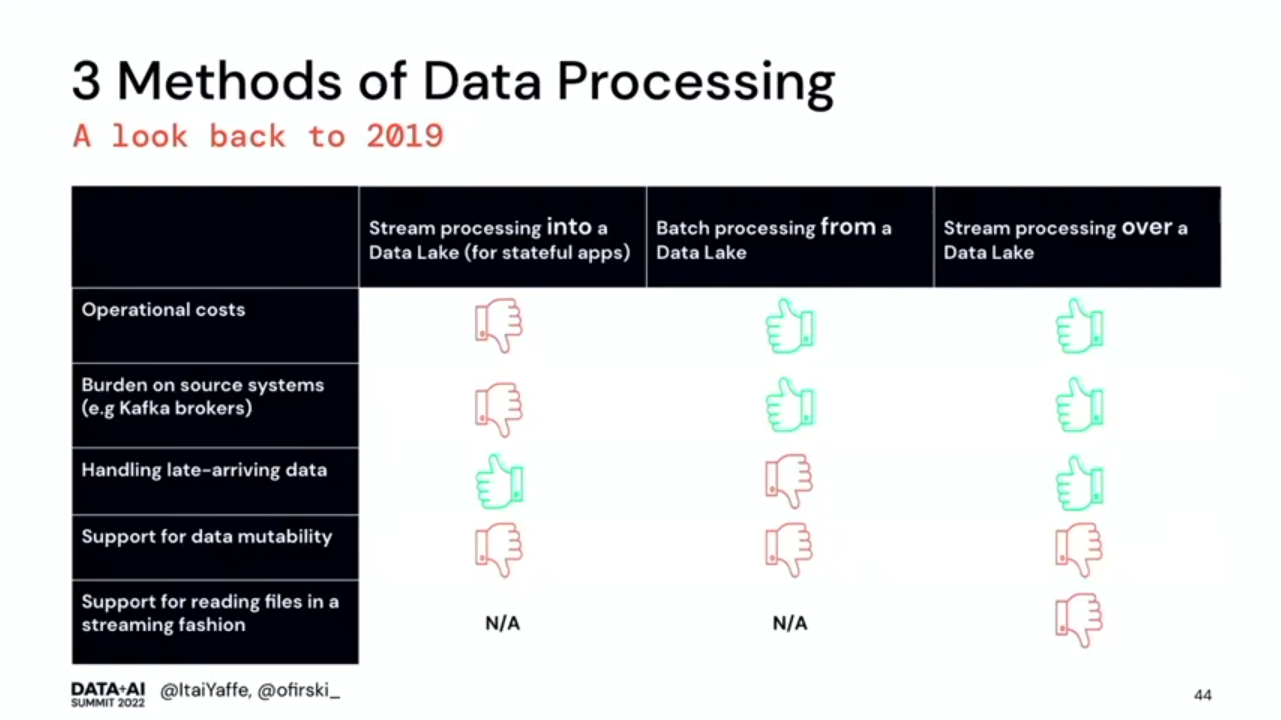
- Back in 2019, there were 3 data processing methods of the data lake: stream processing into a data lake, batch processing from a data lake, and streaming processing over a data lake.
- Stream processing into a data lake has 2 faces. The stateless face brings fresh data but the stateful one (e.g. aggregations) increases operational costs.
- Batch processing from a data lake addresses the operational cost issue but it's not perfect either. We have a little knowledge about the incoming data and the time when we can start processing it.
- Streaming processing over a data lake sounds better but it also has some drawbacks. In 2019 there was no mature support for reading files in streaming fashion. The technologies also lacked the support for data mutability. The recap of the 3 methods is just below.
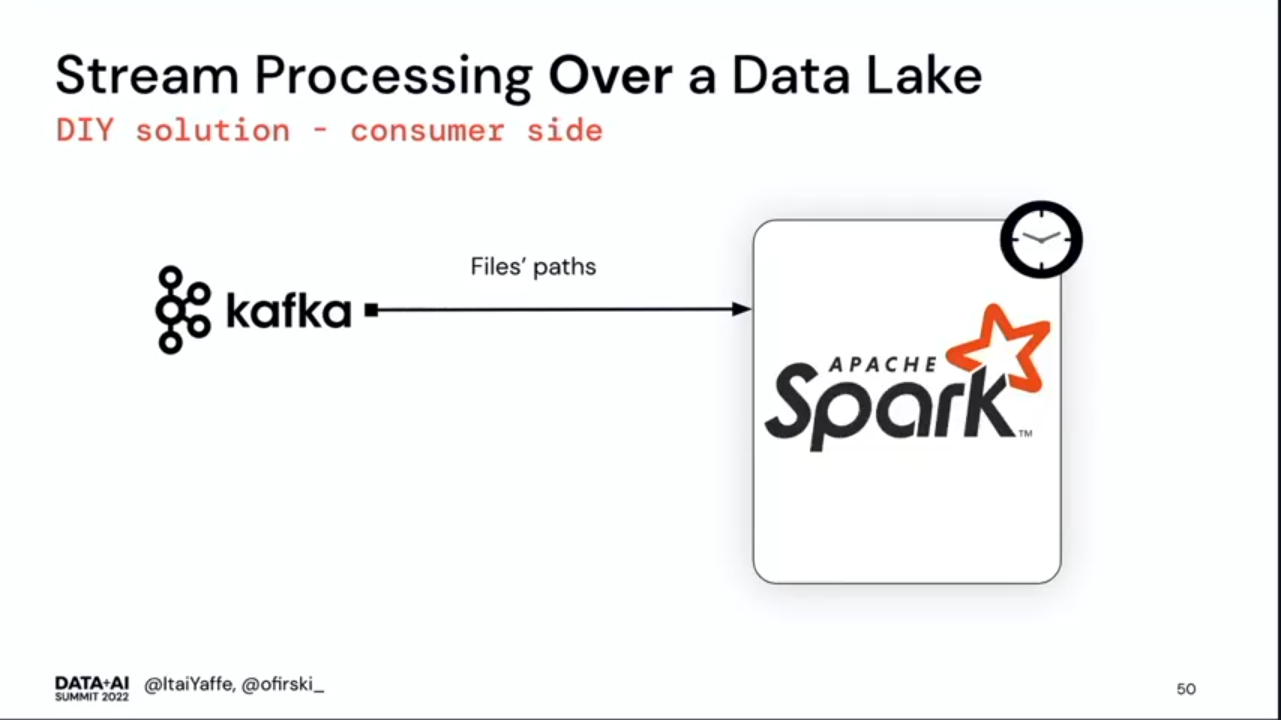
- There was a solution to implement the streaming processing over a data lake in 2019, though. The data synchronization job between Kafka and data lake was delivering messages with new created files to another Kafka topic, as in the schema below:
- Autoloader is the solution for that in 2022. The 2019 solution had to be maintained by a small development team whereas the Databricks Autoloader is a fully managed solution that facilitates the work.


- Automate Your Delta Lake or Practical Insights on Building Distributed Data Mesh by Serge Smertin. If you're missing some IaC view on your Data Mesh organization, this talk can answer some of your problems!
- Serge presents a lot of infrastructure patterns to implement the data platform part of the Data Mash. It's hard to list them all, but you'll find the examples for users, libraries, or security.
- How to start with a Data Mesh IaC stack? Start small but fully automated! So that even if you have to add new domains, you'll be able to do it quickly and painlessly. A quote I liked from his answer particularly is "well structured monolith is better than microservices mess".
- Serge presents a lot of infrastructure patterns to implement the data platform part of the Data Mash. It's hard to list them all, but you'll find the examples for users, libraries, or security.
Apache Spark
- Improving Apache Spark Structured Streaming Application Processing Time by Configurations, Code Optimizations, and Custom Data Source by Kineret Raviv and Nir Dror. The speakers shared their experience with Apache Spark by Akamai. That was the first (but not the last) time at the Summit when I saw a custom data source in a business project! The takeaways:
- Data source. The job reads an Apache Kafka topic with JSON messages. Each message contains a name of the object on Azure Blob Storage, its size and number of rows.
- Dynamic lag management. When the job is far behind the most recent offset (catch-up mode), the data source polls as much data as it can. The limit is the memory reserved for the micro-batch. Additionally, in that scenario, the data source can increase the parallelism and use more tasks than in the normal mode.
- GCEasy. It has been a while since I analyzed GC logs. That's probably why I've missed GCEasy which is an online GC analysis tool with a free tier.
- Heap size after Garbage Collection. If it increases, it can be an indication of potential memory leaks.
- What to Do When Your Job Goes OOM in the Night (Flowcharts!) by Anya Bida and Holden Karau. Very interactive talk about a handy tool helping to solve OOM in the middle of the night. Anya and Holden showed how to transform Flowchart into an efficient debugger tool. Nothing better to see the tool in action! You can also extend the repo and use it in the "private" mode, so include some features or observations specific to your organization.
- Recent Parquet Improvements in Apache Spark by Chao Sun. In his talk, Chao presented the last changes in the Apache Parquet data source. Although we hear more and more about ACID file formats, Apache Parquet is still the backbone of data analytics file formats, including the ACID ones. Here are my takeaways from the talk:
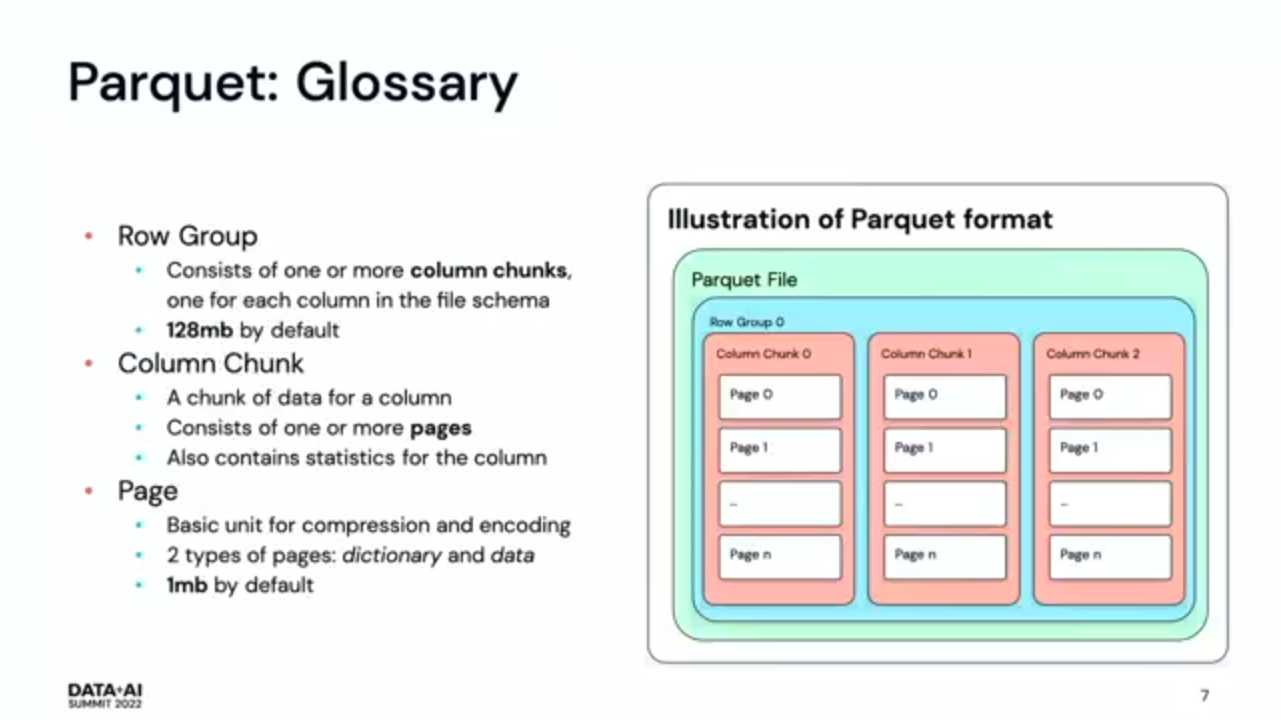
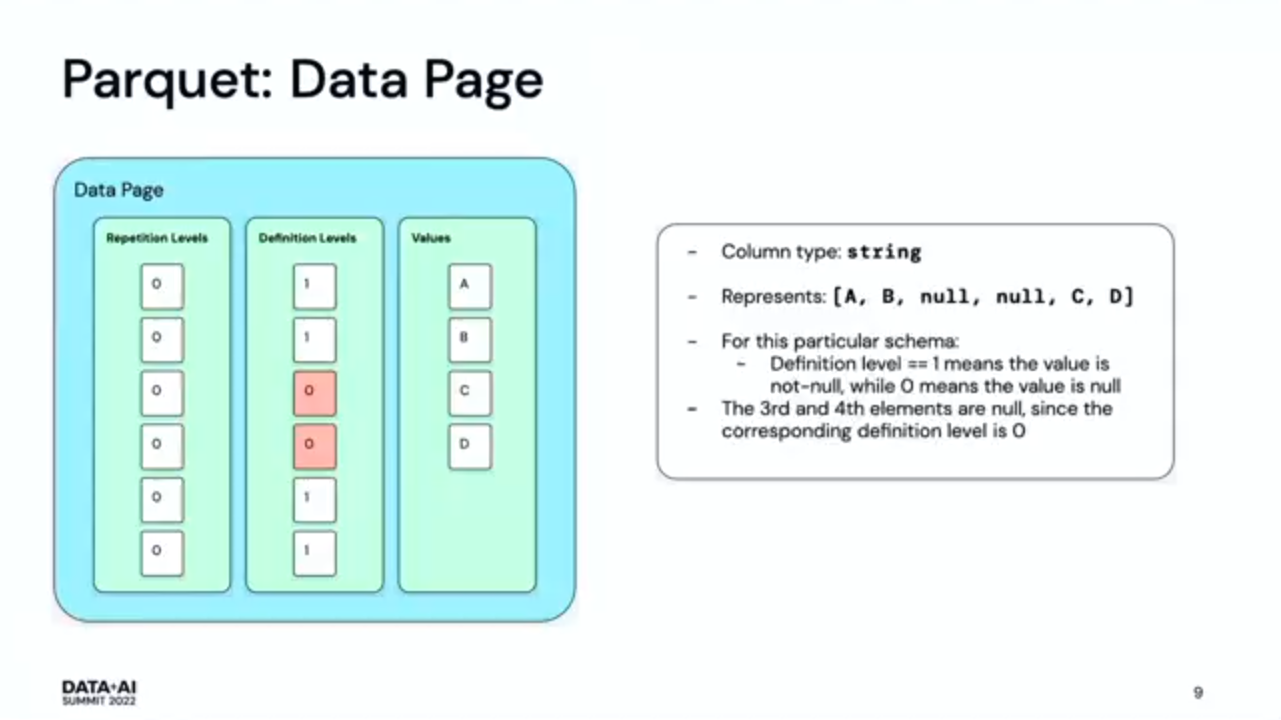
- Apache Parquet 101. It was great to have a quick reminder about Apache Parquet components. Row group has one or multiple column chunks that consist of one or more pages:
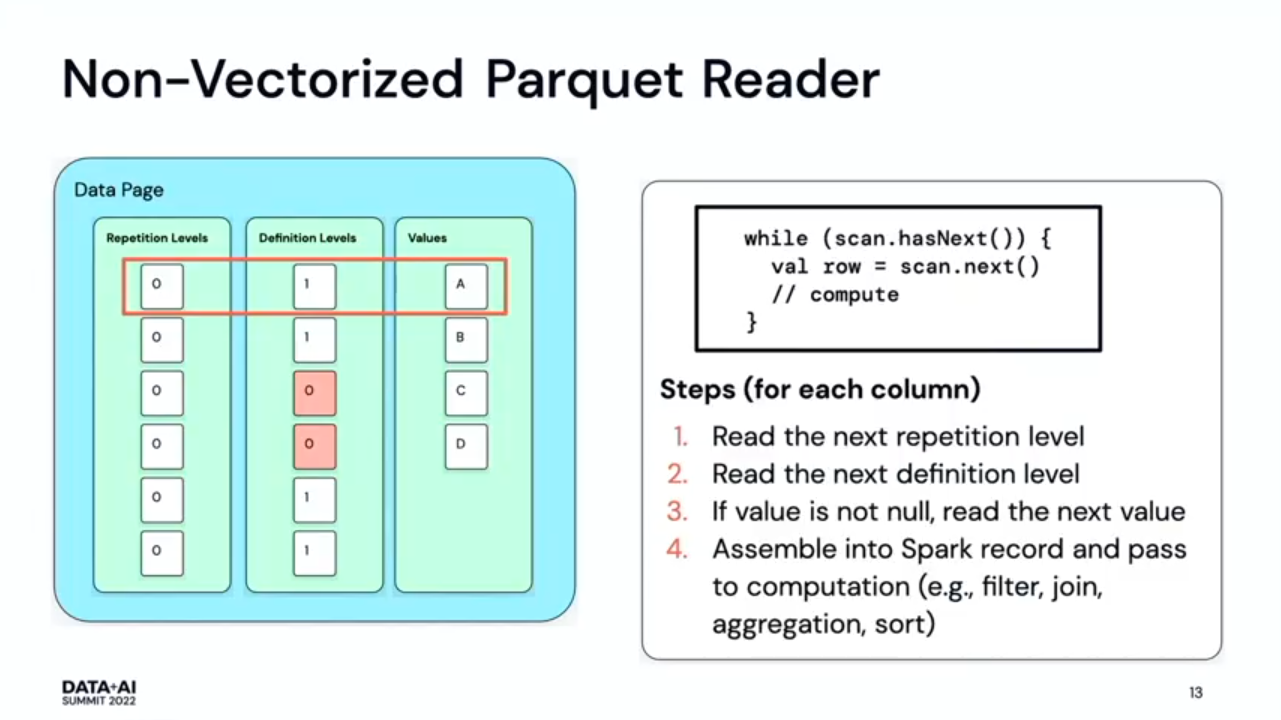
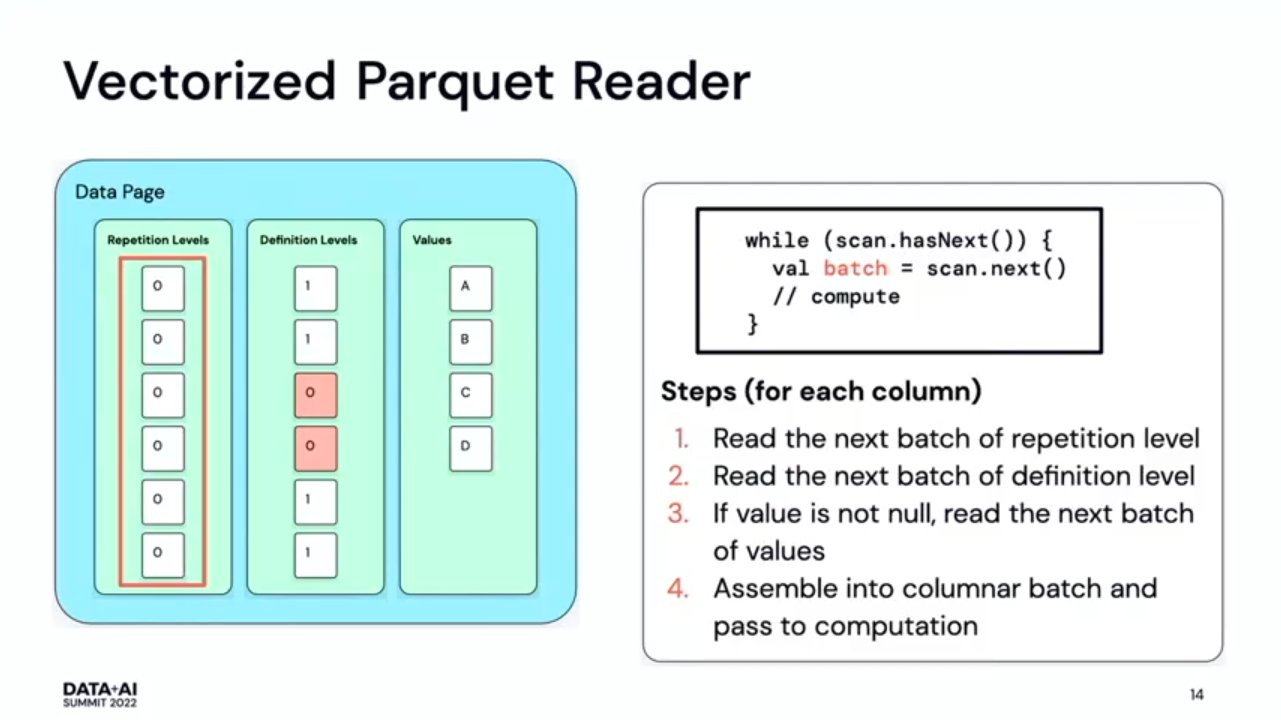
- Apache Parquet on Apache Spark 101. Another great summary was about non vectorized and vectorized Apache Spark readers for Parquet files. The slides are better than my words to explain the differences:
- Apache Spark 3.3.0 supports complex Apache Parquet types, like lists, maps and structs. You can find more details in SPARK-34863..
- Apache Parquet column index support was already available in Apache Spark 3.2.0. It skips data pages using the page and not row groups statistics.
- Apache Parquet 101. It was great to have a quick reminder about Apache Parquet components. Row group has one or multiple column chunks that consist of one or more pages:
- Spark Inception: Exploiting the Apache Spark REPL to Build Streaming Notebooks by Scott Haines. I've been a notebook user for a while already. They're great for data exploration tasks, especially the first days of each new project or to quickly prototype the job. However, I've never been wondering how they work under-the-hood. Fortunately, Scott did it and shared his findings and the code (!) in the talk. My takeaways are just below but if you're hungry, you'll find more tasty details in the spark-inception repo.
- Notebooks are kind of "on-the-fly data engineering" is one of the best definitions of notebooks I've heard. They're interactive, so useful to test an idea quickly and interactively without the cluster setup overhead.
- The notebook's architecture uses Redis to store the notebook commands and results. The solution uses an Apache Spark Structured Streaming job as an RCP channel to send the commands and data back and forward.
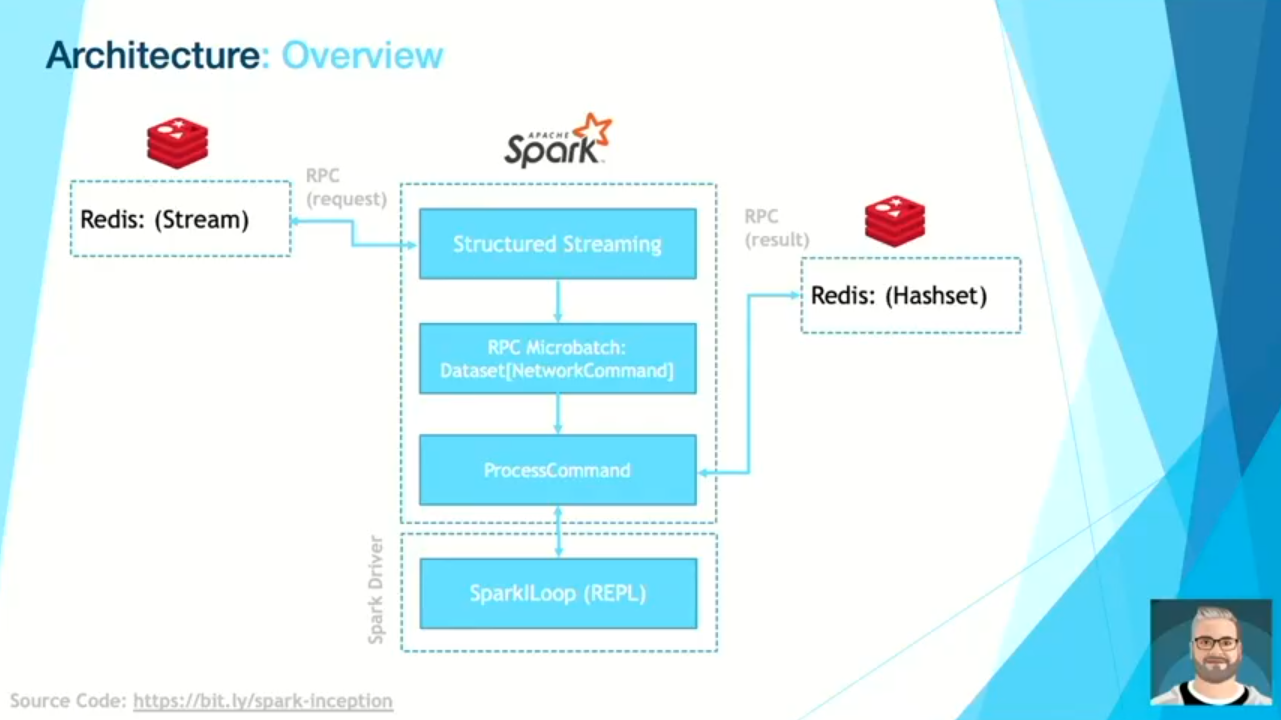
- SparkILoop. It's the class invoked by Spark Shell in Apache Spark REPL. In the streaming notebook solution, Scott uses it to evaluate the input Spark API commands coming from the Redis Stream. The SQL commands, which are another supported input, are on their side, evaluated by SparkSession's sql(...) method.
- The workflow is very intuitive. Redis CLI replaces the input cells of the notebook. All the commands are streamed live to the Structured Streaming job that extracts the user's command and passes it to the processCommand method which under-the-hood runs from an foreachBatch sink. The input gets executed inside the sink and the evaluation results are written back to the Redis table.
- DELETE, UPDATE, MERGE Operations in Data Source V2 by
Anton Okolnychyi. Fun fact about this session is that at the same time I was preparing the blog post about Data Source V2 changes in Apache Spark 3.3.0. It turns out that the DML operations from the talk were added in this specific version! Although I'll put more technical details in the blog post, you can see some general takeaways just below:
- "Legacy" way to overwrite data in distributed systems is error-prone, complex, slow, and resource-intensive. In this mode, the job filters out the changed/deleted rows of the table/partition and generates new files in-place. It also brings the risk of data corruption if the writing process fails in the middle.
- "New" way leverages ACID file formats that provide compliance and performance..
- Before the version 3.3.0, Apache Spark was only resolving the DML operations.. The physical execution went to the SparkSession extensions. It changes in the 3.3.0 release thanks to the SPARK-35801 that supports a standardized execution and the data source must only implement the interfaces.
- Write amplification. It's a term describing too heavy write, i.e. the situation where a delete operation has more data to write than to remove.
- Only deletes are implemented so far in Apache Spark. The framework supports the delete version overwriting the files. An alternative approach adds only the modified data to the current dataset and delegates the main workload to the readers.
- PySpark in Apache Spark 3.3 and Beyond by Hyukjin Kwon and Xinrong Meng. It's a good occasion to learn how PySpark will change in the next releases:
- Apache Spark 3.3.0 added a new support for default index that improves Pandas workloads execution time by up to 3x. This new strategy works on top of the JVM to avoid the serialization/deserialization overhead loop.
- Types integrated in the code base. Previously they were defined in the .pyi files. Now, they're part of the standard Python files.
- The next major release should bring the features like: better coverage for Structured Streaming, Arrow-based local DataFrame, and some important Py4J improvements following the organizational change in the project.
- An Advanced S3 Connector for Spark to Hunt for Cyber Attacks by Ada Sharoni and Wojciech Indyk. That's the second time at this Summit when I saw a custom data source directly integrated to the business application!
- The reason for a custom data source was slow objects listing in a huge bucket.
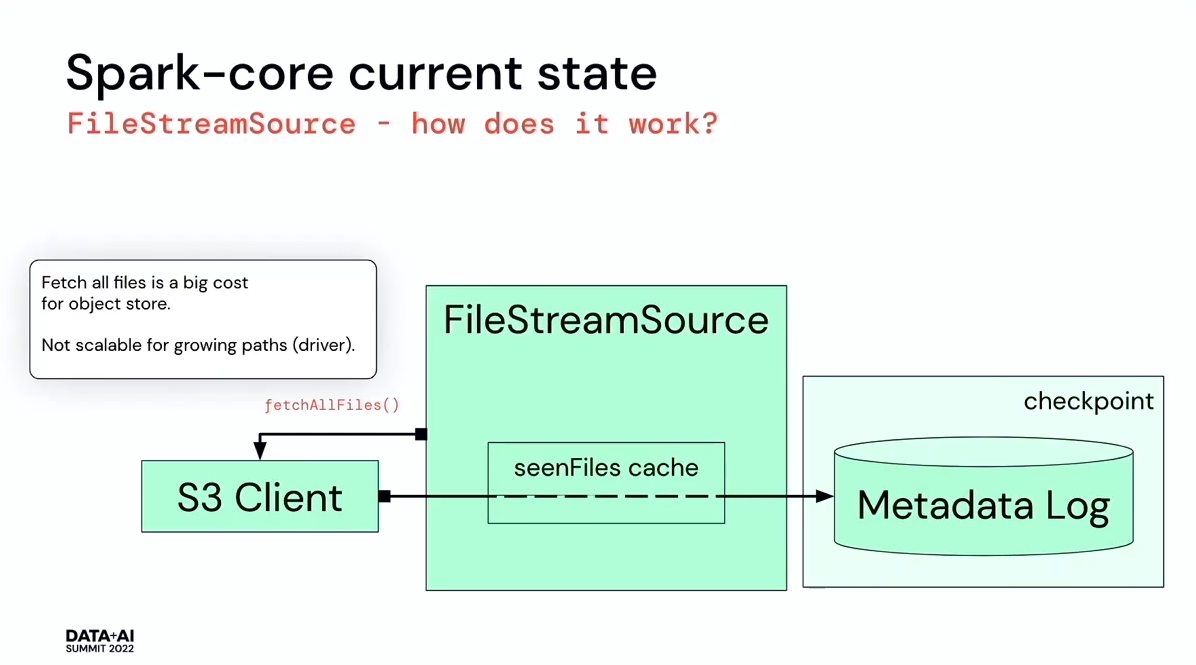
- If you have this problem too and fully control your infrastructure, you can read data directly from SQS notifications queue. Alternatively, you can also set a shorter retention for the objects but it must correspond to the global logic of data governance rather than to hotfix the listing problem.
- Ada and Wojciech created an Adaptive S3 Spark Connector that for streaming workloads can fetch only the most recent data. The data source decreased reading time from 24 hours for the whole day to 2 minutes for the previous day's data. The project is available on Github.
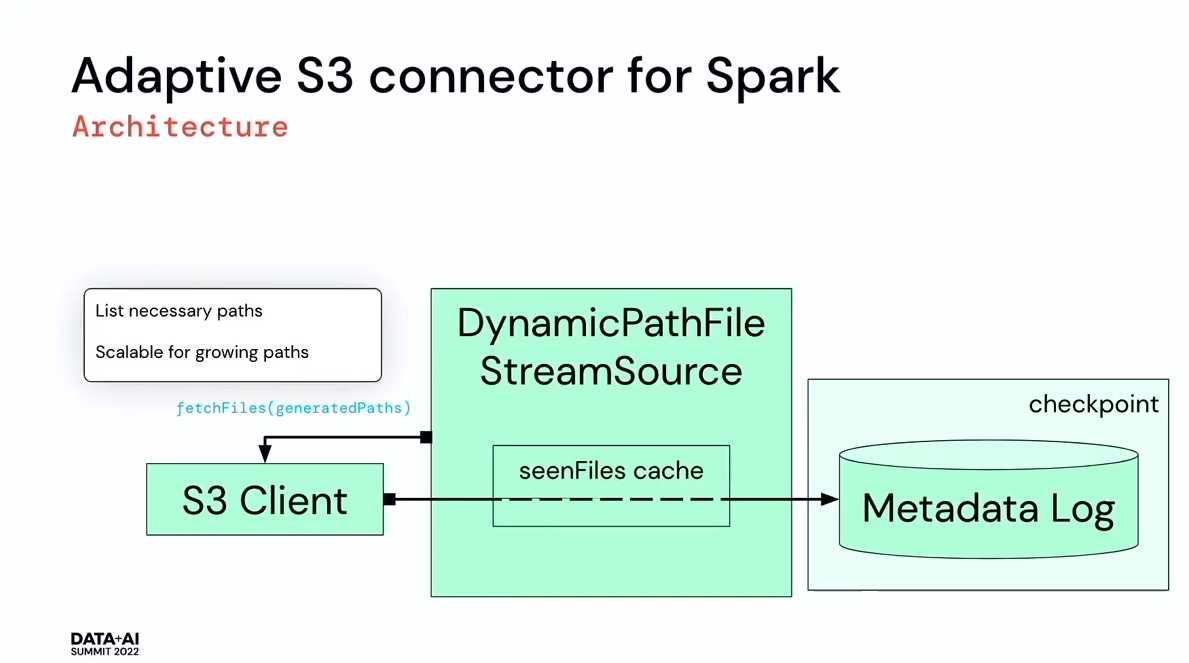
- The reason for a custom data source was slow objects listing in a huge bucket.
Delta Lake
- Interactive Analytics on a Massive Scale Using Delta Lake by Hagai Attias. In his talk, Hagai showed how to fine-tune Delta Lake for "a real-time, ad-hoc analytics over an extensive dataset". Some important points to remember from the talk are:
- spark.databricks.delta.optimizeWrite.enabled set to true. The feature enables faster writes despite an extra shuffle step and guarantees bigger files on the storage.
- Another observed issue was the metadata handling requiring reading all past metadata files. Setting the spark.databricks.delta.checkpoint.triggers.deltaFileThreshold helped reduce the checkpoints frequency and improve the micro-batches execution time. Databricks Runtime 11.1 brings incremental commits where the job doesn't need to look at everything that happened before.
- OPTIMIZE command works better without Z-Order. In that scenario, the compaction doesn't need to recompute z-cubes. Additionally, the data query patterns don't have a clear columns dominance and it was no reason to use Z-Order.
- CACHE SELECT prefetches some data to avoid reading it from the remote storage. The operation brings the data to the cluster and naturally, uses cluster resources. You should then use it wisely.
- Diving into Delta Lake 2.0 by Denny Lee and Tathagata Das. Open Sourcing all Delta Lake features was one of the most exciting keynote news during the Summit. Denny and Tathagata presented what you can get now and expect from the next 2.0 release:
- Three key stages of Delta Lake are 2017 (first Delta Lake usage at Apple), 2019 (Open Source version of Delta Lake announced, Databricks Delta was living aside with some extra features), and 2022 (Delta Lake fully Open Sources, including so far private features!).
- Data skipping via column stats. Better than using Apache Parquet metadata because the information lives in the commit log and doesn't even require reading their footer at all.
- Optimized ZOrder to improve data skipping with multi-column data clustering.

- Change Data Feed to implement the Change Data Capture pattern on top of Delta Lake. It's supported for both batch and streaming APIs.
- Column Mapping to get rid off of the strong coupling between Delta Lake schema (metadata) and Apache Parquet schema (storage). Previously it was impossible to rename a column without rewriting the existing files. Delta Lake 1.2 fixes that issue by adding a proxy translating metadata information to the physical storage layer.
- Concurrent writes supported on S3. Previously in case of concurrent writes on S3, the most recent writer won. Now, Delta Lake uses DynamoDB as an intermediary layer where the writers insert the commit version only if it doesn't exist. Otherwise, the write is detected as a conflict.
- New connectors. I bet you will recognize them in the slide below:

Of course, the sessions quoted here are only my "picks". Once again, I wish I could slow down the time to watch some extra talks. But as you know, I'm only a data engineer and don't know how to defy the laws of physics.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- DAIS 2024: Orchestrating and scoping assertions in Apache Spark Structured Streaming
- Data+AI Summit 2024 - Retrospective - Apache Spark
- DAIS 2024: Testing framework from the Dataflow model for Apache Spark Structured Streaming
- Data+AI Summit 2024 - Retrospective - Streaming
- Data+AI Summit 2023, retrospective part 2
Want to hear about Apache Spark, data engineering and Delta Lake from the last #DataAISummit ? I watched several talks on these topics, took some notes and shared them in the new blog post ? https://t.co/Biz4mB3xgw
— Bartosz Konieczny (@waitingforcode) July 17, 2022